






原文来源于:程序员成长指北;作者:一拾九
如有侵权,联系删除
前言
你是否有一个想法,自己设计一个网站,然后去爬取别人家页面的数据来做一个自己的网站。哈哈哈,如果自己写着玩可能没啥事,但如果用这个网站来获利,你可能就要被寄律师函了,毕竟这有点‘刑’。这篇文章呢,就带大家爬取豆瓣TOP250电影的信息。豆瓣电影 Top 250 \(douban.com\)[1]

1.png
准备工作
-
通过指令
npm init初始化文件夹,会获得package.json项目说明书。 -
爬虫必备工具:
cheerio;通过在终端输入npm i cheerio,即可将文件装到项目里。cheerio是jquery核心功能的一个快速灵活而又简洁的实现,主要是为了用在服务器端需要对DOM进行操作的地方。大家可以简单的理解为用来解析html非常方便的工具。
开始(细分七步)
-
用https模块(node直接提供给我们的)获取网站地址,通过get方法读取网站地址上的数据。
const https = require('https')
https.get('https://movie.douban.com/top250', function (res) {
let html = ''
res.on('data', function (chunk) {
//console.log(chunk + '');
//得到数据流,通过字符串拼接得到html结构
html += chunk
})
这样会读取到整个页面的html结构。
-
通过
res.on('end', function () {}),保证读取完了才会去做操作。 -
引入
cheerio
const cheerio = require('cheerio')
-
获取
html中的数据
const $ = cheerio.load(html)
$('li .item').each(function () {
const title = $('.title', this).text()
const star = $('.info .bd .rating_num', this).text()
const pic = $('.pic img', this).attr('src')
})
这里需要注意的是我们可以去页面上看我们需要拿到哪个类名里面的内容,通过$符号可以拿到内容。
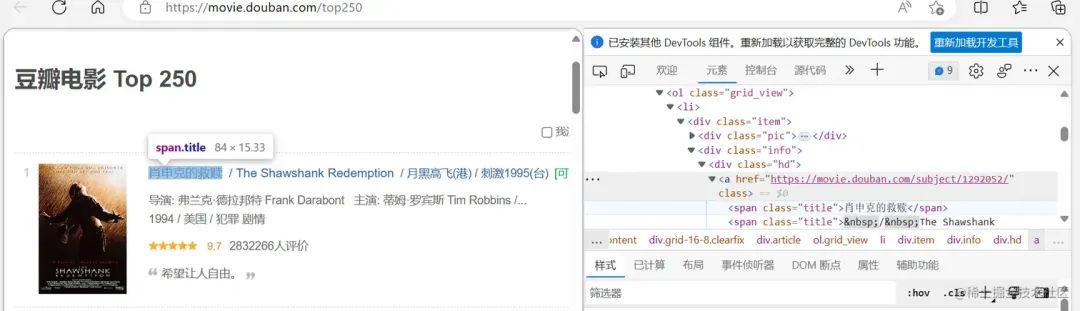
2.png
-
创建一个空数组,把数据以对象的形式存放在数组中
let allFiles = []
allFiles.push({
title: title,
star: star,
pic: pic
})
我们可以通过console.log(allFiles)来检查是否打印出来了我们需要的结果。
-
将数据写入文件,引用
node官方提供的模块fs
const fs = require('fs')
-
创建文件夹
files.json,向其中写入数据
fs.writeFile('./files.json', JSON.stringify(allFiles), function (err, data) {
if (err) {
throw err
}
console.log('文件保存成功');
})
到这之后,我们可以看到在当前文件夹下自动创建了文件files.json,里面已经有了我们想要的数据。
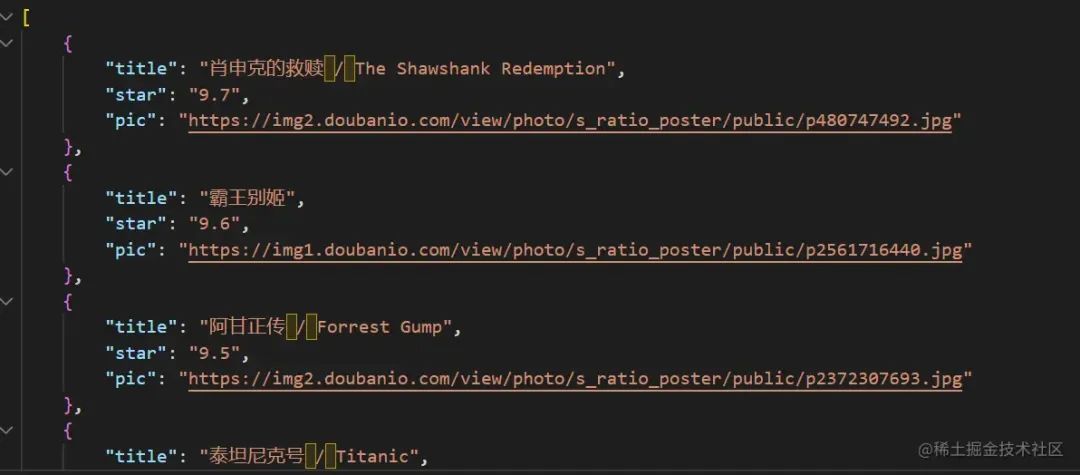
3.png
完整代码
//引入模块
const https = require('https')
const cheerio = require('cheerio')
const fs = require('fs')
//获取页面的html结构
https.get('https://movie.douban.com/top250', function (res) {
let html = ''
res.on('data', function (chunk) {
//console.log(chunk + '');
html += chunk
})
res.on('end', function () {
// 获取html中的数据
const $ = cheerio.load(html)
let allFiles = []
//拿到每一个item中我们需要的数据
$('li .item').each(function () {
const title = $('.title', this).text()
const star = $('.info .bd .rating_num', this).text()
const pic = $('.pic img', this).attr('src')
//数据以对象的形式存放在数组中
allFiles.push({
title: title,
star: star,
pic: pic
})
})
//console.log(allFiles);
//将数据写入文件中
fs.writeFile('./files.json', JSON.stringify(allFiles), function (err, data) {
if (err) {
throw err
}
console.log('文件保存成功');
})
})
})
结语
到这里你会发现node的爬虫写起来不是很难的,作为一名前端新手我们应该知道node它是非常强大的,它能读得懂js可以用来做后端开发。本文的实现是爬取一些简单的数据,是一个入门,希望对未来学习node有帮助。
参考资料
[1] https://movie.douban.com/top250















 227
227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









