






最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:

给大家整理的电子书资料:

如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
一、网络模型结构
LeNet是具有代表性的CNN,在1998年被提出,是进行手写数字识别的网络,是其他深度学习网络模型的基础。其网络模型结构如下图所示,它具有连续的卷积层和池化层,最后经全连接层输出结果。
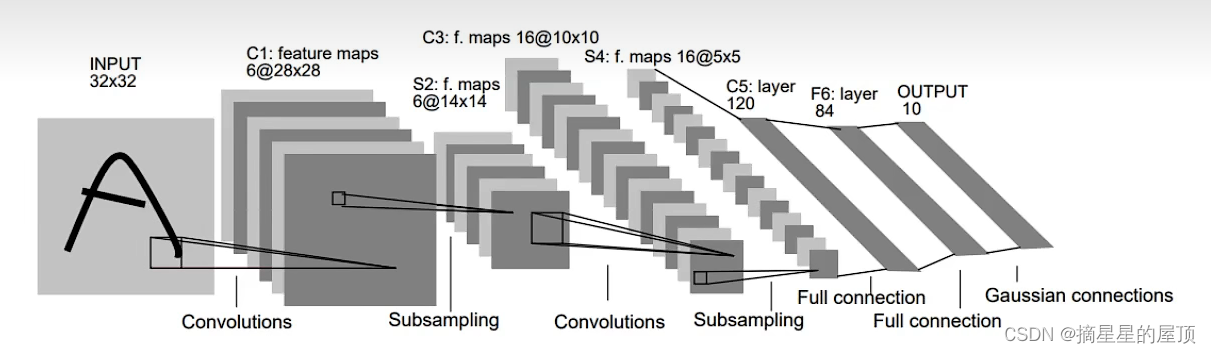
二、各层参数详解
2.1 INPUT层-输入层
数据input层,输入图像的尺寸为:32*32大小的一维一通道图片。
注意:①灰度图像是单通道图像,其中每个像素只携带有关光强度的信息;
②RGB图像是彩色图像,为三通道图像;
③传统上输入层不被视为网络层次结构之一,因此输入层不算LeNet的网络结构。
2.2 C1层-卷积层
输入数据(输入特征图input feature map):32*32
卷积核大小:5*5
计算公式:
;
其中,
是指输入图片的高度;
是指输入图片的宽度;
是指卷积核的大小;padding是指向图片外面补边,默认为0;S是指步长,卷积核遍历图片的步长,默认为1。
卷积核种类(通道数):6
输出数据(输出特征图output feature map):28*28
2.3 S2层-池化层(下采样层)
池化是缩小高、长方向上的空间的运算。
输入数据:28*28
采样区域:2*2
采样种类(通道数):6
输出数据:14*14
注意:①经过池化运算,输入数据和输出数据的通道数不会发生变化。
②此时,S2中每个特征图的大小是C1中每个特征图大小的1/4.
2.4 C3层-卷积层
**输入数据:**S2中所有6个或者几个特征map组合
卷积核大小:5*5
卷积核种类(通道数):16
输出数据(输出特征图output feature map):10*10
注意:C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合。
2.5 S4层-池化层(下采样层)
输入数据:10*10
采样区域:2*2
采样种类(通道数):16
输出数据:5*5
2.6 C5层-卷积层
**输入数据:**S4层的全部16个单元特征map(与s4全相连)
卷积核大小:5*5
卷积核种类(通道数):120
输出数据(输出特征图output feature map):1*1
2.7 F6层-全连接层
**输入数据:**120维向量
**输出数据:**84维向量
2.8 Output层-全连接层
**输入数据:**84维向量
**输出数据:**10维向量
三、代码实现(采用的激活函数为relu函数)
3.1 搭建网络框架
(1)导包:
import torch
import torch.nn as nn
import torch.nn.functional as F
(2)**定义卷积神经网络:**由于训练数据采用的是彩色图片(三通道),因此与上面介绍的通道数有出入。
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1 = nn.Conv2d(3,6,5)
self.conv2 = nn.Conv2d(6,16,5)
self.fc1 = nn.Linear(16*5*5,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
x = self.conv1(x)
x = F.relu(x)
x = F.max_pool2d(x,(2,2))
x = F.max_pool2d(F.relu(self.conv2(x)),2)
x = x.view(-1,x.size()[1:].numel())
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
(3)**测试网络效果:**相当于打印初始化部分,可以查看网络的结构
net = Net()
print(net)

