







一、sort 命令
sort 命令是 Linux/Unix 系统中一个非常实用的文本排序工具,它可以对文本文件或标准输入(stdin)中的行进行排序,并输出排序后的结果。它支持多种排序规则,包括按字典序、数值大小、月份、随机顺序等,还能处理重复行、合并已排序文件等任务。
1、格式:sort [参数] [文件名]
2、常用参数
-b | 忽略行首空白字符 |
-d | 按字典序排序(仅考虑字母、数字和空格) |
-f | 忽略大小写(-ignore-case) |
-h | 按人类可读的大小排序(如 2K、1G) |
-k N | 按第 N 列排序(支持范围,如 -k 2,4) |
-n | 按数值大小排序(而非字典序) |
-r | 逆序排序(降序) |
-t 分隔符 | 指定列分隔符(默认是空白符) |
-u | 去重(仅保留唯一行) |
-o 文件 | 将结果输出到指定文件(可覆盖原文件) |
-R | 随机排序(打乱顺序) |
-V | 自然版本排序(如 1.2.3 < 1.10.0) |
| -m | 只合并多个输入文件 |
3、示例:
文件 data.txt , file.txt 和 data.csv 内容如下:
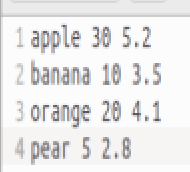
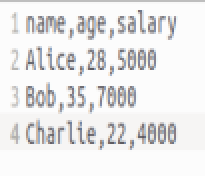
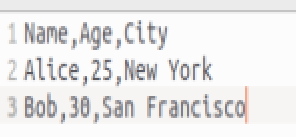
(1)默认排序(字典序):
sort file.txt # 对 file.txt 按字典序升序排序
sort -u file.txt # 去重后排序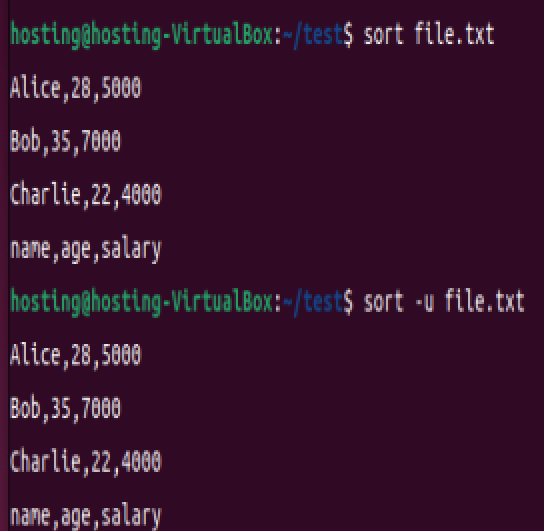
(2)数值排序:
sort -n data.txt # 按数值大小排序(如 10 > 2)
sort -nr data.txt # 数值降序排序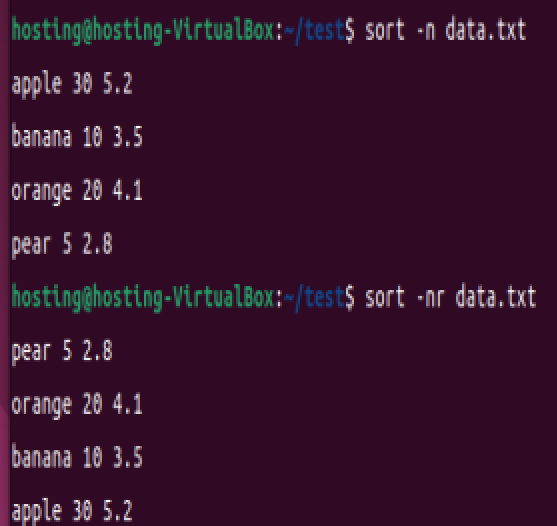
(3)按指定列排序
