







-
如果Nameserver与Broker端的长连接断开,NameServer会立即感知Broker下线并从路由表中将该Broker移除。
-
消息客户端(消息发送者、消息消费者)在任意时刻只会和其中一台NameServer建立连接,并每隔30s向NameServer查询路由信息,如果查询到结果会更新发送者的本地路由信息。
从上述的路由注册、剔除机制来看,当一台Broker服务器宕机,消息发送者感知路由信息发生变化需要的时间是多长呢?
分如下两种情况分别讨论:
-
NameServer与Broker服务器TCP连接断开,此时NameServer能立即感知路由信息变化,将其从路由表中移除,从而消息发送端应该在30s左右就能感知路由发送变化,在此30s内在发送端会出现消息发送失败,但结合发送规避机制,并不会对发送方带来重大故障,可接受。
-
如果NameServer与Broker服务器的TCP连接未断开,但Broker已无法提供服务(例如假死),此时NameServer需要120s才能感知Broker宕机,此时消息发送端最多需要150s才能感知其路由信息的变化。
但问题来了,为什么在生产实际过程中一台Broker由于内存故障重启,10分钟后重启成功后业务才恢复,即业务才真正感知Broker宕机呢?
既然出现了,我们就需要对其进行分析,给出解决方案,避免不会在生产环境出现同类型的错误。
2.2 故障排查经过
先查询客户端的日志(/home/{user}/logs/rocketmqlogs/rocketmq_client.log),从中可以看到从客户端第一次报消息发送超时的时间是14:44,其日志输出如下:
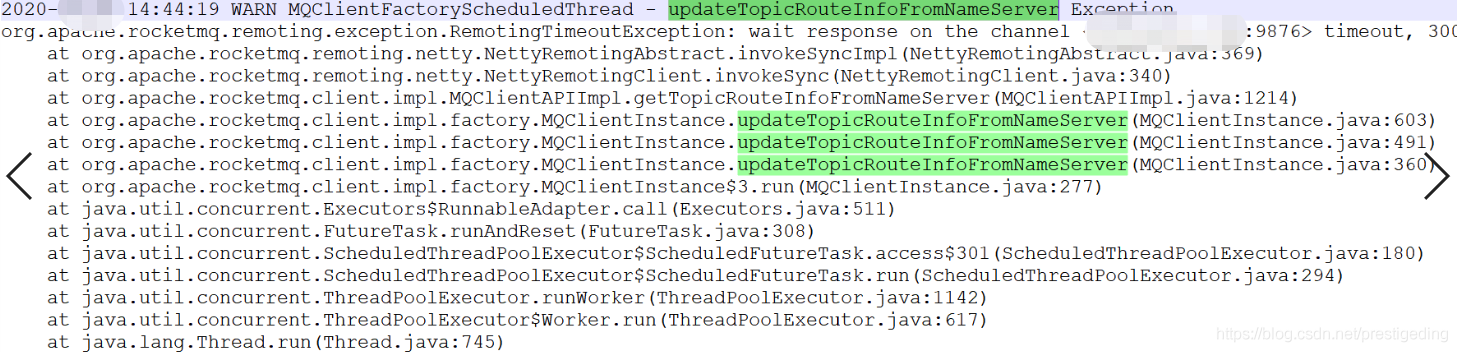
由于192.168.3.100机器内存故障,故首先去查看该集群中其他nameserver中的日志,看正常机器中的NameServer感知broker-a故障的时长,其日志如下所示:

