







我们对 ImageNet 的实现遵循了 [21, 41] 中的做法。 图像被调整大小,其较短的边在 [256;480] 中随机采样以进行缩放 [41]。 224 × 224 224×224 224×224 的裁剪是从图像或其水平翻转中随机采样的,减去每个像素的平均值 [21]。使用了 [21] 中的标准颜色增强。我们在每次卷积之后和激活之前采用批量归一化(BN)[16],遵循 [16]。我们按照 [13] 中的方法初始化权重,并从头开始训练所有普通/残差网络。我们使用小批量大小为 256 的 SGD。学习率从 0.1 开始,并在误差平稳时除以 10,并且模型最多训练 60 × 104 次迭代。我们使用 0.0001 的权重衰减和 0.9 的动量。我们不使用 dropout [14],遵循 [16] 中的做法。在测试中,对于比较研究,我们采用标准的 10 作物测试 [21]。为了获得最佳结果,我们采用 [41,13] 中的完全卷积形式,并在多个尺度上平均分数(调整图像大小,使短边位于 {224;256;384;480;640})。
===============================================================
我们在包含 1000 个类别的 ImageNet 2012 分类数据集 [36] 上评估我们的方法。 模型在 128 万张训练图像上进行训练,并在 5 万张验证图像上进行评估。 我们还获得了测试服务器报告的 100k 测试图像的最终结果。 我们评估 top-1 和 top-5 错误率。
普通网络。 我们首先评估 18 层和 34 层的普通网络。 34层素网如图3(中)。 18层素网也是类似的形式。 有关详细架构,请参见表 1。
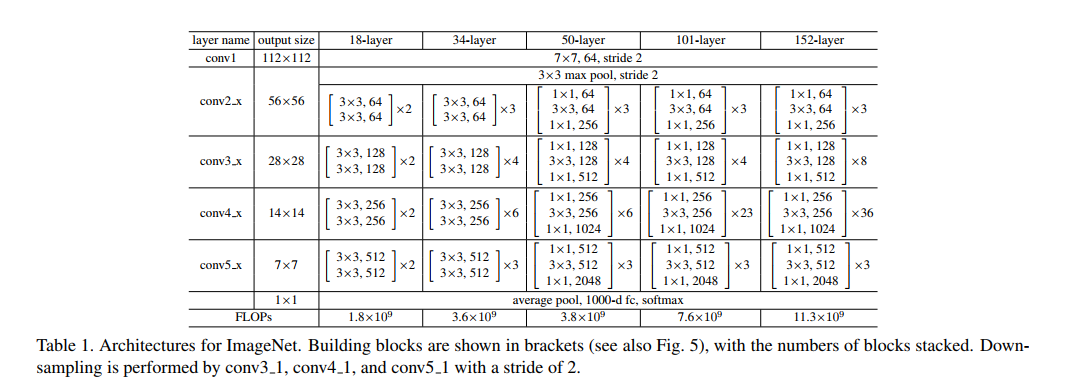
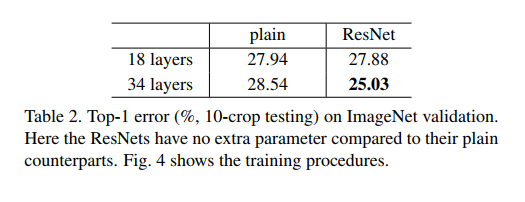
表 2 中的结果表明,较深的 34 层素网比较浅的 18 层素网具有更高的验证误差。 为了揭示原因,在图 4(左)中,我们比较了他们在训练过程中的训练/验证错误。 我们观察到了退化问题——34 层普通网络在整个训练过程中具有更高的训练误差,即使 18 层普通网络的解空间是 34 层网络的子空间。
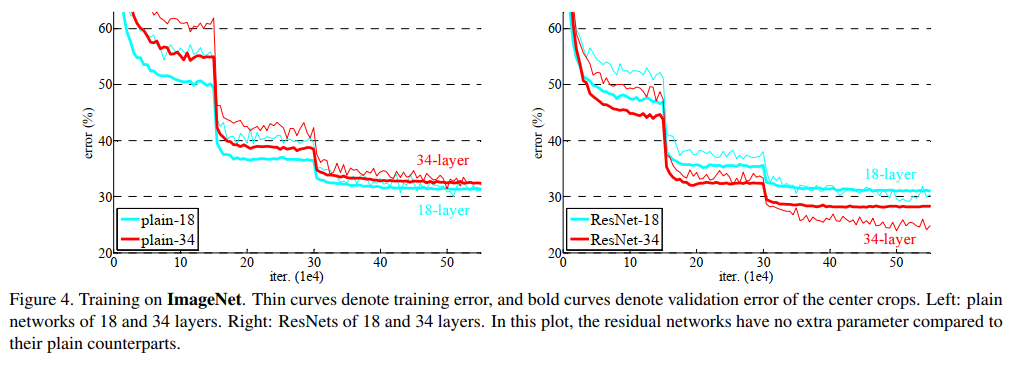
我们认为这种优化困难不太可能是由梯度消失引起的。 这些普通网络使用 BN [16] 进行训练,确保前向传播的信号具有非零方差。 我们还验证了反向传播的梯度表现出 BN 的健康规范。 因此,前向或后向信号都不会消失。 事实上,34层的普通网仍然能够达到有竞争力的精度(表3),这表明求解器在一定程度上是有效的。 我们推测深平原网络的收敛速度可能呈指数级低,这会影响训练误差的减少。 未来将研究这种优化困难的原因。
残差网络。 接下来我们评估 18 层和 34 层残差网络(ResNets)。 基线架构与上述普通网络相同,期望在每对 3×3 过滤器中添加一个快捷连接,如图 3(右)所示。 在第一个比较中(表 2 和图 4 右),我们对所有快捷方式使用恒等映射,对增加维度使用零填充(选项 A)。 因此,与普通对应物相比,它们没有额外的参数。
我们从表 2 和图 4 中得到了三个主要
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









