







一、使用docker部署mysql主从 实现主从复制
此次使用的是windows版本docker,mysql版本是5.7
- 1、使用docker获取mysql镜像
docker pull mysql:5.7.23 #拉取镜像文件
docker images #查看镜像文件

- 2、使用docker运行mysql master
docker run --name mysql-master --privileged=true -v F:\dockerV\mysql:/var/lib/mysql -p 3307:3306 -e MYSQL_ROOT_PASSWORD=654321 -d mysql:5.7.23
-
- –name 容器名称mysql-master
-
–privileged 指定了当前容器是否真正的具有root权限,所谓的root权限是指具有宿主机的root权限,而不仅仅只是在容器内部有root权限
-
-v 将系统的F:\dockerV\mysql挂载到容器的/var/lib/mysql,注意是将宿主机 挂载到 容器内部,而不是将容器内部挂载到宿主机
-
-p 表示宿主机上的某个端口映射到docker容器内的某个端口,这里也就是将宿主机的3307端口映射到容器内部的3306端口
-
-e 表示指定当前容器运行的环境变量,该变量一般在容器内部程序的配置文件中使用,而在外部运行容器指定该参数。这里的MYSQL_ROOT_PASSWORD表示容器内部的MySQL的启动密码
-
-d 后台运行,镜像文件为mysql:5.7.23
-
接下来进入容器内部,修改配置,使其作为mysql master运行
docker exec -it mysql-master bash #进入容器内部

