







一、Hadoop 1.X 概述
(一)概念
Hadoop 是 Apache 开发的分布式系统基础架构,用 Java 编写,为集群处理大型数据集提供编程模型,是海量数据存储与计算的开源框架。狭义指Hadoop软件,广义代表大数据生态。Hadoop 1.x 含两大核心:MapReduce 和 HDFS。HDFS 负责分布式存储,MapReduce 负责数据计算。
(二)特点


- 可扩展性:能处理PB级数据,通过增减节点灵活伸缩。
- 高容错性:数据副本机制,部分节点故障不影响系统可用性。
- 成本效益:开源,运行于普通硬件,降低软硬件成本。
- 高效性:MapReduce并行处理,计算向数据移动,减少网络开销。
- 灵活性:支持多种数据格式(结构化、半结构化、非结构化)。
- 可移植性:基于Java,可部署于多平台(本地、云)。
- 社区支持:庞大活跃的开源社区,资源丰富。
- 生态丰富:围绕Hadoop有众多工具(Hive, Pig, HBase, Spark等)。
(三)工作原理
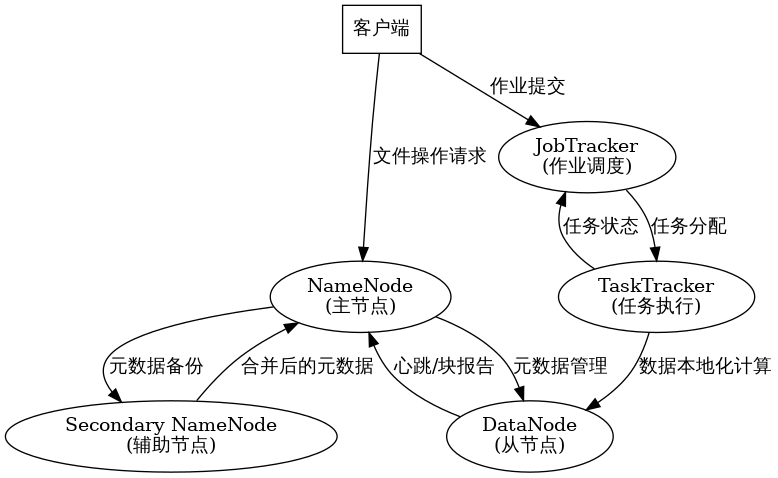
Hadoop 1.x 采用主从架构。核心进程包括:NameNode (HDFS主)、DataNode (HDFS从)、JobTracker (资源管理与作业调度)、TaskTracker (执行任务)。用户提交作业后,JobTracker 调度并将任务分配给TaskTracker。数据存储于HDFS,NameNode管理元数据,DataNode存储实际数据块。
(四)发展历史

