







定时获取微博热搜数据
爬虫仅限于知识学习,本代码不得用于任何商业活动侵权,如有不适,请联系博主进行修改或者删除。
1、目标网站
目标链接:https://s.weibo.com/
目标内容:
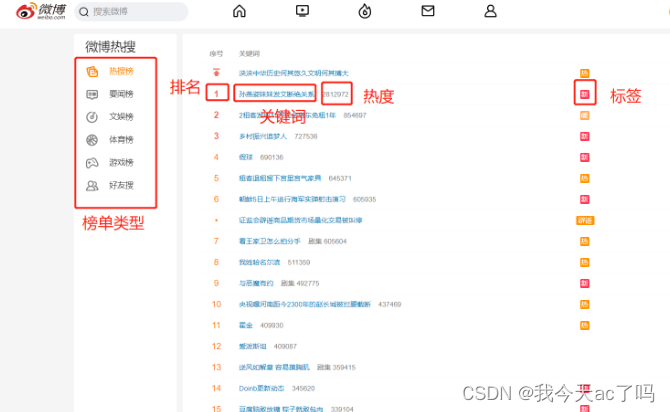
2、图文分析流程
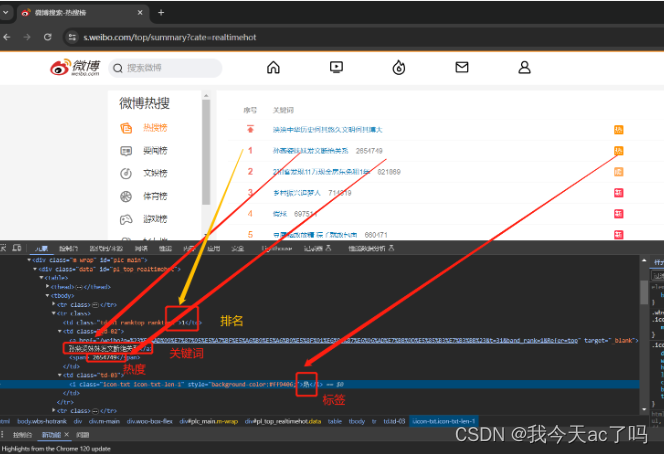
找到目标接口
首先按住F12或者鼠标右键打开控制台,并且刷新一下,找到目标接口
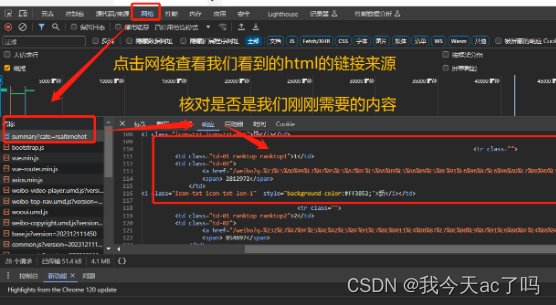
接着点击网络,查找对应的链接
Copy刚刚查到的的Crul链接
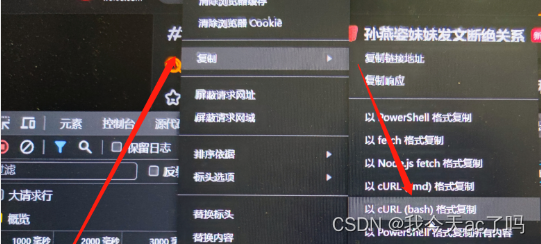
点击Copy as cUrl(bash)内容→将复制的内容到工具转化网站:https://tool.lu/curl/ ,然后点击生成Python
测试复制出来的代码是否能够正常运行
import requests
cookies = {
'SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9W5-JJ8oga5ydhsGdj6kPdLS',
'SINAGLOBAL': '2419051227691.933.1677488001840',
'SUB': '_2AkMT3bncf8NxqwJRmfwSz2jkbYx1yA3EieKlgUgHJRMxHRl-yT9vqnwztRB6OF2XMwOkUv-6XZ3uR9ZU--4KakhG2S91',
'UOR': ',,www.baidu.com',
'_s_tentry': '-',
'Apache': '894723423235.0753.1693625742494',
'ULV': '1693625742512:3:1:2:894723423235.0753.1693625742494:1693462317344',
}
headers = {
'authority': 's.weibo.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
# Requests sorts cookies= alphabetically
# 'cookie': 'SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9W5-JJ8oga5ydhsGdj6kPdLS; SINAGLOBAL=2419051227691.933.1677488001840; SUB=_2AkMT3bncf8NxqwJRmfwSz2jkbYx1yA3EieKlgUgHJRMxHRl-yT9vqnwztRB6OF2XMwOkUv-6XZ3uR9ZU--4KakhG2S91; UOR=,,www.baidu.com; _s_tentry=-; Apache=894723423235.0753.1693625742494; ULV=1693625742512:3:1:2:894723423235.0753.1693625742494:1693462317344',
'pragma': 'no-cache',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
}
response = requests.get('https://s.weibo.com/top/summary', cookies=cookies, headers=headers)
print(response.text[:1000])