3.2 定义数据集
(1)导包:
import torchvision
import torchvision.transforms as transforms
(2)下载数据集:
解决Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz国内下载速度缓慢的问题:
解决方法:
①下载文件:**下载地址:**https://pan.baidu.com/s/1Nh28RyfwPNNfe_sS8NBNUA
提取码:1h4x
②将下载好的文件重命名为cifar-10-batches-py.tar.gz
③将文件保存至相应地址下即可
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
trainset = torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data',train=False,download=True,transform=transform)
trainloader = torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True,num_workers=0)
testloader = torch.utils.data.DataLoader(testset,batch_size=4,shuffle=False,num_workers=0)

(3)定义元组:进行类别名的中文转换
classes = ('airplane','automobile','bird','car','deer','dog','frog','horse','ship','truck')
(4)运行数据加载器:使用绘图函数查看数据加载效果
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()
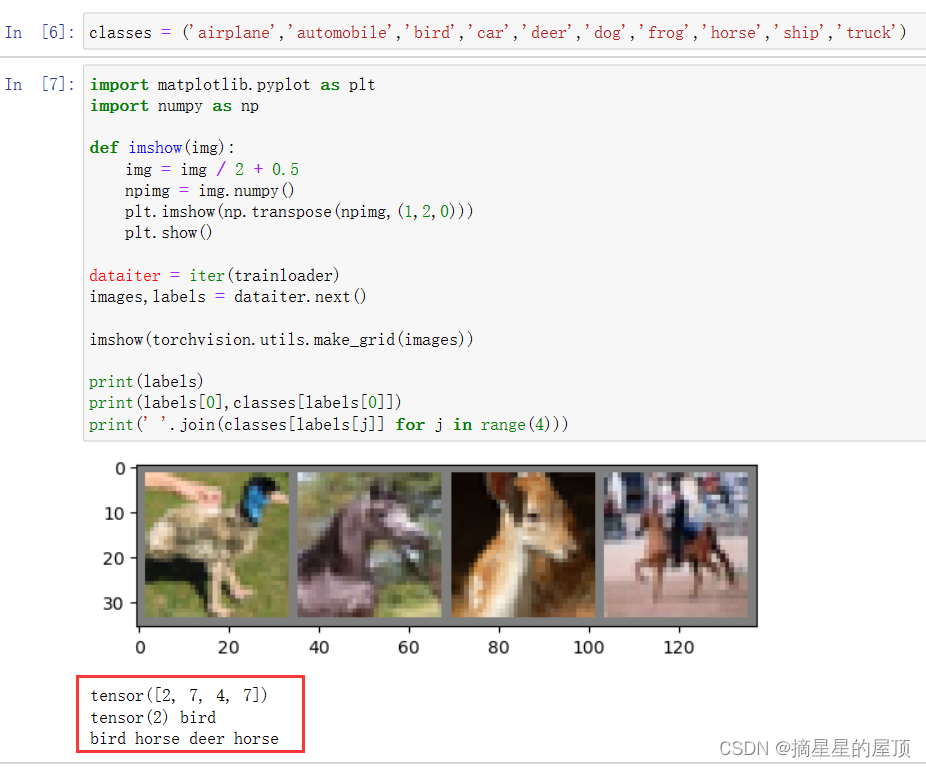
dataiter = iter(trainloader)
images,labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(labels)
print(labels[0],classes[labels[0]])
print(' '.join(classes[labels[j]] for j in range(4)))
3.3 定义损失函数与优化器
(1)**定义损失函数:**交叉熵损失函数
criterion = nn.CrossEntropyLoss()
为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。

本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1104
1104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









