






这一次的AIGC+浪潮已经从最开始的AI绘画转变到了AI视频,从去年开始就不断的出现各种各样的AI视频工具。这些工具里面最常见的要属于文生视频+工具,这些狭义的AI视频,但是广义上来讲任何使用AI技术用来制作的视频都可以算作AI视频。最近一两年得益于AIGC技术的不断成熟,文生图、大语言模型,AI语音生成和数字人技术的不断进展。现在这个阶段AI的视频工具流终于可以实现了。
AIGC视频大爆发,大家真正要的是什么?
目前最火的也是产品最多的AI视频工具莫非是文生视频了,从最开始的Runway+到pikat,再到现在新起的AI视频工具大部分都是这个类别,当然大家很期待但是用不上的sora+也是这个类别。这类2D的文生视频工具可以让一个短片的制作流程非常便捷快速,但是它存在很多问题。
文生2D视频目前商业化的难点,可控性差以及无法修改和编辑
我们可以在短视频平台看到很多华丽的AI视频的作品,目前文生视频大部分的工作流程是先用文生图来制作分镜,然后再用这些分镜生成4s左右的片段,然后用剪辑工具来把这些片段剪辑到一起。这些片段的生成时长大部分都不超过4s,如果超过就会存在很严重的变形。文生视频目前的视频大模型对提示词的语义理解也很局限,这也是大家为什么都是用图片来生成的原因。大部分好的效果是通过大量抽卡随机生成的,基本还轮不到提示词工程。这种创作方式可控性极差,以至于被形容成抽卡式创作,而大部分的作品很难实现连贯的大动作,所以片子会很像有一点动画的PPT作品。
sora才推出,需要消耗大量的算力资源,存在费用问题
但是你要说了,sora不这样啊sora多么牛逼,时长超过1分钟,然后人物动作逼真连贯,语义理解也很到位。是的没错,根据目前openai放出的demo来看,sora是现在最优秀的文生视频大模型。唯一的缺点是,几乎没人有资格用。openai号称sora已经可以模拟物理规则了,从已经公布的资料可以推断,一方面是伦理原因,但是更大的一方面可能是算力问题,sora也同样是大力出奇迹的典范,需要消耗大量的算力。视频类产品消耗的算力是图片类产品的数十倍,sora这种效果好的就更多了。这种情况下,sora的价格是否可以达到一个可商用的位置是个悬念。毕竟大部分的老板们追捧AIGC是为了给他们降本增效的,不是为了破产的。而即使是sora这么优秀的语义理解,仍然存在生成的视频无法修改和编辑的问题。
昙花一现的wandert,3D视频角色产品,应用面太窄。
曾经在之前出现过一款叫wander的AI视频产品,可以直接替换视频中的人物。这款产品的逻辑跟目前的文生视频很不一样,它是直接根据视频来给里面的人物建模,然后使用其它的3D模型来替换里面的人物。它生成的视频可以把新的人物很好的融入到现实场景中去。但是这款产品一直都不温不火,用的人也非常的少。究其原因可能是它的局限性太大,只能支持人物替换,并且如果要使用自己的模型需要严格的按照它们的规范来进行命名和标注。模型也只支持硬表面的模型对于流体面料完全不支持。
你为什么要做AI视频?玩具or生产力工具?