sort -k 3 data.txt # 按第 3 列排序
sort -t ',' -k 2,2 data.csv # 以逗号分隔,按第 2 列排序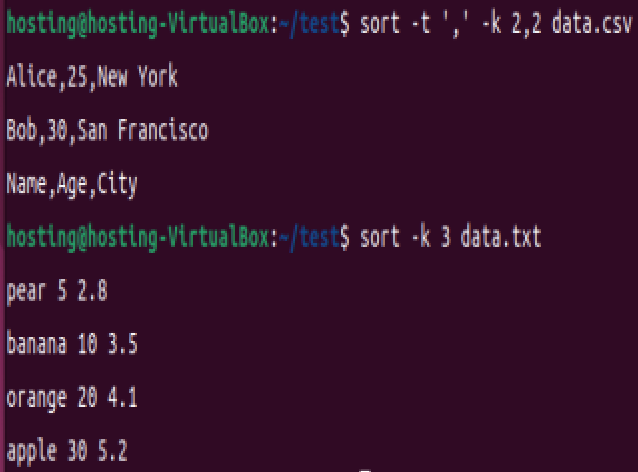
(4) 忽略大小写
sort -f data.txt # 不区分大小写排序(如 "apple" 和 "Apple" 视为相同)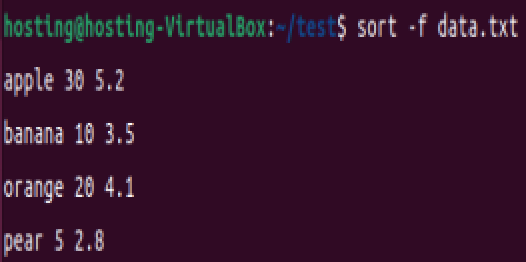
(5)人类可读大小排序
ls -l | sort -h -k 5 # 按文件大小排序(KB/MB/GB 自动识别)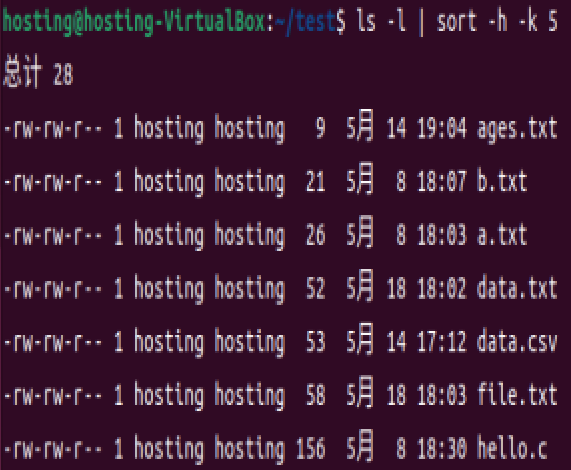
(6)随机排序
sort -R data.txt # 打乱行顺序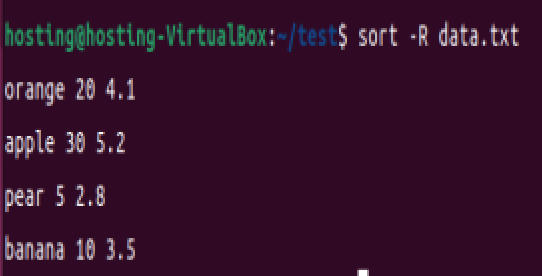
(7) 输出到文件
sort data.txt -o file.txt 文件data.txt 的内容保存到了 file.txt 中了
(8)高级用法
列出/usr/share/目录下使用空间最多的前 10 个目录文件,
du -s /usr/share/* | sort -nr | head -10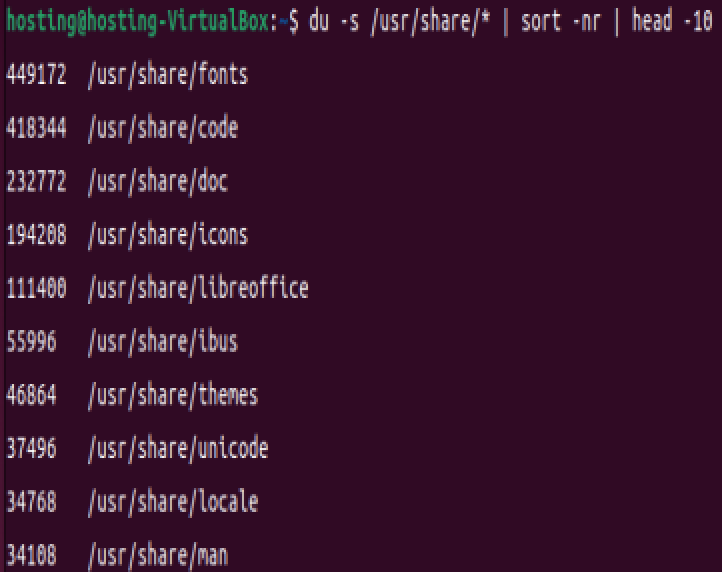
对 ls 命令输出信息中的空间使用大小字段进行排序,
ls -l /usr/bin/ | sort -nr -k 5 | head -10 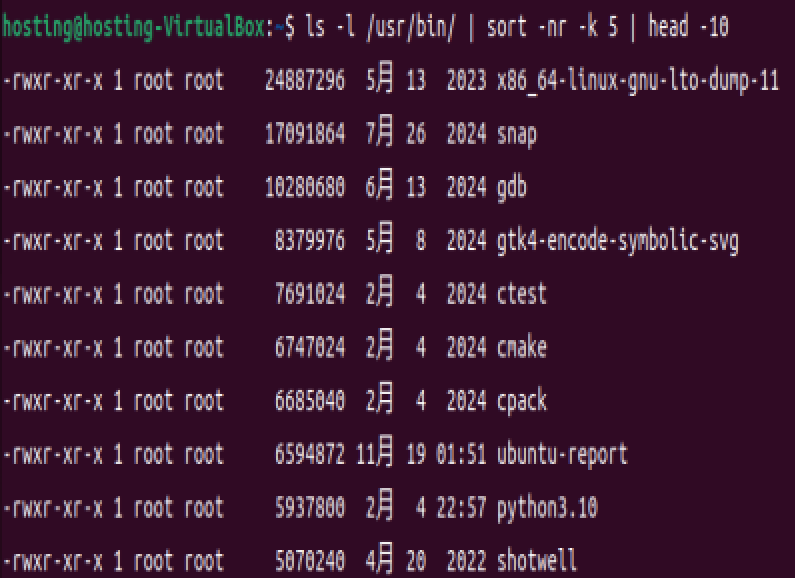
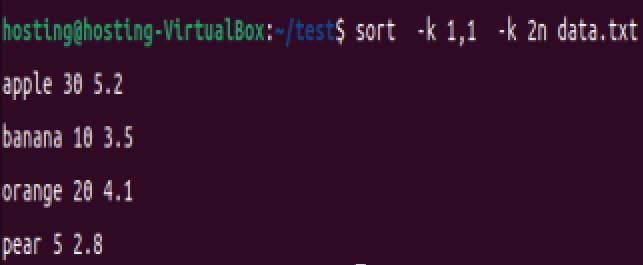
首先根据第一列的内容对文件中的行进行排序,如果第一列的内容相同,则根据第二列的数字顺序进行次级排序。
sort -k 1,1 -k 2n data.txt
4、补充:
-k 参数的语法格式是 sort 命令中最复杂但也最强大的部分之一。通过灵活控制 字段(FStart/FEnd) 和 字符位置(CStart/CEnd),可以精确指定排序的范围和规则。