- 配置mysql master,修改mysql.cnf

- 使用vim修改mysql.cnf,没有安装vim会提示bash: vi: command not found 则需要安装vim
apt-get install vim
apt-get update
apt-get install vim
vim mysqld.cnf #修改cnf文件,添加 server-id 表示master服务标识,同一局域网内注意要唯一 和 log-bin=mysql-bin 开启二进制日志功能,可以随便取,用来完成主从复制
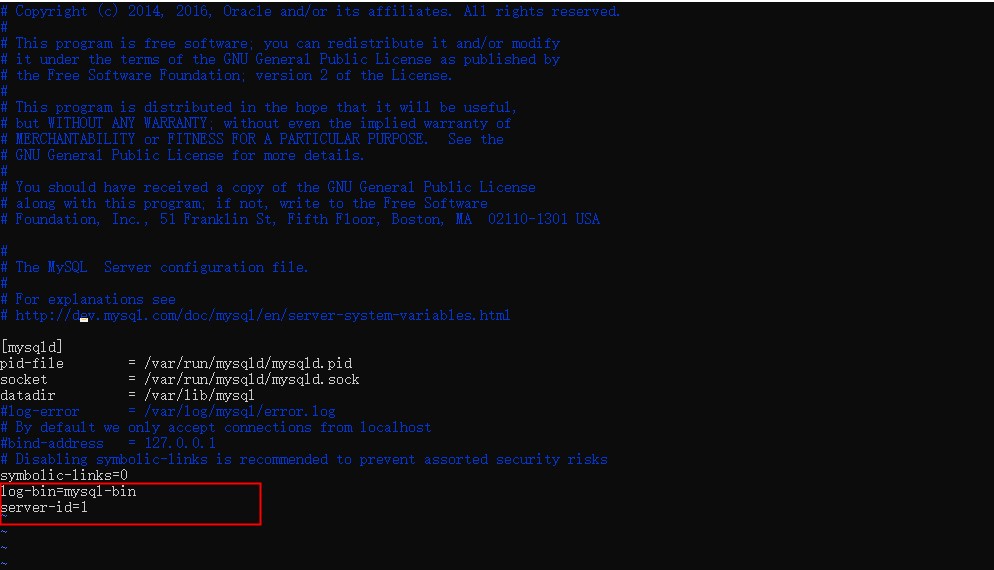
- 修改完成mysql的配置后,需要重启服务生效
service MySQL restart # 重启mysql服务时会使得docker容器停止,我们还需要docker start mysql-master启动容器
docker start mysql-master #启动容器
- 连接mysql客户端,创建用来完成主从复制的账号
mysql -uroot -p654321 #连接mysql
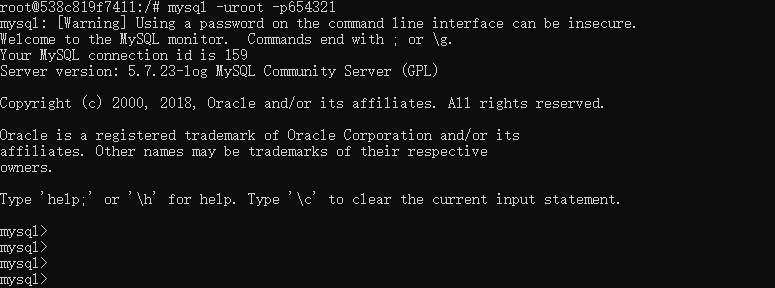
- 为从服务器创建一个可以用来操作master服务器的账户,也就是创建一个专门用来复制binlog的账号,并且赋予该账号复制权限,其命令如下
grant replication slave on *.* to 'slaveaccount'@'%' identified by '654321'; #账号slaveaccount 密码654321
flush privileges; #刷新用户权限表
show master status #查看mysql master的状态
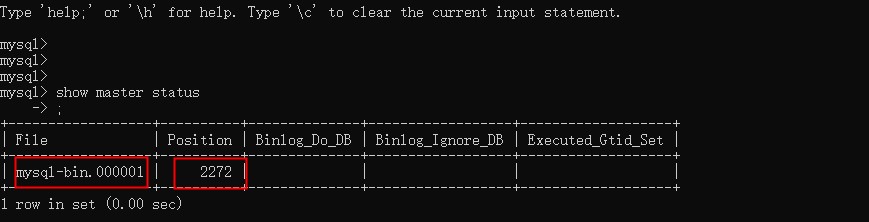
记录下上的position和file 在创建MySQL slave配置时会用到
到这里mysql master 已经配置完成了
- 3、使用docker运行mysql slave
docker run --name mysql-slave --privileged=true -v F:\dockerV\mysql-slave:/var/lib/mysql -p 3308:3306 --link mysql-master:master -e MYSQL_ROOT_PASSWORD=654321 -d mysql:5.7.23
mysql slave 的参数主要和master有两点不同
-
所映射的宿主机的端口号不能与master容器相同,因为其已经被master容器占用;
-
必须加上–link参数,其后指定了当前容器所要连接的容器,mysql-master表示所要连接的容器的名称,master表示为该容器起的一个别名,通俗来讲,就是slave容器通过这两个名称都可以访问到master容器。这么做的原因在于,如果master与slave不在同一个docker network中,那么这两个容器相互之间是没法访问的。
docker exec -it mysql-slave /bin/bash #进入mysql salve容器
vim mysqld.cnf #修改cnf文件,添加 server-id 表示slave服务标识,如果此salve需要作为其他mysql的主,那么就需要配置log-bin=mysql-bin
service MySQL restart # 重启mysql服务时会使得docker容器停止,我们还需要docker start mysql-slave启动容器
docker start mysql-master #启动容器
mysql -uroot -proot #连接mysql服务
配置mysql slave 使其以slave模式运行
change master to master_host='172.17.0.2', master_user='slaveaccount', master_password='654321', master_port=3306, master_log_file='mysql-bin.000001', master_log_pos=2272, master_connect_retry=30;
