







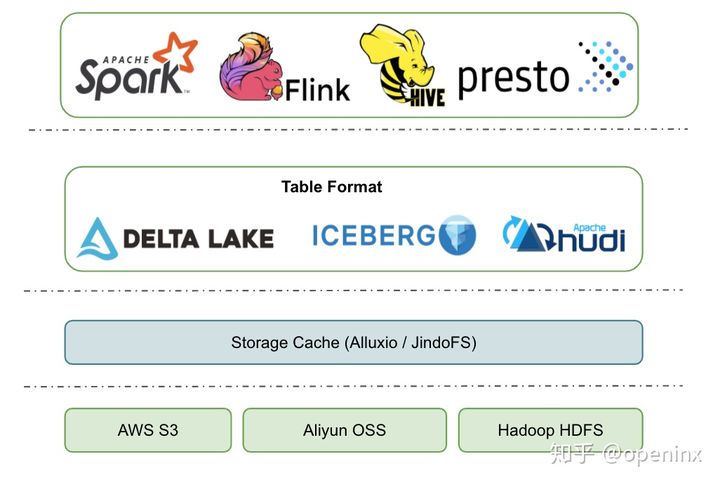
- 最上层就是不同计算场景的计算引擎了。开源的一般有spark、flink、hive、presto、hive MR等,这一批计算引擎是可以同时访问同一张数据湖的表的。
经典业务场景介绍
那么,Flink和数据湖结合可以有哪些经典的应用场景呢?(这里我们探讨业务场景时默认选型了Apache Iceberg来作为我们的数据湖选型,后面一节会详细阐述选型背后的理由)
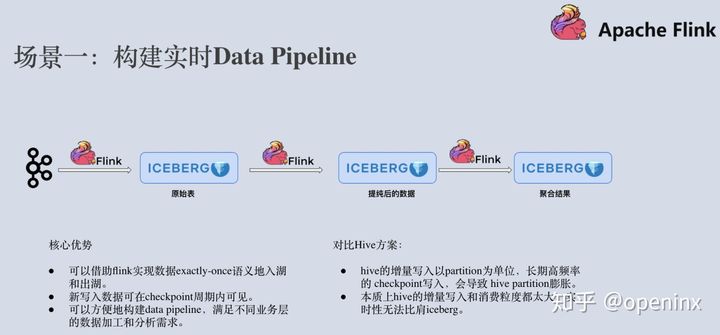
首先,flink+iceberg最经典的一个场景就是构建实时的Data Pipeline。业务端产生的大量日志数据,被导入到Kafka这样的消息队列。运用Flink流计算引擎执行ETL后,导入到Apache Iceberg原始表中。有一些业务场景需要直接跑分析作业来分析原始表的数据,而另外一些业务需要对数据做进一步的提纯。那么我们可以再新起一个Flink作业从Apache Iceberg表中消费增量数据,经过处理之后写入到提纯之后的Iceberg表中。此时,可能还有业务需要对数据做进一步的聚合,那么我们继续在iceberg表上启动增量flink作业,将聚合之后的数据结果写入到聚合表中。
有人会想,这个场景好像通过flink+hive也能实现。flink+hive的确可以实现,但写入到hive的数据更多地是为了实现数仓的数据分析,而不是为了做增量拉取。一般来说,hive的增量写入以partition为单位,时间是15min以上,flink长期高频率地写入会造成partition膨胀。而iceberg容许实现1分钟甚至30秒的增量写入,这样就可以大大提高了端到端数据的实时性,上层的分析作业可以看到更新的数据,下游的增量作业可以读取到更新的数据。
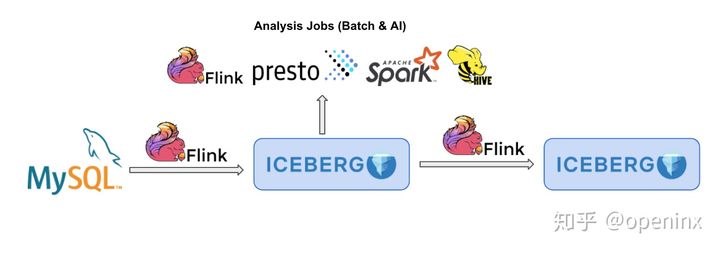
第二个经典的场景,就是可以用flink+iceberg来分析来自MySQL等关系型数据库的binlog等。一方面,Apache Flink已经原生地支持cdc数据解析,一条binlog数据通过ververica flink-cdc-connector 拉取之后,自动转换成flink runtime能识别的INSERT、DELETE、UPDATE_BEFORE、UPDATE_AFTER四种消息,供用户做进一步的实时计算;另外一方面,Apache Iceberg已经较为完善地实现了equality delete功能,也就是用户定义好待删除的record,直接写到apache iceberg表内就可以删除对应的行,本身就是为了实现数据湖的流式删除。在Iceberg未来的版本中,用户将不需要设计任何额外的业务字段,不用写几行代码就可以完成binlog流式入湖到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4486
4486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