完整语法:
-k FStart.CStart[Modifier][,FEnd.CEnd[Modifier]]-
FStart:起始字段(列号,从1开始)。
-
CStart:起始字段中的第几个字符(从1开始,省略则从字段开头开始)。
-
FEnd:结束字段(省略则默认到行尾)。
-
CEnd:结束字段中的第几个字符(省略或设为0表示到字段末尾)。
-
Modifier:排序规则修饰符(如
n、r、b等)。
关键概念与规则:
-
End 部分的默认行为
-
如果省略
,FEnd.CEnd,则 End 部分默认扩展到行尾(包括所有后续字段)。 -
例如
-k 2表示从第2字段开始到行尾的所有内容参与排序。
-
-
Start 和 End 的字符定位
-
FStart.CStart:从第FStart字段的第CStart字符开始。-
省略
.CStart则从字段的第一个字符开始(如-k 2等价于-k 2.1)。
-
-
FEnd.CEnd:到第FEnd字段的第CEnd字符结束。-
省略
.CEnd或设为0则到字段的最后一个字符(如-k 2,3.0)。
-
-
-
Modifier 的作用位置
-
可以分别在 Start 或 End 部分添加修饰符(如
n、r)。 -
若只在一个部分指定,则影响整个排序键范围。
-
二、uniq 命令
uniq 命令是 Linux/Unix 系统中用于过滤或检测相邻重复行的工具,通常与 sort 结合使用以处理文本数据。由于 uniq 仅能识别相邻的重复行,因此需要先对数据进行排序。
1、格式:uniq [参数] [文件名]
2、常用参数
| -c | 在每行前加上表示相应行目出现次数的前缀编号 |
| -d | 只输出重复的行 |
| -u | 只显示唯一的行 |
| -D | 显示所有重复的行 |
| -f | 比较时跳过前 n 列 |
| -i | 在比较的时候不区分大小写 |
| -s | 比较时跳过前 n 个字符 |
| -w | 对每行第 n 个字符以后的内容不作对照 |
3、示例
文件data.txt 内容如下:
![]()
(1)基本去重(需先排序,Apple 和 apple 被视为不同行)
sort data.txt | uniq 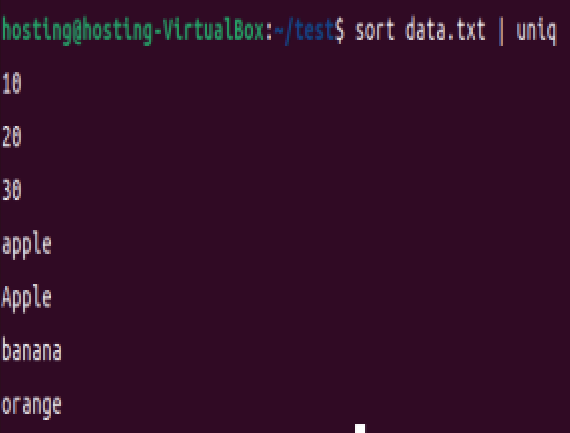
(2)忽略大小写去重(Apple 和 apple 视为相同行)
sort data.txt | uniq -i 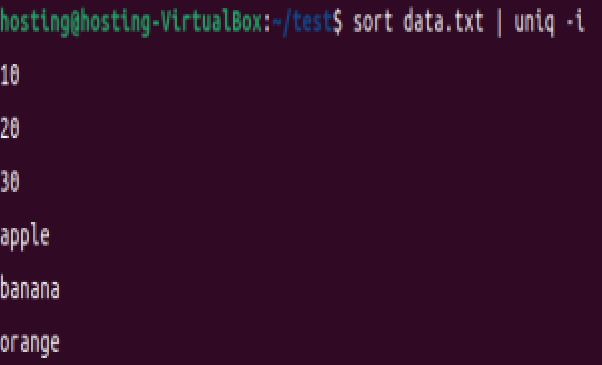
(3)统计重复次数
sort data.txt | uniq -c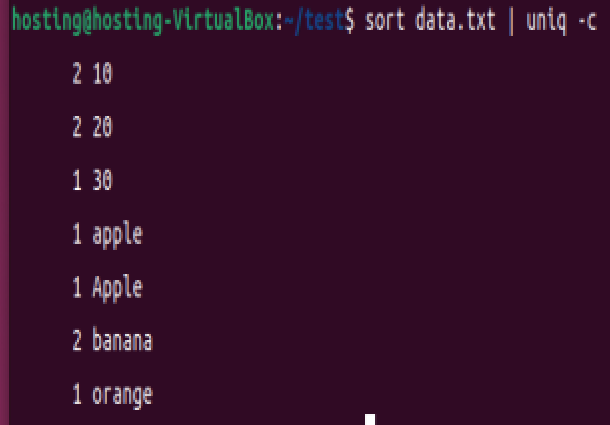
(4)仅显示重复行(每组显示一次)
sort data.txt | uniq -d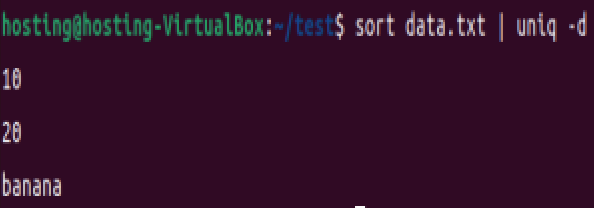
(5)仅显示唯一行(不重复的行)
sort data.txt | uniq -u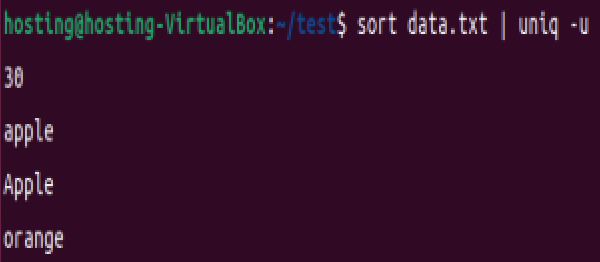
(6)结合使用
sort -k 4.1n,4.1n data.txt | uniq -c -f 3 -w 2-
排序:首先按照
student.txt文件中第 4 个字段的第 1 个字符的数字顺序对文件中的行进行排序。 -
去重并计数:对排序后的结果,跳过前 3 个字段,从第 4 个字段开始比较,只比较每个字段的前 2 个字符,统计每行出现的次数,并在每行前面加上计数。
找出/bin 目录和/usr/bin 目录下所有相同的命令
ls /bin /usr/bin | sort | uniq -d4、补充:
uniq处理的是已排序的数据,无法正确识别非相邻的重复行。- 若需直接修改文件,可结合重定向或
-o选项(某些版本支持)。 - 对大型数据集,
sort | uniq的组合可能消耗较多资源,建议先测试小样本。

















 2984
2984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









