






 本文介绍了如何使用Python的requests库、re库和csv库构建一个简单的静态网络爬虫,以爬取百度贴吧的评论信息。作者详细讲解了爬虫的实现方法,包括异常处理和数据存储,并分享了实验过程中的一些思考和拓展设想。
本文介绍了如何使用Python的requests库、re库和csv库构建一个简单的静态网络爬虫,以爬取百度贴吧的评论信息。作者详细讲解了爬虫的实现方法,包括异常处理和数据存储,并分享了实验过程中的一些思考和拓展设想。
一、实验目的
1. 掌握requests库、re库、csv库的使用。
2. 掌握正则表达式的基本操作。
二、实验内容
随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。网络爬虫分为静态网络爬虫和动态网络爬虫,本实验将完成一个简单的静态网络爬虫。本实验要求完成任务:
使用requests库、re库、csv库编写爬虫程序,完成百度贴吧某网页的爬取,获得评论内容、评论用户和评论时间内容,并保存为一个csv文件。
运行环境:PyCharm 2023.3.4 Python 3.10
任务基本操作:
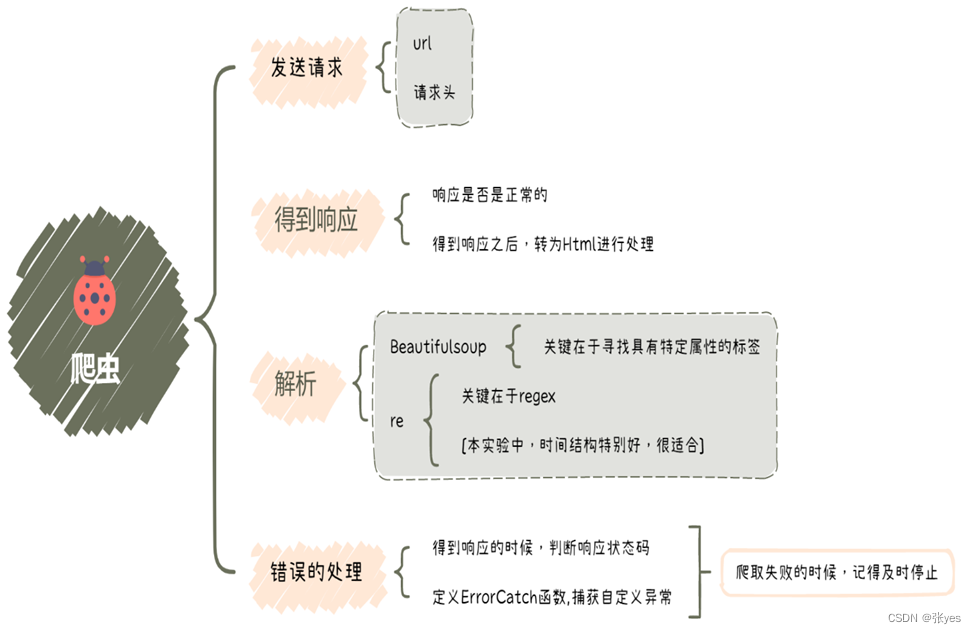 |
| 图1:任务流程图 |
四 、实验结果
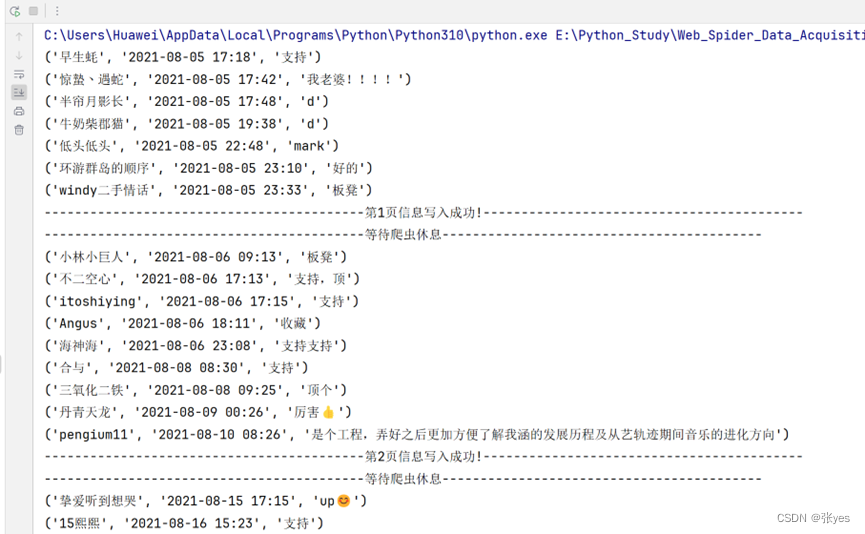 |
| 图2: shell结果截图(部分展示) |
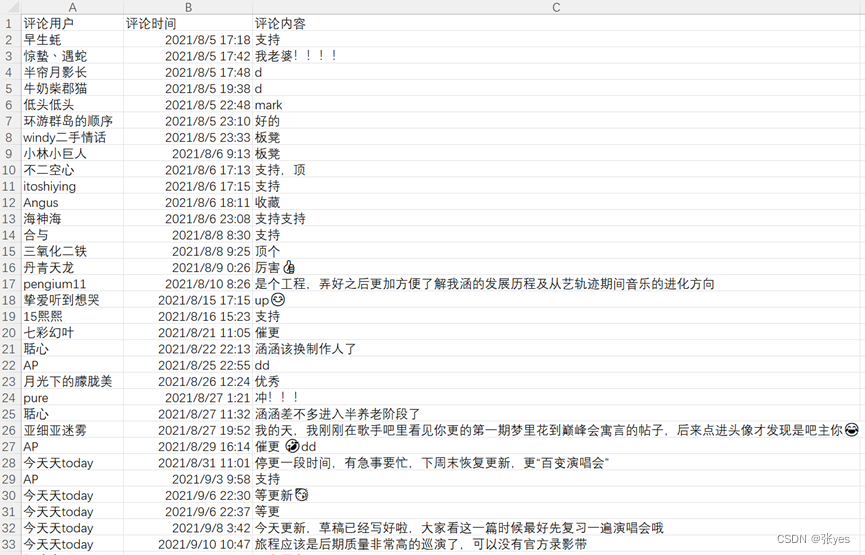 |
| 图3:生成的csv文件的截图(部分展示) |
五、源程序清单
# TODO 1 导包
import requests # 导入requests库,用于发送HTTP请求
from bs4 import BeautifulSoup # 导入BeautifulSoup库,用于解析HTML内容
import re # 导入re库,用于正则表达式匹配
import csv # 导入csv库,用于处理CSV文件
import time # 导入time库,用于添加延时
# TODO 2 匹配模板,爬取网站,获取响应
# 自定义函数捕捉异常
def ErrorCatch(item, name: str):
"""
简单的处理异常函数
:param item: 判断的可迭代对象是否为空值
:param name: 由于users times comments 异常处理步骤一样,这里将第二个参数作为标识符,用于判断究竟是哪一个环节出错
:return: 如果没有报错,这里没有返回值。有报错的,这里会简单输出错误的类型
"""
try:
if not item:
raise Exception(f"No {name} found in the soup") # 抛出自定义异常
except Exception as e:
# 处理异常情况
print(f"Error while finding {name}:", e)
raise SystemExit # 空的话,直接终止程序,这说明没有爬取成功,需要检查代码
def get_html(page: int):
# 2.1设置请求头,模拟浏览器发送请求
url = f"https://tieba.baidu.com/p/7479999219?pn={page}"
# 构造帖子页面URL,可以观察到,多个页面只有page处在变化
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3',