- 起源:源于Nutch搜索引擎项目扩展性需求。受Google的GFS和MapReduce论文启发,Nutch开发者实现了HDFS和MapReduce,后剥离成Hadoop。
- 发展:2006年Apache Hadoop项目启动,雅虎大力支持。 2008年成Apache顶级项目,Cloudera成立推动商业化。后续生态日渐繁荣,众多公司开始应用。
二、Hadoop 1.X 核心组件
(一)HDFS
1. 概念
HDFS (Hadoop分布式文件系统)是Hadoop数据存储的基础。它高度容错,运行于廉价硬件,通过流式数据访问支持高吞吐量,适合大型数据集。
2. 特点
- 大文件存储:适合TB、PB级大文件。
- 分块存储:大文件切块(默认64M),多副本(默认3个)存不同机器,提高读写效率和容错性。
- 流式访问:“一次写入,多次读取”,不支持文件随机修改,仅支持追加。
- 廉价硬件:可在普通PC搭建集群。
- 高容错:副本机制确保节点故障时数据不丢失。
3. 工作原理
HDFS采用Master-Slave架构,含一个NameNode(主)和多个DataNode(从)。
- NameNode:管理文件系统命名空间(元数据:文件名、目录、块位置等),控制客户端访问。元数据存内存并持久化到磁盘(fsimage, edits log)。
- DataNode:实际存储文件数据块及校验和。向NameNode注册并周期性发送心跳和块报告。
- Secondary Namenode:辅助NameNode,定期合并fsimage和edits log,减轻NameNode压力,可能减少宕机时数据丢失。
4. 发展历史
HDFS 的设计思想 深受 Google 的分布式文件系统 GFS 的启发。如前所述,Nutch 项目的核心开发者 Doug Cutting 等人借鉴 GFS 的理念实现了 HDFS,并将其作为 Hadoop 不可或缺的一部分。在 Hadoop 的整个发展过程中,HDFS 也经历了持续的改进和优化,以不断提高其性能、可靠性和可扩展性。
(二)MapReduce
1. 概念
MapReduce是分布式计算框架,第一代离线数据计算引擎,处理TB、PB级数据。核心思想是计算分Map和Reduce两阶段。
2. 特点
- 分而治之:Map阶段并行局部处理,Reduce阶段并行全局汇总。
- 移动计算:计算程序移至数据节点,减少网络I/O。
3. 工作原理
- 输入切片:文件逻辑切片(InputSplit),每Split一Map Task。
- Map阶段:Map Task处理输入数据,输出中间键值对。
- Shuffle阶段:Map中间结果 复制、排序、分组到Reduce Task。
- Reduce阶段:Reduce Task汇总相同key的中间值,输出最终结果。
4. 发展历史
MapReduce 的思想根源于 Google 在 2004年发表的著名论文《MapReduce: Simplified Data Processing on Large Clusters》。在 Hadoop 1.x 版本中,MapReduce 不仅承担了分布式数据计算的核心角色,其内部的 JobTracker 组件还同时负责了集群的资源管理和作业调度。这种设计使得 MapReduce 框架显得比较臃肿,并且限制了 Hadoop 集群只能运行 MapReduce 类型的任务。从 Hadoop 2.x 版本开始,官方对 MapReduce 的功能进行了拆分,引入了独立的资源管理框架 YARN。此后,MapReduce (通常称为 MapReduce on YARN 或 MRv2) 仅专注于其作为分布式数据计算引擎的核心职责。
三、Hadoop 1.X 组件关联分析
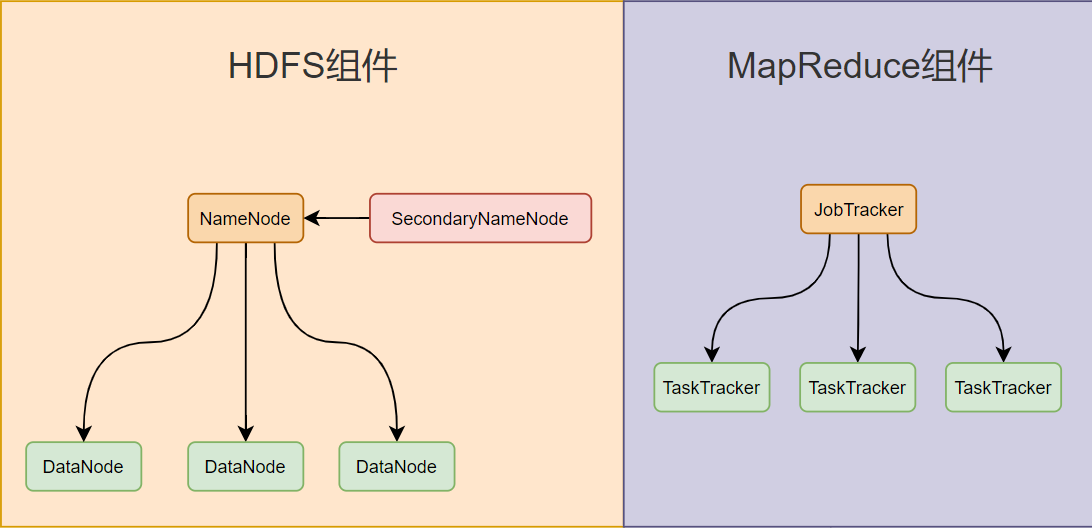
(一)组件关联图说明
(二)协同工作机制
HDFS和MapReduce在Hadoop1.X中紧密协作。
HDFS为MapReduce提供数据存储。NameNode提供元数据,DataNode存储数据块。MapReduce的Map Task从DataNode读取数据。
MapReduce利用HDFS数据进行计算。Map Task局部处理,Reduce Task全局汇总。JobTracker负责资源管理和作业调度,将任务分配给TaskTracker,考虑数据本地性。
例如,日志分析:日志存HDFS。MapReduce作业启动,JobTracker将Map Task分配到数据节点。Map Task局部分析。Shuffle后,Reduce Task汇总,结果写回HDFS。
四、Hadoop 1.X 与其他版本的对比
Hadoop 1.x vs Hadoop 2.x
- YARN引入:最核心区别。Hadoop 2.x引入YARN,分离资源管理与计算,支持多种计算框架(Spark等),不再局限于MapReduce。
- 存储与容错:Hadoop 2.x支持纠删码,比1.x的3副本方案更节省存储。
- 单点故障:Hadoop 1.x的NameNode和JobTracker存在单点故障。Hadoop 2.x引入HA机制解决此问题,提高集群可靠性。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