从中可以看出192.138.3.101的nameserver基本在2分钟左右才感知其宕机,即虽然机器在重启,但可能由于操作系统要做硬件自检等其他原因,TCP连接并未断开,故nameserver在120s后才感知其宕机,从路由信息表中将该broker移除,那按照路由剔除机制,客户端应该在150秒的时间内感知其变化,那为什么没感知呢?
继续查看客户端路由信息,查看客户端感知路由信息发生变化的时间点,如下图所示:
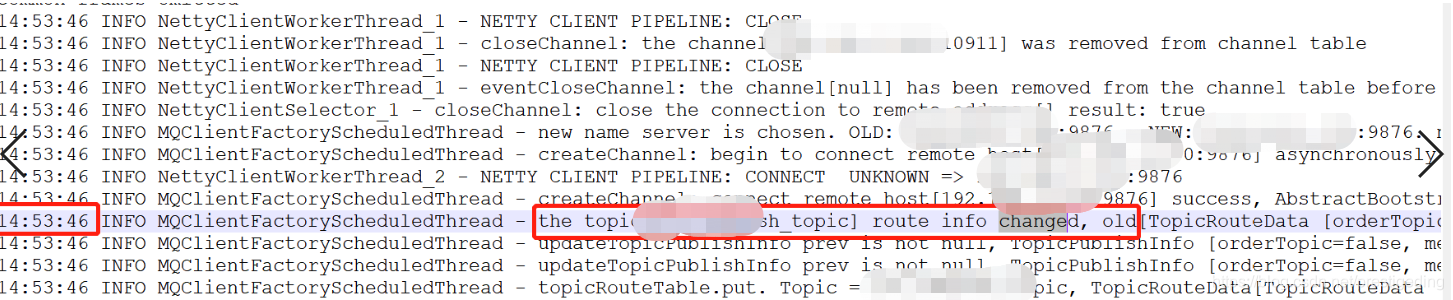
从客户端日志来看,客户端在14:53:46才感知其变化,这又是为什么呢?
原来客户端在更新路由信息时报超时异常,其截图如下所示::
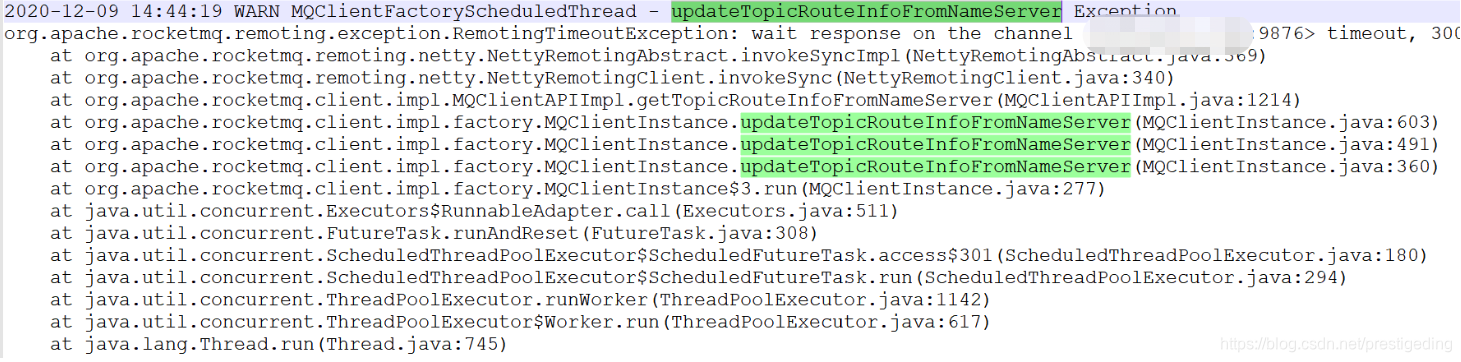
从发生故障到故障恢复期间,客户端一直尝试从已发生故障的NameServer去更新路由信息,但一直返回超时,这样就导致了客户端一直无法获取最新的路由信息,故一直无法感知已宕机的Broker。
从日志分析来看,到目前来说就比较明朗了,客户端之所有没有在120s之内感知其路由信息的变化,是因为客户端一直尝试从已宕机的nameserver去更新路由信息,但由于一直无法请求成功,故客户端的缓存路由信息一直无法得到更新,造成了上面的现象
那问题来了,按照我们对RocketMQ的认识,NameServer宕机,客户端会自动去从nameserver列表中选择下一个nameserver,那为什么这里并没有发生nameserver切换,而是等到14:53才切换呢?
接下来我们将目光投向NameServer的切换代码,其代码片段如下图所示:
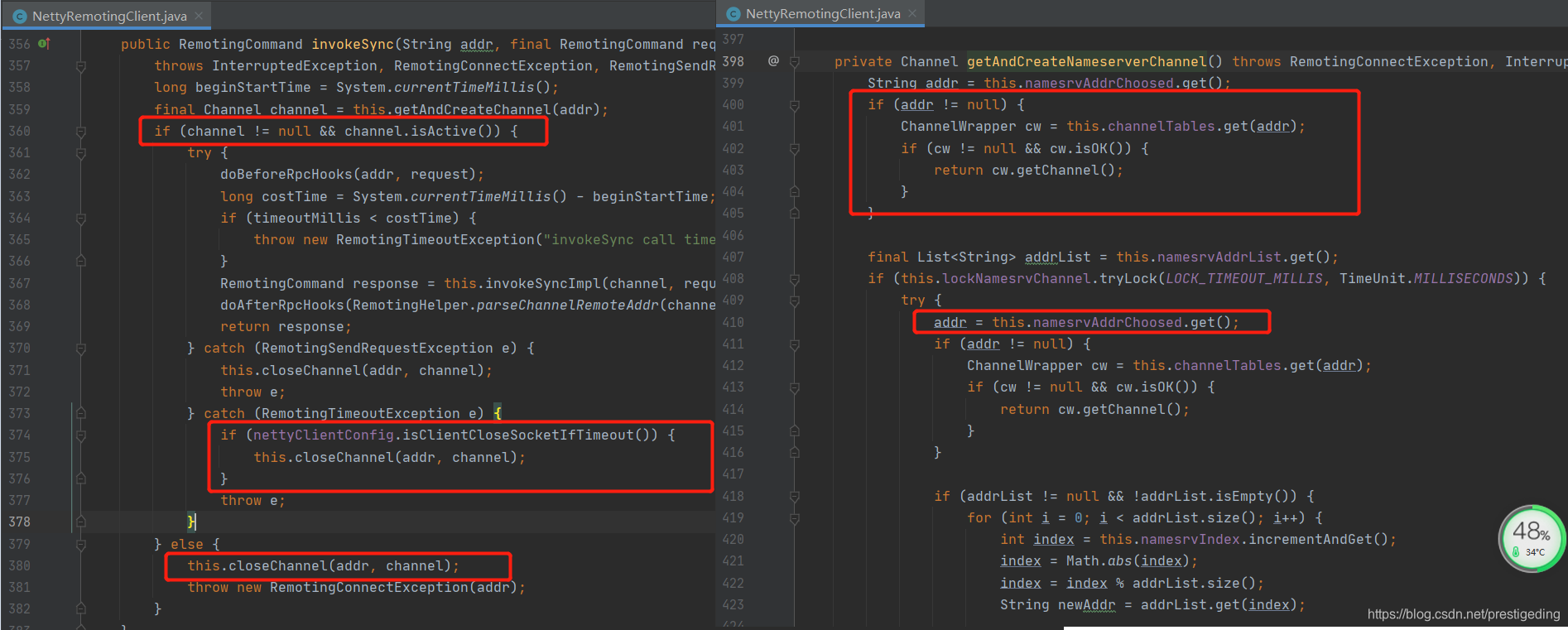
上图中的几个关键分析如下:
-
客户端能通过缓存中的连接发送RPC请求的前提条件是channel的isActive方法返回true,即底层TCP连接处于激活状态。
-
在客户端向服务端发起RPC请求时,如果出现非超时类异常,会执行closeChannel方法,该方法会关闭连接并从连接缓存表中移除,这个非常关键,因为在切换NameServer时如果缓存中存在连接并连接处于激活状态,就不会切换nameserver。
-
如果发送RPC超时,rocketmq会根据clientCloseSocketIfTimeout参数来决定是否关闭连接,但遗憾的是该参数默认为false,并且并未提供修改的入口。
那问题分析到这里,已经非常明了,由于机器内存故障触发重启并且重启前需要自检等因素,造成nameserver,broker无法再处理请求但底层TCP连接并未断开,导致发生超时错误,但客户端并不会关闭与故障机器nameserver的TCP连接,导致无法切换,等到机器重新启动后,TCP连接断开,故障机器重启完成后感知路由信息变化,故障恢复。
经过上面的问题分析,其故障原因如下:
192.168.3.100机器在内存故障后重启,整个重启耗时10分钟,并且在重启过程中TCP连接未断开,192.168.3.101 nameserver在故障发送时2分钟左右才感知路由变化,但部分客户端时连接192.168.3.100的nameserver,客户端尝试从该nameserver查询路由信息,但一直返回超时,由于没有关闭连接,导致客户端并不会切换到3.101的nameserver,直到客户端与nameserver的TCP连接断开后,切换到另外一个3.101的nameserver,故障在指定时间内得以恢复。
根本原因:其实是nameserver的假死导致路由信息无法更新。
经过上面的故障,个人觉得nameserver不应该与broker部署在一起,如果nameserver与broker并不部署在一起,上面的问题能得到有效避免,其部署架构如下图所示:
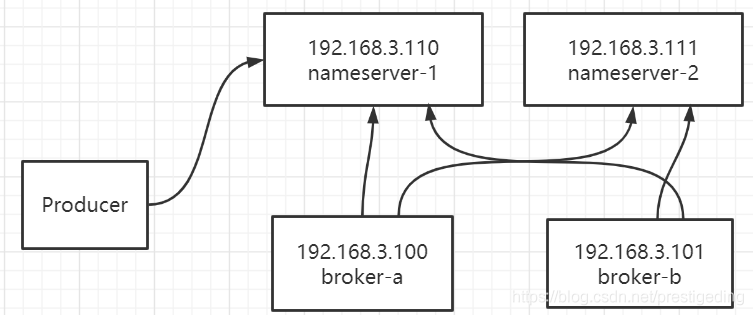
这样的部署架构如果面对上面的故障,Broker假死的情况,能有效避免吗?答案是可以的。
如果192.168.3.100的broker假死,那么3.110,3.111的nameserver都能在2分钟内感知broker-a宕机,然后客户端能成功从nameserver处获得最新的路由信息,如果nameserver假死,出现超时错误,只要broker不宕机,则通过缓存,还是能正常工作的,但如果nanmeserver,broker一起假死,则上述架构还是无法规避上面的问题。
故本次的最佳实践主要包含如下两条:
1、nameserver与broker一定要分开部署,进行隔离。
2、nameserver与客户端的连接,应该在超时后,关闭连接,触发nameserver漂移,需要修改源码。
好了,本文就介绍到这里了,您的点赞与转发是对我持续输出高质量文章最大的鼓励。
欢迎加笔者微信号(dingwpmz),拉您如技术交流加群探讨,关注『中间件兴趣圈』回复**【PDF】**可获取海量学习资料。

自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

写在最后
还有一份JAVA核心知识点整理(PDF):JVM,JAVA集合,JAVA多线程并发,JAVA基础,Spring原理,微服务,Netty与RPC,网络,日志,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存,Hadoop,Spark,Storm,YARN,机器学习,云计算…

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
…(img-FBomuJN9-1713380550738)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 1907
1907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









