







-
空行
-
参数
抓包的request结构如下:
GET / HTTP/1.1
Host: jwgl.fjnu.edu.cn
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.157 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8,application/signed-exchange;v=b3
Referer: https://www.baidu.com/link?url=a98CxMug1u-J-RFk4E7kaP9hhk2EK8700MuPKT4cZYTTPG_urDB7Asq8TDNqQJFD&wd=&eqid=f7c332cc007927a4000000065cf20629
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: UM_distinctid=1696fc8ec3e1b0-0585ff9addbe6b-1333062-100200-1696fc8ec3f2f4; ASP.NET_SessionId=1uslg345bvgyqnny4yyjbz45
Connection: keep-alive
请求行:请求行只会有一行,且固定为第一行。在这里是GET / HTTP/1.1
请求头:Host Upgrade-Insecure-Requests … Cookie Connection这些都是请求头,每一行都是一个请求头 格式为键值对类型。
空行:请求头与参数之间会有一个空行
参数: 因为GET请求的参数是放在URL上的,所以这里的参数没有独占一行
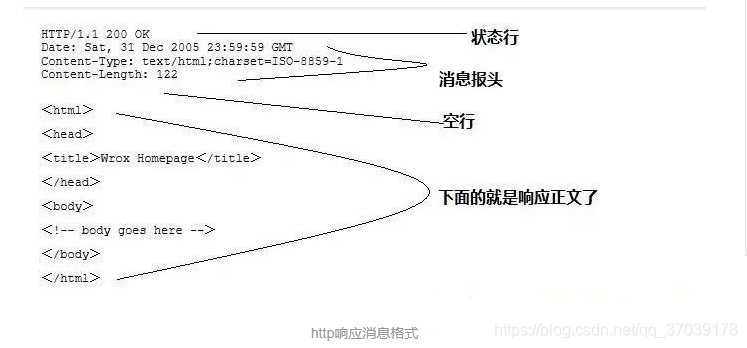
HTTP响应也包含四个部分(这个比较重要):
-
状态行
-
消息报头(有时也俗称响应头)
-
空行
-
响应正文
=========================================================================
Jsoup 类是一个工具类,提供了一些静态函数,主要函数如下:
Jsoup.parse(String html) 该函数的作用是将传入的html格式的字符串解析成文档树,返回值是Document对象。
Jsoup.parse(File in,String charsetName) 将文件的内容解析成Document对象。
Jsoup.connect(String url) 根据传入的url返回一个Connection对象,Connection类的功能下面会介绍。
Element类对应文档树中的节点元素,这个类的常用函数如下:
getElementsByClass(String className) 返回所有带有className类属性的孩子节点。
getElementById(String id) 返回对应id的子节点
getElementsByTag(String tagName) 返回标签为tagName的所有孩子节点
jsoup库有着很丰富的功能与API,需要详细了解可以查看官网API文档
=================================================================
在app模块下的build.gradle文件中的dependencies属性里添加一行内容
implementation group: ‘org.jsoup’, name: ‘jsoup’, version: ‘1.8.3’

String html = “” +
“” +
“
“” +
“” +
“hello world” +
“” +
“”;
Document doc = Jsoup.parse(html);//解析html字符串,获取document对象
Elements body = doc.getElementsByTag(“body”);//获取body标签的元素
Element element = body.get(0);//因为body是一个集合类型,所以需要取集合里的第一个元素
System.out.println(element.text());//打印元素的内容 hello world
String title = doc.title();//获取title值
System.out.println(title);
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Android工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip204888 (备注Android)

最后
Android学习是一条漫长的道路,我们要学习的东西不仅仅只有表面的 技术,还要深入底层,弄明白下面的 原理,只有这样,我们才能够提高自己的竞争力,在当今这个竞争激烈的世界里立足。
人生不可能一帆风顺,有高峰自然有低谷,要相信,那些打不倒我们的,终将使我们更强大,要做自己的摆渡人。
资源持续更新中,欢迎大家一起学习和探讨。
5)]
最后
Android学习是一条漫长的道路,我们要学习的东西不仅仅只有表面的 技术,还要深入底层,弄明白下面的 原理,只有这样,我们才能够提高自己的竞争力,在当今这个竞争激烈的世界里立足。
人生不可能一帆风顺,有高峰自然有低谷,要相信,那些打不倒我们的,终将使我们更强大,要做自己的摆渡人。
资源持续更新中,欢迎大家一起学习和探讨。














 7729
7729











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