链接规律
我们可以发现不同的榜care对应的东西不同。
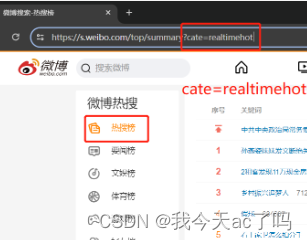
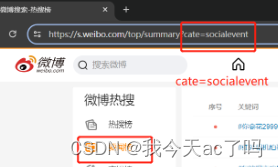
以此类推我们可以发现各个榜单的规律: "realtimehot": "热搜榜"``````"socialevent": "要闻榜"``````entrank": "文娱榜"``````"sport": "体育榜"``````"game": "游戏榜"从而可以写出的代码
params_type = {
"realtimehot": "热搜榜",
"socialevent": "要闻榜",
"entrank": "文娱榜",
"sport": "体育榜",
"game": "游戏榜",
}
for param, type_name in params_type.items():
print(type_name, f'https://s.weibo.com/top/summary?cate={param}')
完整爬虫代码
"""
Time: 2024/4/1 19:31
Author: 我今天ac了吗
Version: V 0.1
File: 微博热搜
Describe:
"""
import time
import requests
from lxml import etree
from apscheduler.schedulers.blocking import BlockingScheduler
scheduler = BlockingScheduler(timezone='Asia/Shanghai')
@scheduler.scheduled_job('interval', start_date='2024-04-01 12:00:00', minutes=10)
def main():
cookies = {
'SUBP': '0033WrSXqPxfM72-Ws9jqgMF55529P9D9W5-JJ8oga5ydhsGdj6kPdLS',
'SINAGLOBAL': '2419051227691.933.1677488001840',
'SUB': '_2AkMT3bncf8NxqwJRmfwSz2jkbYx1yA3EieKlgUgHJRMxHRl-yT9vqnwztRB6OF2XMwOkUv-6XZ3uR9ZU--4KakhG2S91',
'_s_tentry': 'www.baidu.com',
'UOR': ',,www.baidu.com',
'Apache': '2496342533892.1196.1693462317330',
'ULV': '1693462317344:2:1:1:2496342533892.1196.1693462317330:1677488001962',
}
headers = {
'authority': 's.weibo.com',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'referer': 'https://s.weibo.com/top/summary?cate=socialevent',
'sec-ch-ua': '"Chromium";v="116", "Not)A;Brand";v="24", "Google Chrome";v="116"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36',
}
params_type = {
"realtimehot": "热搜榜",
"socialevent": "要闻榜",
"entrank": "文娱榜",
"sport": "体育榜",
"game": "游戏榜",
}
for param, type_name in params_type.items():
params = {
'cate': param,
}
response = requests.get('https://s.weibo.com/top/summary', params=params, cookies=cookies, headers=headers)
html_text = etree.HTML(response.text)
trs = html_text.xpath('//*[@class="data"]/table/tbody/tr')
ranking = 0
for tr in trs[1:]:
ranking += 1
result = {
'榜单类型': type_name,
'排名': ranking,
'关键词': ''.join(tr.xpath('./td[2]/a/text()')),
'链接': 'https://s.weibo.com/' + ''.join(tr.xpath('./td[2]/a/@href')),
'热度': ''.join(tr.xpath('./td[2]/span/text()')),
'热度标签': ''.join(tr.xpath('./td[3]/i/text()')),
'爬取时间': time.time(),
}
print(result)
print(" ")
if __name__ == '__main__':
main()
pass
try:
scheduler.start()
except (KeyboardInterrupt, SystemExit):
scheduler.shutdown()
运行结果



















 364
364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