'Cookie': 'BIDUPSID=21C12561C00723568B70848513B88E9B;PSTM=1659772022; BAIDUID=5B6FA7C95E1865EF1DFE462D54CA761C:FG=1;BD_UPN=12314753;H_WISE_SIDS_BFESS=40009_40207_40212_40216_40294_40291_40287_40286_40080_40364_40352_40301_40368_40374_40317_40403_40397_40416;BDUSS=3Q0ZkpnV05QYWhKV2prT256TExObmVESDhkSEcxc1RHemdKU3ZtbDBETzZVU3RtRVFBQUFBJCQAAAAAAQAAAAEAAAC5FTVm1cV5ZXMwMDEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALrEA2a6xANmT;BDUSS_BFESS=3Q0ZkpnV05QYWhKV2prT256TExObmVESDhkSEcxc1RHemdKU3ZtbDBETzZVU3RtRVFBQUFBJCQAAAAAAQAAAAEAAAC5FTVm1cV5ZXMwMDEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAALrEA2a6xANmT;H_PS_PSSID=40080_40301_40368_40374_40397_40416_40479_40510_40514_40446_60023_60039_60034_60048; BDORZ=FFFB88E999055A3F8A630C64834BD6D0;sugstore=1;H_WISE_SIDS=40080_40301_40368_40374_40397_40416_40479_40510_40514_40446_60023_60039_60034_60048;H_PS_645EC=d5b2nDiVKMyAavU0DP3gMBWJ4Z3DOEEc8EsQ6ub3Hu3P1srZ54sUiZqhNtamsio1nrXhKqN%2BwnQ; delPer=0; BD_CK_SAM=1; PSINO=2; BDSVRTM=0; BAIDUID_BFESS=5B6FA7C95E1865EF1DFE462D54CA761C:FG=1’'
}
# 2.2发送get请求,得到响应
response = requests.get(url=url, headers=headers)
# 2.3异常处理
try:
response.raise_for_status() # 如果响应状态码不为2xx,会抛出HTTPError异常
except requests.exceptions.RequestException as e:
# 处理异常情况
print("Error fetching URL:", e)
except Exception as e:
print("Response code:", response.status_code)
# 打印状态码
raise SystemExit
# 2.4获取响应文本
html = response.text
# TODO 3 解析数据
soup = BeautifulSoup(html, "html.parser") # 使用BeautifulSoup解析HTML内容
# 因为BeautifulSoup类不仅能够解析html,还可以解析别的内容,所以这里指定解析器去解析html
# BeautifulSoup类是按照标签进行解析的一种方法,特别高效
# 3.1获取评论用户
users = soup.findAll('a', attrs={'class': "p_author_name j_user_card"}) # 查找评论用户信息
# 可以看到users全部在"class"属性值为"p_author_name j_user_card"的<a>标签里面
# 所以,调用soup对象的findAll方法,找所有的"class"属性值为"p_author_name j_user_card"的<a>标签,返回一个可迭代的对象,赋值给users进行后续操作
ErrorCatch(users, "users") # 处理异常
