






1. 导入资源包
资源包:
import torchvision:PyTorch 提供的视觉库,包含了常用的计算机视觉模型架构、数据集以及图像转换工具。
from torchvision import datasets, models:导入 torchvision 中的 datasets 和 models 模块,用于加载常用的数据集和模型。
import subprocess:用于调用系统子进程执行命令。
from tkinter import filedialog:导入 tkinter 模块,用于创建 GUI 界面、文件对话框和消息框等用户交互组件。
import torch
import numpy as np
from torchvision import datasets, models
import torch.nn as nn
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import os
import tkinter as tk
from tkinter import filedialog
import cv2
import subprocess
from PIL import Image, ImageTk
from PIL.Image import Resampling
注:这段代码主要是结合 PyTorch 和 tkinter 构建了一个图像处理应用程序,通过 tkinter 提供的界面与用户进行交互,然后利用 PyTorch 和 OpenCV 进行图像处理和深度学习任务。
2. 设置数据目录和模型目录
注:这两个路径变量是用来指定数据集和模型文件的存储路径,以便程序能够方便地访问数据和载入模型进行相关的深度学习任务。
# 设置数据目录和模型路径
data_dir = 'C:/Users/HUAWEI/PycharmProjects/pythonProject1/二分类/data'
model_path = 'cat_dog_classifier.pth'
3. 定义图像转换
# 定义图像转换
data_transforms = {
'test': transforms.Compose([
transforms.Resize(size=224),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
注:在这段代码中,作者定义了一个名为 data_transforms 的字典,其中包含了针对测试数据的图像转换操作。这些图像转换操作通常用于将原始图像数据转换为神经网络模型可接受的格式,同时进行一定的预处理以提高模型性能,通过这些图像转换操作,测试数据在输入神经网络之前会被经过一系列的预处理操作,以便更好地适应神经网络的训练和推断需求,同时有助于提高模型的性能和收敛速度。
3. 使用GPU
# 使用GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
注:torch.cuda.is_available():这是 PyTorch 提供的函数,用于检测当前系统是否支持 CUDA,即是否有可用的 GPU 资源,通过这段代码,作者实现了将模型加载到 GPU 上进行计算的逻辑,这样可以利用 GPU 的并行计算能力加速深度学习任务的执行速度。如果系统支持 CUDA,模型将在 GPU 上执行,否则将在 CPU 上执行。
4. 加载没有预训练权重的ResNet模型
# 加载没有预训练权重的ResNet模型
model = models.resnet50(weights=None) # 使用pretrained=False
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 2)
model.load_state_dict(torch.load(model_path))
model = model.to(device)
model.eval()
注:加载了一个不带预训练权重的 ResNet-50 模型,并对其进行了适应二分类任务的定制化处理,以便进行后续训练或推理操作。
5. 创建Tkinter窗口
# 创建Tkinter窗口
root = tk.Tk()
root.title('猫狗识别')
root.geometry('800x650')
image = Image.open("图像识别背景.gif")
image = image.resize((800, 650)) # 调整背景图片大小