你为什么要做AI视频?这个问题是值得所有的AI视频创作者和创业公司思考的。因为目前我看到的市面上大部分的AI视频工具都还不能称之为生产力工具,更像是一个新奇的玩具。
商业视频需要非常高的可控性
无论是商业广告视频,还是口播带货视频,还是影视短片,你随机抓个从业者问问都会告诉你整个工作流充斥着大量的沟通与修改。而现在的文生视频根本不具备编辑和修改的技术能力。这一年大家可以看到很多的商业宣传片用文生视频做的,怎么到了AI视频就突然不需要编辑和反复修改了呢?那是因为现阶段的AI视频更多的是在利用它营销的属性,而不是工具的属性。商家需要让大众看到自己站在了科技的最前沿,需要让大家看出这是用AIGC做的,至于它做的有多好到不是最需要考量的因素。但是随着越来越多的此类视频的发布,营销属性会逐渐丧失,再往后呢?大家就不得不面对A!视频真实的工具能力。而作为一个合格的生产力工具可控性是最大的考量因素没有之一
AI绘画的可控性来自controlnet,可控性才能带来真实的落地应用
同样的可控性问题之前就在AI绘画中出现过,在controinet这个技术出现之前,虽然midjourney已经可以生成十分华丽的图像,但是大家仍然只是把它当成一个玩具而不是生产力工具。controlnet出现之后真正的落地应用才开始出现,AI绘画才逐渐结合电商,摄影,建筑等诸多细分的行业和领域。这个我作为设计感受尤其强烈,你需要生成一张图,如果无法控制里面的元素,内容,构图配色那么就无法形成一个稳定成熟的工作流。
大家要的不是随机的视频片段,而是可以解决需求的视频工作流
现在的A视频就站在了急需可控性工作流的阶段了。我们用AI生成一堆随机的视频片段在商业上的价值并不是很大,PPT式AI视频大家很快就会厌倦。下一个阶段一定是系统的把AIGC的技术结合在传统的视频工作流之中,满足一些真正细分场景的应用需求,这个才是未来AI视频的发展路径。
AI视频的拼图已经基本形成
虽然现阶段的文生2D视频技术尚有发展空间,但是组成一个视频需要的元素:脚本,人物,分镜,语音,配乐。这些都开始有对应的AIGC技术出现,比如脚本有大语言模型GPT,人物可以用文生图,语音相关的TTS也基本成型,音乐有最近大火的suno。每一个技术分支目前都有相关的AIGC技术出现。所以现在需要的是一个能够一站式生成视频的工作流产品,比如现在如果我要制作一个AI视频,可能需要结合GPT,RUNWAY,SUNO,剪映等好几个产品才能实现,这并不合理,真正的AI视频工具应该是能够一站式解决所有需求的。这类产品不多但是我最近也找到了一个,是一款叫有言的AI视频创作平台。我接下来会用它来举例AIGC的技术如何融入到视频工作流之中。
视频脚本
过去专业文案编导的这部分工具已经可以使用大语言模型生成了,但是通用型的大语言模型对于普通用户并不友好。比如我要写一个脚本,但是并没有相关的经验,我是不知道如何让GPT生成我想要的内容的。这一点在有言上做的很好,它已经把常见的视频脚本结构化了,用户只需要选择一些既定的选项就可以得到一个相对规范的内容脚本。
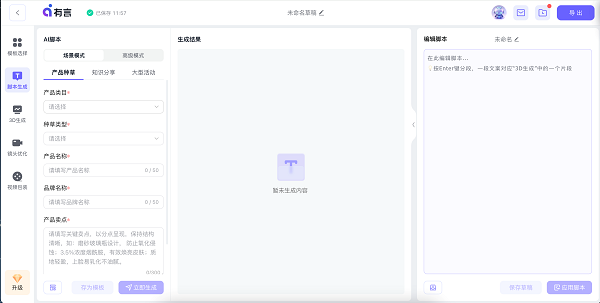
视频脚本这里的文本字数也很贴心,虽然是个很小的功能但是对我来说十分的重要,过去写完脚本预估时长只能根据经验。

以冰岛为例的脚本生成。
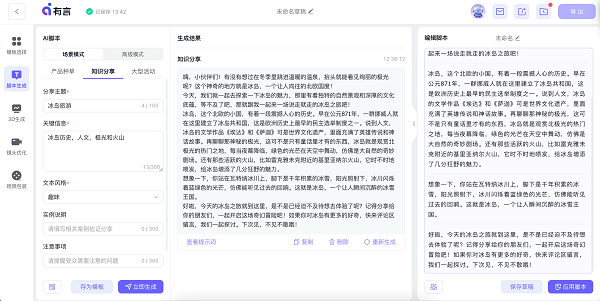
3D数字人视频生成
