






目录
这是一种关联分析算法,用于发现数据中的频繁项集和关联规则,常用于购物篮分析等场景。
1举个栗子
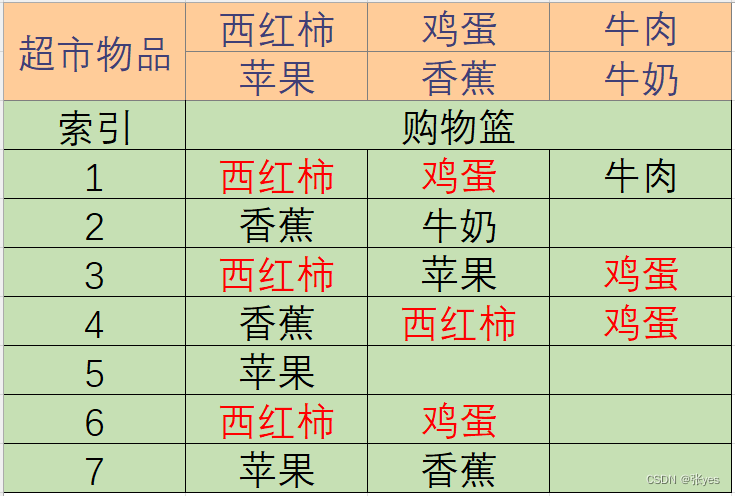
每个行对应每一个顾客所购买的商品,可以看到鸡蛋和西红柿商品有很大可能机会成对出现,这里就提示我们,这是不是一个偶然的事情?(当然不是,西红柿炒鸡蛋是很平常的一道菜,成对购买是很合乎情理的)
那么受这个事情的启发,能不能将西红柿和鸡蛋放到超市货架上相互靠近的位置呢?
那么,诸如此类事情,我们能不能也找到"鸡蛋"->"西红柿"这种依赖关系,这个例子是较为显然的,并且数据量很小.我们能不能设计一种算法,去对"西红柿和鸡蛋"这种潜在关联进行分析?
这里我们就能提出来一系列问题:
究竟哪些数据之间有关联性?
这种关联性如何进行描述?
给定"购物篮数据"能不能设计算法,对购物篮商品进行关联分析?
算法的出现和发展:我个人认为关键在于一个符号化,量化:
Step1:研究明白我们的问题,具体化我们的问题,对某些事情尽情量化处理
Step2:我们能够获得的是什么(问题给出的时候,给我们的已知条件)
Step3:我们需要得到的是什么(我们是要得到什么:最大化一个目标?还是寻找一种关系?)
2量化,符号化
我们从"购物篮"这种十分具体的例子出发:
Step1:我们的问题是对购物篮中商品之间的潜在关联进行分析
Step2:我们能够获得的是超市所有的商品,第i个购物篮中的所有商品
Step3:找到一种关系,即购物篮当中,两种或多种"不相交"的商品之间的"依赖"关系
很明显,我们要对"购物篮"进行量化,符号化:
(1)引入项集和K-项集的概念:
令I={i1,i2,i3……id}是购物篮数据中所有项的集合,而T={t1,t2,t3….tN}是所有事务的集合,每个事务ti包含的项集都是I的子集。在关联分析中,包含0个或多个项的集合称为项集。如果一个项集包含K个项,则称它为K-项集。空集是指不包含任何项的项集。
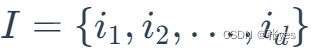
![]()
(2)支持度计数
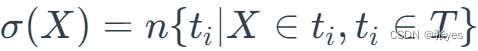
满足条件中的集合中的元素个数
(3)关联规则
支持度:
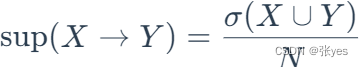

置信度:
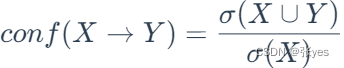
不要感觉这两个公式难以理解,这其实是很正常的两个公式.