注意:这一步主要在slave是配置master的信息,包括 master的 地址、端口、账号、密码、log文件、log文件偏移量、重试。下面介绍这些参数值从何获取
- 获取master_host,使用docker inspect mysql-master查看master容器元数据。其中 IPAdress是master_host
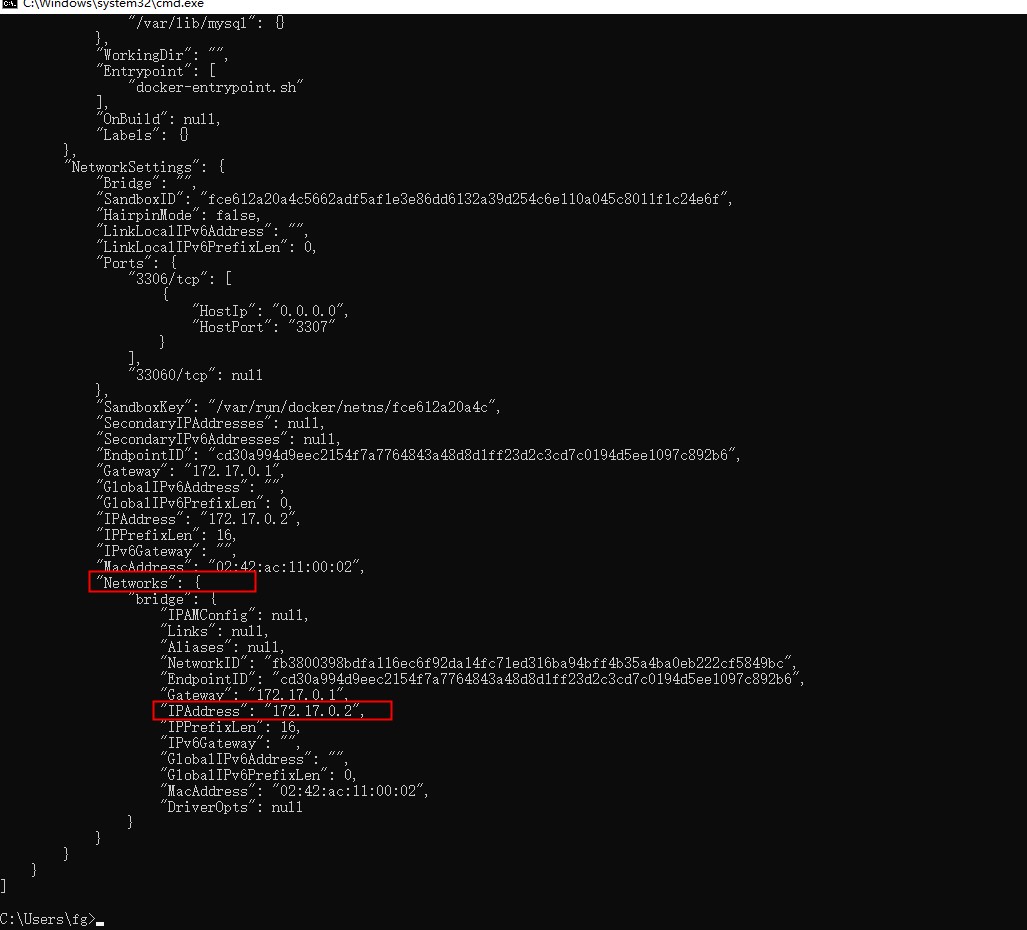
-
获取master_port,是运行master映射容器内部的端口,这里就是3306
-
获取master_user和master_password,是第一步中在master中创建的slave账号
-
获取master_log_file和master_log_pos,是配置master中最后一步使用show master status获取的文件和偏移量
-
获取master_connect_retry,是slave重试连接master动作前的休眠时间,单位s,默认60s
start slave; #以slave模式运行
show salve status \G; #查看slave的状态
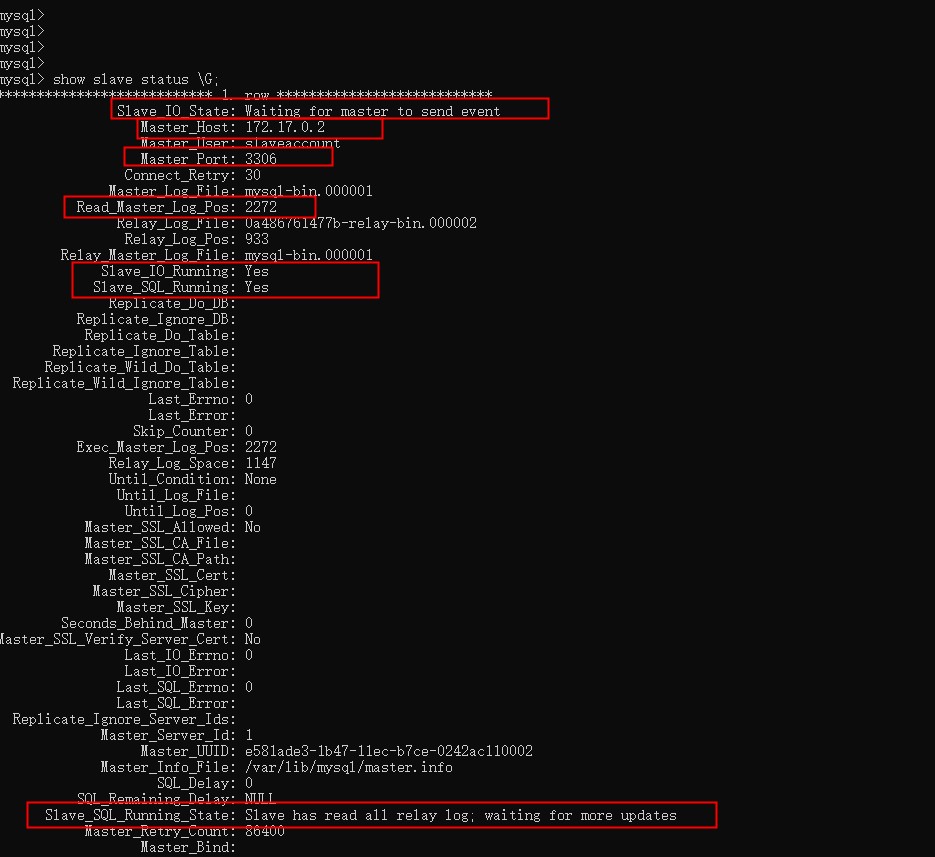
可以看到,Slave_IO_Running:YES和Slave_SQL_Running:YES 证明此时主从复制已经就绪,slave配置到此完成
-
4、验证主从复制效果
-
这里我们在连接master,并创建一张表,添加数据,在从库查看数据是否同步。
-
在主库创建数据,并在从库查看数据是否同步成功。
mysql> create database test;
Query OK, 1 row affected (0.01 sec)
mysql> use test;
Database changed
mysql> create table t_user(id bigint, name varchar(255));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t_user(id, name) value (1, ‘cgg’);
Query OK, 1 row affected (0.01 sec)
mysql> select * from test.t_user;
±-----±-----+
| id | name |
±-----±-----+
| 1 | cgg |
±-----±-----+
1 row in set (0.00 sec)
- 5、mysql主从复制原理
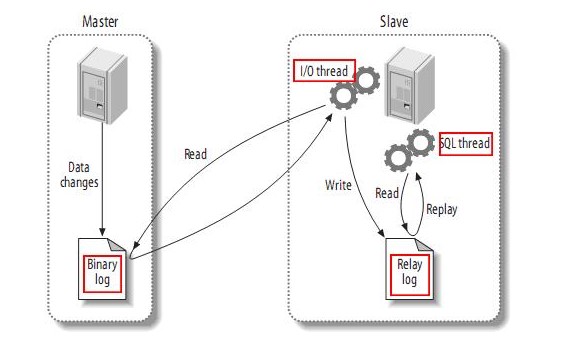
-
主库db的更新事件(update、insert、delete)被写到binlog
-
主库创建一个binlog dump thread,把binlog的内容发送到从库
-
从库启动并发起连接,连接到主库
-
从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log
-
从库启动之后,创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db
二、springboot项目多数据源配置,实现读写分离
-
1、主从多数据源配置
-
yml配置
server:
port: 8888
servlet:
encoding:
charset: UTF-8
force: true
enabled: true
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3307/test?serverTimezone=GMT%2B8&characterEncoding=utf-8&autoReconnect=true&failOverReadOnly=false&useSSL=false
username: root
password: 654321
slave:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3308/test?serverTimezone=GMT%2B8&characterEncoding=utf-8&autoReconnect=true&failOverReadOnly=false&useSSL=false