目前市面上的数字人主要有三种,一是2D数字人大部分只能有面部口型动作,还有的就是3D数字人这是有言的产品方向,最后是相对传统的拍摄真人视频来制作相关的数字人。2D的数字人动作非常僵硬,并且无法有肢体动作,真实人物制作数字人可能会有肖像权等法律风险,目前的法规还不够完善,并且肢体动作也比较有限无法编辑。这可能是有言选择3D数字人的原因。
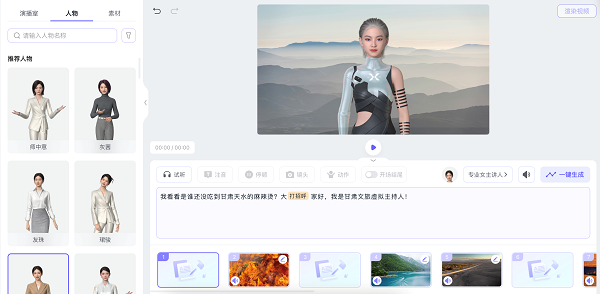
有言的3D视频生成主要覆盖的是演播类的应用场景,需要一个主持人和口播类的视频,他们把这类视频的流程拆分的非常细致。大致分为场景和人物,其中环境场景可以自定义运镜,人物部分也可以设置镜头和人物动作,这就覆盖了大部分的企业产品宣传类的商业视频,并且人物动作的可编辑让视频会更加的自然和逼真。
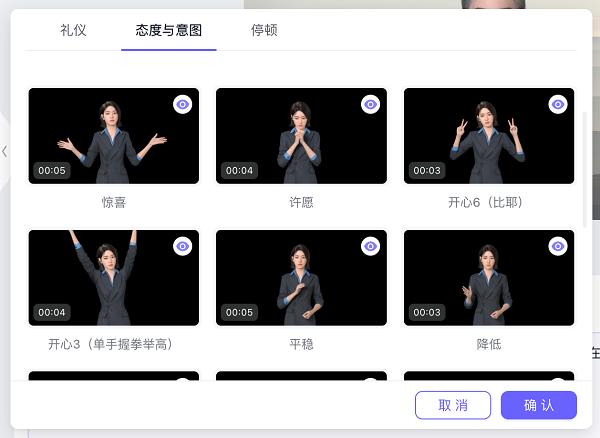
可以通过选择文本内容来设置对应的人物动作和镜头。编辑页面的最下面是一系列场景,这些场景可以选择自带的模板,也可以选择自己上传的素材,这里的便捷性也是很不错,目前这部分大部分都是需要使用专业的剪辑工具添加,这里直接一站式解决了。3D数字人还有一个最大的好处是不太受视频时长的限制,也没有质量方面的问题。
我这里把2D的AI数字人的特点和有言的3D数字人做了一下对比:分为以下几个方向进行分析
视频人物动作和表情口型匹配
人物口型匹配只支持正面,并且无法匹配相对应的动作。Runway也在他们的视频生成里添加了2D数字人的口型匹配,但是目前都还是只支持正面的肖像,人物的角度或者面部比例一旦低于一定程度就无法生成,而且只支持面部的动态,身体动作是没有任何一个产品支持的。并且生成的时长有限制并且很贵,因为这些都需要消耗大量的算力。生成的视频是一次性的,不支持任何形式的修改,如果需要改动里面的内容,就只能重新生成。
而3D数字人视频这些都没有问题。有言的数字人可以设置场景内容人物动作的多重修改,也没有时长的限制。在生成的费用上也低廉很多,文生视频有一个非常隐蔽的消费点,就是虽然看起来是按时长收费,但是实际上你要得到你想要的视频片段因为可控性很差,都是需要大量抽卡才有希望获得,这就给费用造成的很大的不可预估性,每个视频都需要大量的试错成本和时间成本。
视频的运镜效果
runway有丰富的运镜功能,但是这种运镜幅度一旦变大就会变形。除了变形,视频的清晰度和流畅程度也是一个很大的问题。2D视频生成的运镜跟2D数字人是分离的,很难合成在一个场景,只能通过剪辑拼起来。
但是如果用3D视频生成,比如下图的有言生成的演播讲解视频,每个镜头的运镜都是可以修改的并且运镜的类别分的十分详细,这就给后期的优化调整提供了可能。
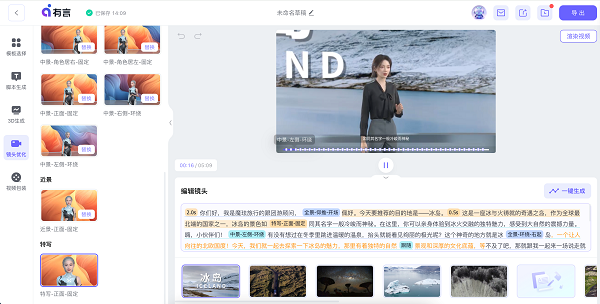
视频的编辑和可控性
几乎没有编辑的功能,可控性目前最先进的就是runway的多重运动笔刷,但是出来的效果也具有-定的随机性。在可控性差的大前提下,AI视频的一致性问题就会特别凸显,目前的解决方案也是通过AI绘画先生成一致性的图片,再用图片来生成视频,而不是直接生成视频。但是即便是如此生成后的视频也无法修改和编辑。
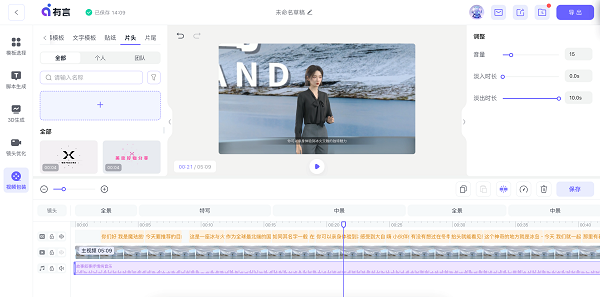
3D的有言很好的规避了这个问题。人物的镜头远近角度,人物的台词内容,画面的场景和运镜都可以任意修改。
有言最终的成片效果,我拿冰岛旅行做了一个demo测试,后期的视频包装上添加了背景音乐,如果想要做更复杂的视频后期包装他们也同样支持视频的片头片尾音效和字幕等。这些之前都需要专业的剪辑工具才可以完成,现在在一个工具上就可以实现,能够在一个工具上生成可商用成品的产品一定是未来的趋势。
AIGC视频的未来:2D还是3D?