支持度,顾名思义,用于支撑X->Y这个关联的概率,是项集中同时拥有(X,Y)这个样本的数量与全样本数量的比值
置信度,让我们对X->Y这个关联的信任,是包含X的项集中同时拥有Y这个样本的数量的比值
这是很自然的两个公式
(4)关联规则的发现
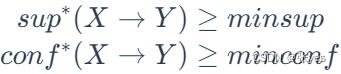
找到满足 支持度和置信度不小于提前给定的阈值 的规则 X->Y
由以上的分析,关联规则挖掘的思路便展现出来了:
(1)逐层搜索的迭代方法
频繁数据集的产生:产生的目标是发现满足最小支持度阈值的所有顶级这些项集称为频繁项集
(2)频繁项集产生关联规则
规则的产生:从上一步发现的平凡集中提取的所有高置信度的规则这些规则称为强规则
3关联规则挖掘
关联规则挖掘第一步实现:
关于Apriori性质:
频繁项集的所有非空子集都必须是频繁的
因为如果I不满足最小支持条件,则加入任意项A都不能满足最小支持条件(如下所示):
这个性质叫做反单调性质
可以得到如果一个集合不能通过测试则它的所有超集都不能通过测试
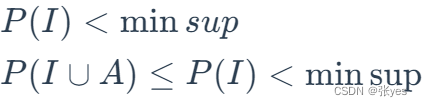
3.1Apriori算法
(基于候选项集去找频繁项集的一个算法,逐层搜索的迭代算法)分为两步:
第一步是找出频繁1-项集的集合该集合记为L1,L1用于找频繁2-项集,记为L2.而L2用于找L3如此下去直到不能找到频繁K项集为止.找到每一个Li需要对数据库进行一次扫描所以它的复杂度是非常高的
连接步:I1和I2是L(k-1)的项集进行合并,不重复的单拿出来进行补足
剪枝步:剪枝步是把非频繁节点删除,其不参与迭代过程
3.2关联规则挖掘第二步实现
由频繁项集产生关联规则:
由频繁项集产生关联规则的话
(1)对于每个频繁项集I,产生的I的所有非空子集
(2)对于I的每个非空子集s,如果对于
实质上公式是:
这样就能找到输出规则S到I-S的输出规则
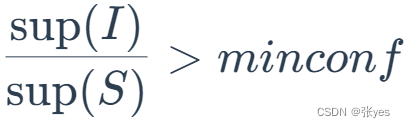
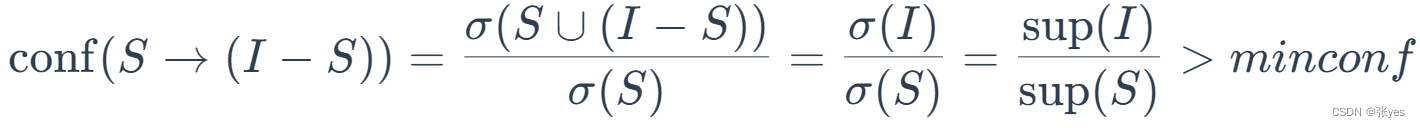

3.3代码实现
from itertools import combinations
'''
扫描数据集,找出所有的频繁1项集(即出现次数大于等于最小支持度阈值的项集)。
基于频繁1项集,生成候选2项集,并扫描数据集,找出所有的频繁2项集。
重复上述步骤,生成候选k项集并找出频繁k项集,直到不能再生成新的频繁项集为止。
根据频繁项集生成关联规则,计算其支持度和置信度。
'''
# 扫描数据集,找出所有的频繁1项集
def find_frequent_1_itemsets(data, min_support):
item_counts = {}
for transaction in data:
for item in transaction:
item_counts[item] = item_counts.get(item, 0) + 1
frequent_1_itemsets = {frozenset([item]): count for item, count in item_counts.items() if count >= min_support}
return frequent_1_itemsets
# 生成候选项集
def generate_candidate_itemsets(prev_frequent_itemsets, k):
candidate_itemsets = set()
for itemset1 in prev_frequent_itemsets:
for itemset2 in prev_frequent_itemsets:
union_set = itemset1.union(itemset2)
if len(union_set) == k:
candidate_itemsets.add(union_set)
return candidate_itemsets
# 扫描数据集,找出所有的频繁项集
def find_frequent_itemsets(data, min_support):
frequent_itemsets = {}
k = 1
frequent_1_itemsets = find_frequent_1_itemsets(data, min_support)
frequent_itemsets.update(frequent_1_itemsets)
while True:
k += 1
candidate_itemsets = generate_candidate_itemsets(frequent_itemsets.keys(), k)
if not candidate_itemsets:
break
item_counts = {itemset: 0 for itemset in candidate_itemsets}
for transaction in data:
for itemset in candidate_itemsets:
if itemset.issubset(set(transaction)):
item_counts[itemset] += 1
frequent_itemsets = {itemset: count for itemset, count in item_counts.items() if count >= min_support}
return frequent_itemsets
# 生成关联规则
def generate_association_rules(frequent_itemsets, min_confidence):
association_rules = []
for itemset in frequent_itemsets.keys():
if len(itemset) > 1:
for i in range(1, len(itemset)):
for antecedent in combinations(itemset, i):
antecedent = frozenset(antecedent)
consequent = itemset - antecedent
confidence = frequent_itemsets[itemset] / frequent_itemsets.get(antecedent, 1)
if confidence >= min_confidence:
association_rules.append((antecedent, consequent, confidence))
return association_rules
if __name__ == '__main__':
# 示例数据集
data = [
["A", "B", "C"],
["A", "C"],
["B", "D"],
["A", "B", "C", "D"],
["A", "D"]
]
min_support = 2
min_confidence = 0.5
frequent_itemsets = find_frequent_itemsets(data, min_support)
association_rules = generate_association_rules(frequent_itemsets, min_confidence)
for rule in association_rules:
antecedent, consequent, confidence = rule
print(f"{antecedent} => {consequent}, Confidence: {confidence}")4参考文章
关联规则挖掘——Apriori算法的基本原理以及改进-CSDN博客文章浏览阅读5.8w次,点赞59次,收藏285次。问题引入关联规则挖掘发现大量数据中项集之间有趣的关联或者相互联系。关联规则挖掘的一个典型例子就是购物篮分析,该过程通过发现顾客放入其购物篮中不同商品之间的联系,分析出顾客的购买习惯,通过了解哪些商品频繁地被顾客同时买入,能够帮助零售商制定合理的营销策略。购物篮事务的例子如下图所示: 例如:在同一次去超级市场时,如果顾客购买牛奶,同时他也购买面包的可能性有多大? 通过帮助零售商有选择地经销_apriori算法https://blog.csdn.net/zhazhayaonuli/article/details/53322541?spm=1001.2014.3001.5501通俗易懂的Apriori算法-CSDN博客文章浏览阅读1.9w次,点赞31次,收藏85次。Apriori算法一、Apriori算法的简介Apriori算法是第一个关联规则挖掘算法,也是最经典的算法。它利用逐层搜索的迭代方法找出数据库中项集的关系,以形成规则,其过程由连接(类矩阵运算)与剪枝(去掉那些没必要的中间结果)组成。该算法中项集的概念即为项的集合。包含K个项的集合为k项集。项集出现的频率是包含项集的事务数,称为项集的频率。如果某项集满足最小支持度,则称它为频繁项集。这一部分纯属在网上摘抄的,其实我也不知道啥意思。二、Apriori算法论文:这里我就要推荐小伙伴们_apriori算法
https://blog.csdn.net/caechen/article/details/120910229?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171436257016800188536667%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=171436257016800188536667&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-14-120910229-null-null.nonecase&utm_term=apriori%E7%AE%97%E6%B3%95&spm=1018.2226.3001.4450https://blog.csdn.net/qq_40691189/article/details/126962904?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171436257016800188590138%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171436257016800188590138&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~top_click~default-5-126962904-null-null.nonecase&utm_term=apriori%E7%AE%97%E6%B3%95&spm=1018.2226.3001.4450
![]() https://blog.csdn.net/qq_40691189/article/details/126962904?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171436257016800188590138%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171436257016800188590138&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~top_click~default-5-126962904-null-null.nonecase&utm_term=apriori%E7%AE%97%E6%B3%95&spm=1018.2226.3001.4450
https://blog.csdn.net/qq_40691189/article/details/126962904?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171436257016800188590138%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171436257016800188590138&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~top_click~default-5-126962904-null-null.nonecase&utm_term=apriori%E7%AE%97%E6%B3%95&spm=1018.2226.3001.4450















 2743
2743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









