







Requests库的两个重要对象:Request(请求) 和 Response(接收)
Response对象包含服务器返回的所有信息,也包含请求的Request信息
Response对象的属性

理解requests编码:

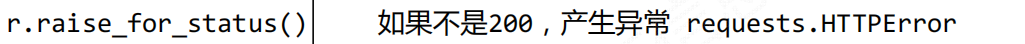
r.raise_for_status()在方法内部判断r.status_code是否等于200,不需要
增加额外的if语句,该语句便于利用try‐except进行异常处理
import requests #导入requests库
def getHTMLtext(url):
try:
r = requests.get(url,timeout=20)
r.raise_for_status() #通用框架,获取状态码,如果是200正常,如果不是就会抛出一个异常,我们的try except 用来捕获异常。
r.encoding = r.apparent_encoding #用根据内容猜测编码来替代根据头获取编码
return r.text #打印获取
except:
return “有异常产生”
#通过函数调用即可
if name == “main”:
url=“ttp://www.baidu.com”
print(getHTMLtext(url))
可以有效的处理爬取过程中可能出现的错误网络不稳定等等
稳定,可靠

url正常

我们给一个错误的url,让它出错

这是就会给我们提示异常,我们自己找解决就OK。



HTTP,Hypertext Transfer Protocol,超文本传输协议,是一个基于“请求与响应”模式的、无状态的应用层协议
HTTP协议采用URL作为定位网络资源的标识,URL格式如下:
http://host[:port][path]
host: 合法的Internet主机域名或者是IP地址
port: 端口号
path: 请求资源的路径
HTTP URL的理解:
URL是通过HTTP协议存取资源的Internet路径,一个URL对应一个数据资源
HTTP协议对资源的操作

通过URL和命令管理资源,操作独立无状态,网络通道及服务器成为了黑盒子

HTTP协议和Requests库是一致的

Requests库的head()方法
import requests
r = requests.head(“https://www.kuangstudy.com/course?cid=1”)
r.encoding=r.apparent_encoding
print(r.headers)

Requests库的post方法
post字典
import requests
payload={‘a’:‘A’,‘b’:‘B’}
r = requests.post(“https://www.kuangstudy.com/course?cid=1”,data=payload)
a=r.status_code
print(a)
print(r.text)

哈哈,没有成功,不过没有关系,这是小狂神的网站,有这方面的检测。不过,可以模拟浏览器。
换个url
import requests
payload={‘a’:‘A’,‘b’:‘B’}
r = requests.post(“http://httpbin.org/post”,data=payload)
a=r.status_code
print(a)
print(r.text)

post字符串
import requests
r = requests.post(“http://httpbin.org/post”,data=“asc”)
a=r.status_code
print(a)
print(r.text)

自动编码为data

requests.request(method, url, **kwargs)
kwargs: 12个控制访问的参数,均为可选项
-
params : 字典或字节序列,作为参数增加到url中
-
data : 字典、字节序列或文件对象,作为Request的内容
-
json : JSON格式的数据,作为Request的内容
-
headers : 字典,HTTP定制头
-
cookies : 字典或CookieJar,Request中的cookie
-
auth : 元组,支持HTTP认证功能
-
files : 字典类型,传输文件
-
timeout : 设定超时时间,秒为单位
-
proxies : 字典类型,设定访问代理服务器,可以增加登录认证
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注:Python)
nimg.cn/img_convert/6c361282296f86381401c05e862fe4e9.png)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注:Python)















 1359
1359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