在AI绘画的可控性(controlnet)出现之前AI绘画只是个新奇的玩具。这个对于AI视频也是如此。现在AI视频的3个方向:风格迁移,文生2D视频,2D唇形匹配,在视频的工业生产上还存在非常多的问题,最关键的问题在于几乎没有可控性以及后期编辑的可能。所以,真正可行的路径可能不是一键生成你想要的视频,而是把诸多技术很好的整合在一起。也就是目前有言在走的路径,一站式AI视频生成工具。
有言很不一样的选择了3D,这个跟大部分现有的AI视频生成公司都不一样,我关注了2D视频生成这么长时间,确实也没有看到大的技术图片(sora除外),目前的工具离商业应用差距还是挺大的。这些AI视频的产品如何才能更好的生存下去,而不是阶段性的热点,需要产品能解决真实的商业需求。在这点上有言做的特别好,在大部分AI视频产品没有一个明确的用户画像的时候,有言的产品每个细节都在从商业应用反推和设计功能点。这就屏蔽了大部分没有可持续付费意愿的用户,只有需求明确且真实,一个产品才有真正的立足点,而不是只面向投资人的PPT产品。
3D比2D具有更多的可控性
比如人物动作和运镜都可以更好的编辑和控制。这个方面真的很棒,不过自带数字人模板在自定义人物独特性上差一些,这点后期应该可以通过AI换脸的方式来实现个性化。
物理世界的模拟3D会处理的更好
SORA已经是文生视频的极限了,虽然它号称可以模拟物理规则,但是仍然会存在一定程度的错误,并且成品视频无法修改和编辑。在细分领域,用3D构建好模版是更简单的解决方案。
元宇宙和XR技术依赖于3D
苹果Vision Pro的发布让大家重新看到了元宇宙和XR技术的前景,但是这一切都建立在3D的基础之上。2D的生成在XR领域应用会很局限。而3D的产品可以添加更多更丰富的交互性,如果生成的视频技术是以3D为基础的,那么未来等到XR技术成熟,人手一个XR眼镜就可以真正的一键实现身临其境的云发布会了。这些都是2D的视频生成无法做到的。
苹果Vision Pro的发布让大家重新看到了元宇宙和XR技术的前景,但是这一切都建立在3D的基础之上。2D的生成在XR领域应用会很局限。而3D的产品可以添加更多更丰富的交互性,如果生成的视频技术是以3D为基础的,那么未来等到XR技术成熟,人手一个XR眼镜就可以真正的一键实现身临其境的云发布会了。这些都是2D的视频生成无法做到的。
所以,大概总结一下。3D的视频生成可能是解决视频可控性的一条很好的路径。能够很好的整合现有AIGC技术的产品才是大家最终需要的产品形式,我们要的是工作流而不是技术碎片。从已有的商业落地需求去设计产品,才有可能在未来潮水退去后活下来。有言这种一站式生成3D视频的产品是个很好的思路,尤其是在未来大概率XR技术成熟的预期下,我们将会看到一些AIGC跟XR结合的产品应用,这些都需要建立在3D的前提下。而对于大部分有实际商业需求的用户,能够一站式解决问题可以节约大量的成本,这个成本包括不同工具的学习成本和工具的会员购买,这都是很现实的需求。而有言恰恰就是满足了这部分的核心需求

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