username: root
password: 654321
- 数据源配置
/**
- @author cgg
**/
@Configuration
@EnableTransactionManagement
public class DynamicDataSourceConfig {
@Bean(name = “slaveDatasource”)
@ConfigurationProperties(prefix = “slave.datasource”)
public DataSource dbSlave() {
return DruidDataSourceBuilder.create().build();
}
@Bean(name = “dataSource”)
@ConfigurationProperties(prefix = “spring.datasource”)
public DataSource dbMaster() {
return DruidDataSourceBuilder.create().build();
}
@Bean
@Primary
public DataSource multipleDataSource(@Qualifier(“dataSource”) DataSource db,
@Qualifier(“slaveDatasource”) DataSource slaveDatasource) {
DynamicDataSource dynamicDataSource = new DynamicDataSource();
Map<Object, Object> targetDataSources = new HashMap<>(16);
targetDataSources.put(“dataSource”, db);
targetDataSources.put(“slaveDatasource”, slaveDatasource);
dynamicDataSource.setTargetDataSources(targetDataSources);
//设置默认数据源为从库,如果写操作业务多,可以默认设置为主库
dynamicDataSource.setDefaultTargetDataSource(slaveDatasource);
return dynamicDataSource;
}
@Bean(“sqlSessionFactory”)
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

面试资料整理汇总


这些面试题是我朋友进阿里前狂刷七遍以上的面试资料,由于面试文档很多,内容更多,没有办法一一为大家展示出来,所以只好为大家节选出来了一部分供大家参考。
面试的本质不是考试,而是告诉面试官你会做什么,所以,这些面试资料中提到的技术也是要学会的,不然稍微改动一下你就凉凉了
在这里祝大家能够拿到心仪的offer!
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
src=“https://img-blog.csdnimg.cn/img_convert/a08dbe2576ca7d316918196fb4b3ed23.jpeg” alt=“img” style=“zoom: 33%;” />
面试资料整理汇总
[外链图片转存中…(img-BDv23Tzu-1713406321344)]
[外链图片转存中…(img-KxrrF8ZO-1713406321344)]
这些面试题是我朋友进阿里前狂刷七遍以上的面试资料,由于面试文档很多,内容更多,没有办法一一为大家展示出来,所以只好为大家节选出来了一部分供大家参考。
面试的本质不是考试,而是告诉面试官你会做什么,所以,这些面试资料中提到的技术也是要学会的,不然稍微改动一下你就凉凉了
在这里祝大家能够拿到心仪的offer!
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 90
90

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









