







 本文介绍了AI科技圈近期的热点,如大模型面试题集锦,包括自我介绍、技术问题(如Transformer、LoRA等)、LeetCode挑战,以及阿里巴巴的Qwen1.5和苹果的OpenELM小模型。提供面试准备指南和新模型性能对比。
本文介绍了AI科技圈近期的热点,如大模型面试题集锦,包括自我介绍、技术问题(如Transformer、LoRA等)、LeetCode挑战,以及阿里巴巴的Qwen1.5和苹果的OpenELM小模型。提供面试准备指南和新模型性能对比。
大家好,今天我们继续聊聊最近 AI 科技圈的大模型、论文、面试题。更多技术交流可以文末加入我们社群。
喜欢本文,记得点赞、收藏、关注。
1、面试题
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:《大模型面试宝典》(2024版) 正式发布!
最近一位星球成员向我咨询要不要去小米汽车,说自己有点犹豫,纠结点是每天几乎10点之后下班,说不太稳定。
虽然拿到了小米汽车的 offer,内心还是很纠结,最后这位同学拒了小米汽车的offer。
今天我把面试题总结一下分享出来。希望对找工作的小伙伴有帮助。
1)自我介绍
2)技术问题
- 2.1 self-attention 的计算方式?
- 2.2 说一下 transformer 的模型架构和细节?
- 2.3 说一下大模型高校参数微调方式 p-tuning v2?
- 2.4 在 大模型任务中,你用到 LoRA,讲一下 LoRA 实现原理?
- 2.5 你知道为什么现在的大语言模型都采用Decoder only架构么?
- 2.6 为什么大模型进行SFT后,LLM不升反降呢?
- 2.7 Transformer为何使用多头注意力机制
- 2.8 lora的矩阵怎么初始化?为什么要初始化为全0?
- 2.9 ZeRO,零冗余优化器的三个阶段?
- 2.8 介绍一下 stable diffusion 的原理
- 2.9 Stable Diffusion 里是如何用文本来控制生成的?
- 2.10 Stable Diffusion相比Diffusion主要解决的问题是什么?
- 2.11 介绍一下 CLIP
- 2.12 VAE和VQ-VAE的区别
- 2.13 VAE公式推导了解吗
- 2.14 对比损失怎么计算的?
3) Leetcode 题
- 数组中的第K个最大元素
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
要求必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
2、Qwen 1.5-110B
近日,阿里发布了 Qwen1.5 系列的首个千亿参数开源模型:Qwen1.5-110B。

- Github:
https://github.com/QwenLM/Qwen1.5 - HF:
https://huggingface.co/Qwen/Qwen1.5-110B-Chat
Qwen1.5 系列介绍
Qwen1.5 是一个语言模型系列,包括不同模型大小的解码器语言模型。对于每个大小,均有基础语言模型和对齐的聊天模型。
模型基于 Transformer 架构,具有 SwiGLU 激活、注意力 QKV 偏置、组查询注意力、滑动窗口注意力和全注意力的混合等特性。
此外,还有一种改进的分词器,适用于多种自然语言和代码。
快速入门
分享一个 Qwen1.5-110B-Chat 代码片段,使用 apply_chat_template 来展示如何加载分词器和模型,以及如何生成内容。
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen1.5-110B-Chat",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen1.5-110B-Chat")
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
模型效果
Qwen 1.5-110B 与最近的 SOTA 语言模型 Meta-Llama3-70B 以及 Mixtral-8x22B 进行了比较。
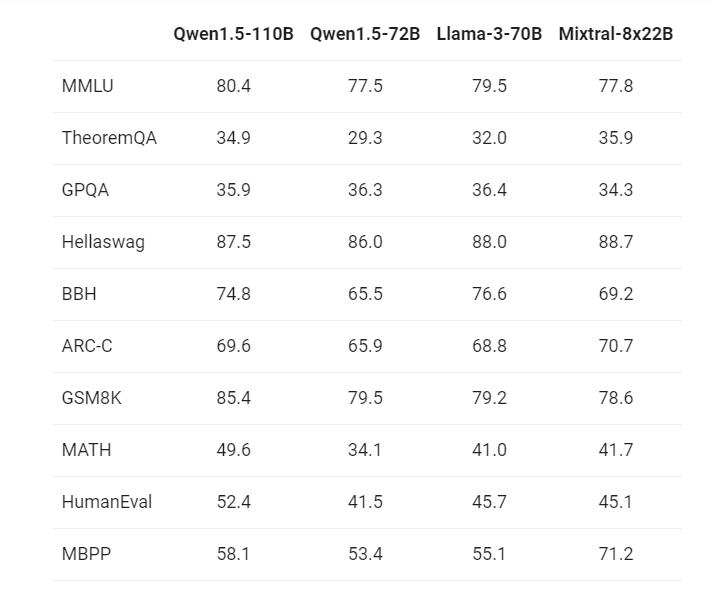
新的110B模型在基础能力方面至少与Llama-3-70B模型相媲美。
3、苹果发布 OpenELM
从 Llama 3 到 Phi-3,蹭着开源热乎劲儿,苹果也来搞事情了。
近日,苹果团队发布了OpenELM,包含了2.7亿、4.5亿、11亿和30亿四个参数版本。
与微软刚刚开源的Phi-3相同,OpenELM 是一款专为终端设备而设计的小模型。

- 论文:
https://arxiv.org/pdf/2404.14619 - hf:
https://huggingface.co/apple/OpenELM
OpenELM使用分层缩放策略,来有效分配Transformer模型每一层参数,从而提升准确率。
如下这张图,一目了然。
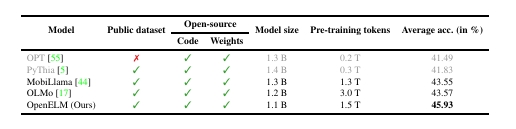
在约10亿参数规模下,OpenELM与OLMo相比,准确率提高了2.36%,同时需要的预训练token减少了2倍。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









