







pool of square window of size=3, stride=2
m = nn.MaxPool2d(3,stride = 2)
pool of non-square window
m = nn.MaxPool2d((3, 2), stride=(2, 1))
input = torch.randn(20, 16, 50, 32)
output = m(input)
-
nn.AvgPool2d(kernel_size,stride):这里列举了常用的几个参数,其余省略了
-
kernel_size(int or tuple):池化窗口size
-
stride(int or tuple):池化的步长
-
padding(int or tuple):池化的填充,默认为0
-
案例
pool of square window of size=3, stride=2
m = nn.AvgPool2d(3, stride=2)
pool of non-square window
m = nn.AvgPool2d((3, 2), stride=(2, 1))
input = torch.randn(20, 16, 50, 32)
output = m(input)
-
nn.Linear(in_features, out_features, bias)
-
in_features:输入特征数
-
out_features:输出特征数
-
bias:偏置
-
案例
m = nn.Linear(20, 30)
input = torch.randn(128, 20)
output = m(input)
print(output.size())
torch.Size([128, 30])
二、案例+相关代码注释
在这之前,首先我们需要了解一下PyTorch中已经给我们准备好的网络模型nn.Module。我们自己定义的网络模型只需要继承nn.Module,并实现它的forward()方法,PyTorch会根据Autograd,自动实现backward()函数,在forward函数中我们可以使用任何Tensor支持的函数,还可以使用if、for、print等Python语法,写法与标准Python写法是一致的。
class Net(nn.Module):
def init(self):
nn.Module子类的函数必须在构造函数中执行父类的构造函数
super(Net, self).init()
卷积层 '1’表示输入图片为单通道, '6’表示输出通道数,'3’表示卷积核为3*3
self.conv1 = nn.Conv2d(1, 6, 3)
#线性层,输入1350个特征,输出10个特征
self.fc1 = nn.Linear(1350, 10) #这里的1350是如何计算的呢?这就要看后面的forward函数
#正向传播
def forward(self, x):
print(x.size()) # 结果:[1, 1, 32, 32]
卷积 -> 激活 -> 池化
x = self.conv1(x) #根据卷积的尺寸计算公式,计算结果是30,具体计算公式后面第二章第四节 卷积神经网络 有详细介绍。
x = F.relu(x)
print(x.size()) # 结果:[1, 6, 30, 30]
x = F.max_pool2d(x, (2, 2)) #我们使用池化层,计算结果是15
x = F.relu(x)
print(x.size()) # 结果:[1, 6, 15, 15]
reshape,‘-1’表示自适应
#这里做的就是压扁的操作 就是把后面的[1, 6, 15, 15]压扁,变为 [1, 1350]
x = x.view(x.size()[0], -1)
print(x.size()) # 这里就是fc1层的的输入1350
x = self.fc1(x)
return x
net = Net()
print(net)
- 运行结果
Net(
(conv1): Conv2d(1, 6, kernel_size=(3, 3), stride=(1, 1))
(fc1): Linear(in_features=1350, out_features=10, bias=True)
)
- 网络的可学习参数通过net.parameters()返回
for parameters in net.parameters():
print(parameters)
- 运行结果
Parameter containing:
tensor([[[[ 0.2745, 0.2594, 0.0171],
[ 0.0429, 0.3013, -0.0208],
[ 0.1459, -0.3223, 0.1797]]],
[[[ 0.1847, 0.0227, -0.1919],
[-0.0210, -0.1336, -0.2176],
[-0.2164, -0.1244, -0.2428]]],
[[[ 0.1042, -0.0055, -0.2171],
[ 0.3306, -0.2808, 0.2058],
[ 0.2492, 0.2971, 0.2277]]],
[[[ 0.2134, -0.0644, -0.3044],
[ 0.0040, 0.0828, -0.2093],
[ 0.0204, 0.1065, 0.1168]]],
[[[ 0.1651, -0.2244, 0.3072],
[-0.2301, 0.2443, -0.2340],
[ 0.0685, 0.1026, 0.1754]]],
[[[ 0.1691, -0.0790, 0.2617],
[ 0.1956, 0.1477, 0.0877],
[ 0.0538, -0.3091, 0.2030]]]], requires_grad=True)
Parameter containing:
tensor([ 0.2355, 0.2949, -0.1283, -0.0848, 0.2027, -0.3331],
requires_grad=True)
Parameter containing:
tensor([[ 2.0555e-02, -2.1445e-02, -1.7981e-02, …, -2.3864e-02,
8.5149e-03, -6.2071e-04],
[-1.1755e-02, 1.0010e-02, 2.1978e-02, …, 1.8433e-02,
7.1362e-03, -4.0951e-03],
[ 1.6187e-02, 2.1623e-02, 1.1840e-02, …, 5.7059e-03,
-2.7165e-02, 1.3463e-03],
…,
[-3.2552e-03, 1.7277e-02, -1.4907e-02, …, 7.4232e-03,
-2.7188e-02, -4.6431e-03],
[-1.9786e-02, -3.7382e-03, 1.2259e-02, …, 3.2471e-03,
-1.2375e-02, -1.6372e-02],
[-8.2350e-03, 4.1301e-03, -1.9192e-03, …, -2.3119e-05,
2.0167e-03, 1.9528e-02]], requires_grad=True)
Parameter containing:
tensor([ 0.0162, -0.0146, -0.0218, 0.0212, -0.0119, -0.0142, -0.0079, 0.0171,
0.0205, 0.0164], requires_grad=True)
- net.named_parameters可同时返回可学习的参数及名称。
for name,parameters in net.named_parameters():
print(name,‘:’,parameters.size())
- 我们来简单测试一下:注意forward函数的输入和输出都是Tensor
input = torch.randn(1, 1, 32, 32) # 这里的对应前面fforward的输入是32
out = net(input)
out.size()
- 在反向传播前,先要将所有参数的梯度清零
net.zero_grad()
out.backward(torch.ones(1,10)) # 反向传播的实现是PyTorch自动实现的,我们只要调用这个函数即可
注意: torch.nn只支持mini-batches,不支持一次只输入一个样本,即一次必须是一个batch。
也就是说,就算我们输入一个样本,也会对样本进行分批,所以,所有的输入都会增加一个维度,我们对比下刚才的input,nn中定义为3维,但是我们人工创建时多增加了一个维度,变为了4维,最前面的1即为batch-size。
三、优化器optim
在反向传播计算完所有参数的梯度后,还需要使用优化方法来更新网络的权重和参数。这里只简单介绍优化方法。
| 优化方法 | 优化更新策略 |
| — | — |
| SGD随机梯度下降法 |  |
|
| | |
| 带有Momentum的随机梯度下降法 | 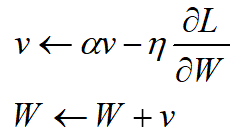 |
|
| | |
| Adagrad | 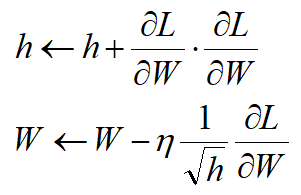 |
|
| | |
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Java开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
[外链图片转存中…(img-tHKHDDs5-1715876583829)]
[外链图片转存中…(img-PVSsZd7S-1715876583830)]
[外链图片转存中…(img-wDlySA5W-1715876583830)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Java开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!















 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