photo1 = ImageTk.PhotoImage(image)
canvas = tk.Label(root, image=photo1)
canvas.pack()
注:通过这段代码,成功地创建了一个带有背景图片的 Tkinter 窗口,为用户提供一个可视化的界面,用于展示猫狗识别的功能。
6. 添加文本标签来显示识别结果
# 添加文本标签来显示识别结果
result_label = tk.Label(root, text="", font=('Helvetica', 18))
result_label.place(x=280, y=450)
注:通过这段代码,我们在 Tkinter 窗口中成功添加了一个用于显示识别结果的文本标签,方便用户在界面上查看猫狗识别的结果。
7. 保存用户选择的图片路径
selected_image_path = None
注:这行代码定义了一个变量 selected_image_path,并将其初始化为 None。通常情况下,这样的操作用于在程序中声明一个变量,但暂时不对其进行赋值。在后续的代码中,可以根据实际需要来更新 selected_image_path 的取值,以存储用户选择的图像文件路径。
8. 加载测试数据集
# 加载测试数据集
image_datasets = {x: datasets.ImageFolder(root=os.path.join(data_dir, x),
transform=data_transforms[x])
for x in ['test']}
dataloaders = {x: DataLoader(image_datasets[x], batch_size=1, shuffle=False)
for x in ['test']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['test']}
class_names = image_datasets['test'].classes # 定义class_names
注:通过这段代码,我们成功加载了测试数据集,并准备好了对测试数据进行预测和评估所需的数据结构,为模型的测试和评估提供了基础。
9. 加载Haar特征级联分类器
# 加载Haar特征级联分类器
cat_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalcatface.xml')
dog_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_alt2.xml')
注:
haarcascade_frontalcatface.xml 是用于检测猫脸分类器文件。
haarcascade_frontalface_alt2.xml 是用于检测狗脸分类器文件。
通过以上代码,我们成功加载了用于检测猫和狗脸部的 Haar 特征级联分类器,这些分类器可以用于后续对图像中的猫和狗进行脸部检测。
10. 定义一个函数来打开文件选择对话框并显示图片
# 定义一个函数来打开文件选择对话框并显示图片
def choose_image():
global selected_image_path
file_path = filedialog.askopenfilename(initialdir=data_dir, title="选择图片",
filetypes=(("图片文件", "*.png *.jpg *.jpeg *.gif *.bmp"), ("所有文件", "*.*")))
if file_path:
selected_image_path = file_path
img = Image.open(file_path)
mg = img.resize((400, 350), Resampling.LANCZOS)
imgTk = ImageTk.PhotoImage(img)
image_label.config(image=imgTk)
image_label.image = imgTk
注:这段代码定义了一个函数 choose_image(),其作用是打开一个文件选择对话框,允许用户选择图片文件,并在程序中显示所选图片。
11. 定义一个函数来使用模型进行预测
# 定义一个函数来使用模型进行预测
def predict_image():
global selected_image_path
if selected_image_path:
img = Image.open(selected_image_path)
transform = data_transforms['test']
img_tensor = transform(img).unsqueeze(0).to(device)
with torch.no_grad():
outputs = model(img_tensor)
_, preds = torch.max(outputs, 1)
prediction = class_names[preds.item()] # 使用str()来将整数转换为字符串
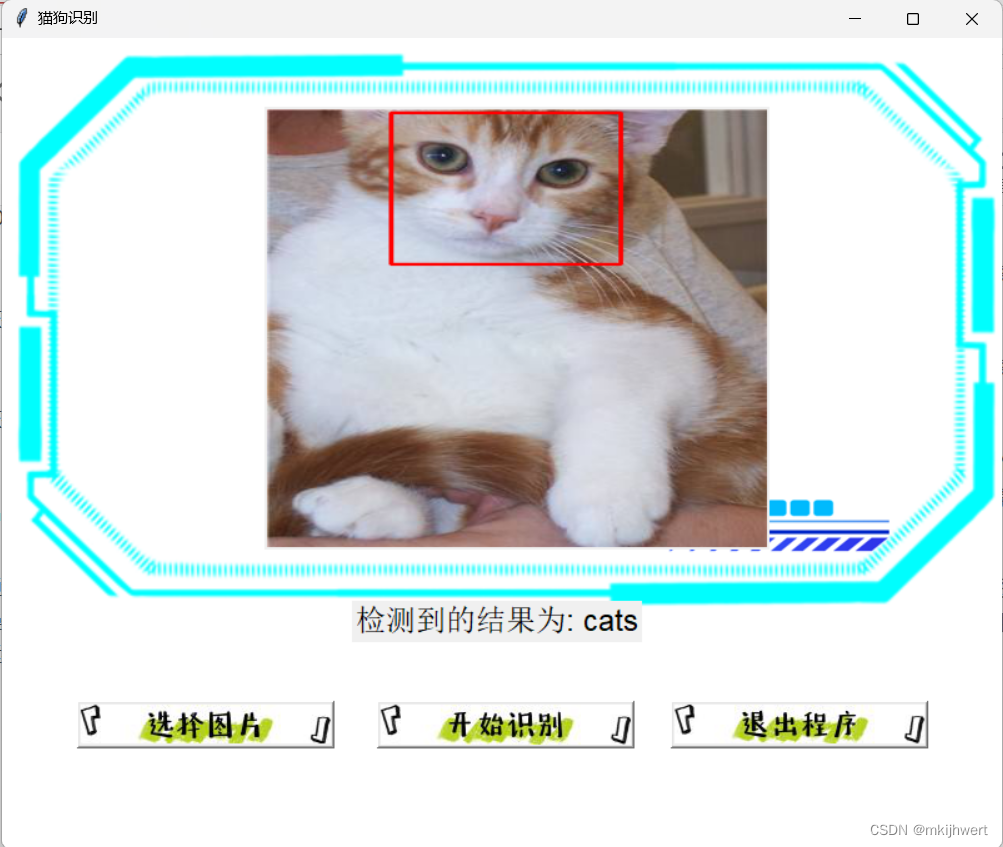
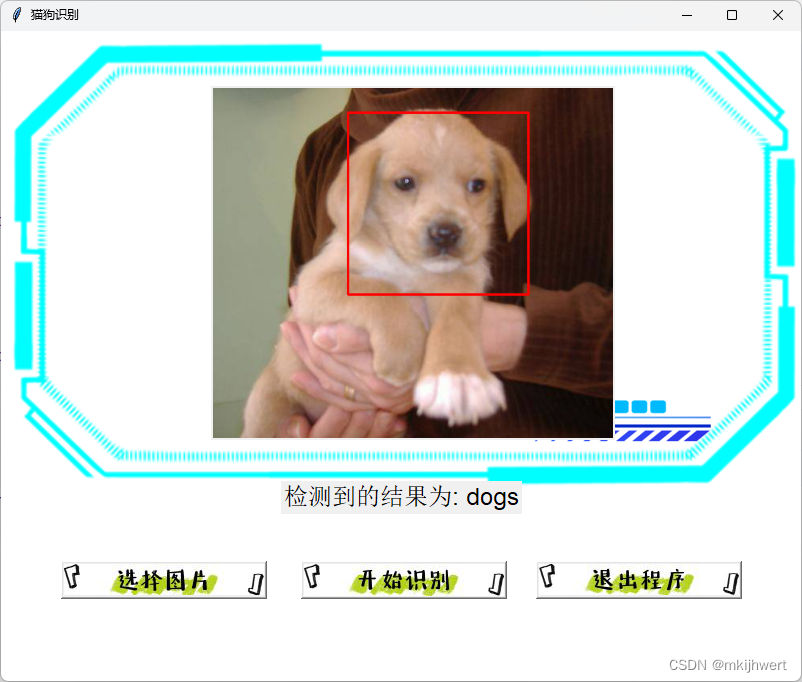
result_label.config(text=f"检测到的结果为: {prediction}")
# 使用OpenCV在原始图像上绘制矩形框
img_cv2 = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
if prediction == 'cats':
cats = cat_cascade.detectMultiScale(img_cv2, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
for (x, y, w, h) in cats:
cv2.rectangle(img_cv2, (x, y), (x + w, y + h), (0, 0, 255), 2) # 红色矩形框
if len(cats) > 0:
cv2.imwrite("detected_cats_image.jpg", img_cv2) # 保存带有猫矩形框的图像
img_detected_cats = Image.open("detected_cats_image.jpg").resize((350, 300), Resampling.LANCZOS)
imgTk_detected_cats = ImageTk.PhotoImage(img_detected_cats)
image_label.config(image=imgTk_detected_cats)
image_label.image = imgTk_detected_cats
elif prediction == 'dogs':
dogs = dog_cascade.detectMultiScale(img_cv2, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
for (x, y, w, h) in dogs:
cv2.rectangle(img_cv2, (x, y), (x + w, y + h), (0, 0, 255), 2) # 红色矩形框
if len(dogs) > 0:
cv2.imwrite("detected_dogs_image.jpg", img_cv2) # 保存带有狗矩形框的图像
img_detected_dogs = Image.open("detected_dogs_image.jpg").resize((350, 300), Resampling.LANCZOS)
imgTk_detected_dogs = ImageTk.PhotoImage(img_detected_dogs)
image_label.config(image=imgTk_detected_dogs)
image_label.image = imgTk_detected_dogs
else:
print("未检测到猫或狗。")
# 显示修改后的图像
img = cv2.cvtColor(img_cv2, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (400, 350))
imgTk = ImageTk.PhotoImage(image=Image.fromarray(img))
image_label.config(image=imgTk)
image_label.image = imgTk
else:
print("请先选择一张图片。")
注:这段代码定义了一个名为 predict_image() 的函数,在选定的图片上使用模型进行预测,并在图像上标记检测结果(猫或狗),然后在界面中显示带有标记的图像。以下是函数的主要逻辑解释:
-
global selected_image_path:声明 selected_image_path 是全局变量,以便在函数内部访问所选图片路径。
-
检查是否已选择了图片路径,若选择了,则执行以下操作:
-
从选定图片路径加载图像,并应用与训练时相同的测试数据转换。
-
使用模型进行图像预测,得到预测类别和相应得分。
-
根据预测类别在图像上绘制矩形框,标记检测结果,并在图像上显示矩形框。
-
如果检测到猫,将在图像上绘制红色矩形框并保存带有猫矩形框的图像,并在界面中显示标记的图像。
-
如果检测到狗,将在图像上绘制红色矩形框并保存带有狗矩形框的图像,并在界面中显示标记的图像。
-
如果未检测到猫或狗,输出相应信息。
-
将绘制了矩形框后的图像转换为适合界面展示的格式,并在界面中显示。
-
若未选择图片路径,则输出提示信息。
通过这个函数,用户可以在界面中选择图片并进行猫狗识别的预测,并显示标记了检测结果的图片,提高了用户体验和结果可视化。
12. 退出程序的函数
# 退出程序的函数
def close():
subprocess.Popen(["python","主页面.py"])
root.destroy()
注:通过这个函数,当用户希望退出当前程序时,会打开一个新的 Python 进程并运行名为 “主页面.py” 的文件,同时关闭当前程序界面,实现了程序的退出操作。
13. 创建按钮
# 创建按钮
image = Image.open("选择图片.gif") # 加载一张图片
photo2 = ImageTk.PhotoImage(image)
bt1 = tk.Button(root, image=photo2, width=200, height=32, command=choose_image)
bt1.place(x=60, y=530)
image = Image.open("开始识别.gif") # 加载一张图片
photo3 = ImageTk.PhotoImage(image)
bt1 = tk.Button(root, image=photo3, width=200, height=32, command=predict_image)
bt1.place(x=300, y=530)
image = Image.open("C:/Users/HUAWEI/Desktop/aa/aa/退出程序.gif") # 加载一张图片
photo4 = ImageTk.PhotoImage(image)
bt1 = tk.Button(root, image=photo4, width=200, height=32, command=close)
bt1.place(x=535, y=530)
# 运行Tkinter事件循环
root.mainloop()
注:这段代码定义了三个按钮,每个按钮都使用了一张图片作为其显示内容,并指定了当按钮被点击时执行相应的函数。以下是代码的主要逻辑解释:
-
image = Image.open(“选择图片.gif”):打开一张名为 “选择图片.gif” 的图片。
-
photo2 = ImageTk.PhotoImage(image):将 PIL 库中的 Image 对象转换为 Tkinter 库中可用的图像对象。
-
bt1 = tk.Button(root, image=photo2, width=200, height=32, command=choose_image):创建一个按钮,其图片是 photo2,宽度为 200,高度为 32,当按钮被点击时执行 choose_image 函数。
-
bt1.place(x=60, y=530):设置按钮在窗口中的位置,x 坐标为 60,y 坐标为 530。
-
对于第二个按钮,重复上述步骤,但使用不同的图片和函数,该按钮位于 x 坐标 300,y 坐标 530。
-
对于第三个按钮,重复上述步骤,但使用不同的图片和函数,该按钮位于 x 坐标 535,y 坐标 530。
-
root.mainloop():启动 Tkinter 事件循环,使得窗口能够响应用户的交互,如点击按钮等。
通过这些按钮,用户可以执行选择图片、进行预测和退出程序的操作,这些操作通过点击按钮触发相应的函数来执行。
运行结果:















 3172
3172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