# 3.2获取评论时间
times = re.findall(r'(\d{4}-\d{2}-\d{2}\s\d{2}:\d{2})', html) # 查找用户的评论时间
# 评论时间都是类似于:2022-8-21 12:20 2022-11-12 12:20
# 使用正则表达式查找评论时间,时间的模板特别固定,直接使用正则表达式匹配,会更加方便
ErrorCatch(times, "times") # 处理异常
# 3.3获取评论内容
comments = soup.findAll('div', attrs={"style": "display:;"}) # 查找评论内容
# 可以看到times全部在"style"属性值为"display:;"的<div>标签里面
# 所以,调用soup对象的findAll方法,找所有的"style"属性值为"display:;"的<div>标签,返回一个可迭代的对象,赋值给times进行后续操作
ErrorCatch(comments, "comments") # 处理异常
# TODO 4 数据写入与存储
for U, T, C in zip(users, times, comments):
# 4.1数据预处理
U = U.text # 获取评论用户 这里使用对象的text属性,如果仍然使用string,有很多内容会被None所代替,这不是我们想要的结果
C = str(C.string)[16:] # 获取评论内容并进行截断处理
# 字符串的切片,考虑到爬出来的数据,前全是空格字符,对字符进行截断操作
# 首先进行类型转换,再进行切片
# 4.2筛选数据
if U is None or len(C) == 0 or C is None:
continue
# 4.3打印评论用户、评论时间、评论内容
print((U, T, C))
# 4.4将数据写入CSV文件
writer.writerow((U, T, C))
# TODO 5 测试
if __name__ == '__main__':
# 5.1创建CSV写入对象
with open("BaiDuWebSpider.csv", 'w', newline='', encoding='utf_8_sig') as f:
writer = csv.writer(f)
# 5.2写入CSV文件头部信息
writer.writerow(("评论用户", "评论时间", "评论内容"))
# 5.3循环爬取
for page in range(1, 21): # 爬取20页内容
get_html(page) # 爬取指定页内容
print(f"---------------第{page}页信息写入成功!---------------")
if page != 20: # 爬取完毕最后一页,不需要休眠,直接跳出就即可
print("------------------等待爬虫休息------------------")
time.sleep(10) # 延时10秒,避免请求过于频繁六、思考及总结
思考(代码解析)
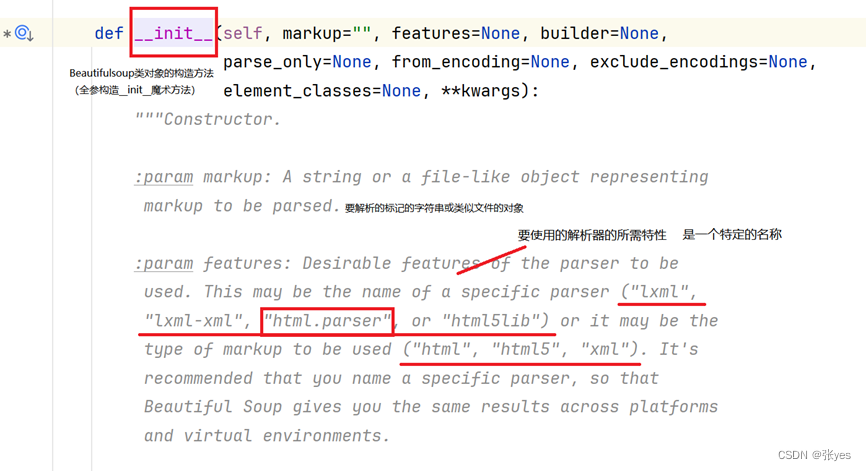 |
| 图4:Beautifulsoup类构造方法 |
使用BeautifulSoup解析H使用BeautifulSoup解析HTML内容,首先要构造bs的类对象,构造类对象的时候,关键要看其__init__魔术方法,这里加入features参数因为BeautifulSoup类不仅能够解析html,还可以解析别的内容,所以这里指定解析器去解析htmlTML内容,首先要构造bs的类对象,构造类对象的时候,关键要看其__init__魔术方法,这里加入features参数因为BeautifulSoup类不仅能够解析html,还可以解析别的内容,所以这里指定解析器去解析html
 |
| 图5:findAll方法的使用解析 |

BeautifulSoup类是按照标签进行解析的一种方法,特别高效。BS类对象里面有丰富的成员方法,概括起来findAll函数(也是find_all)就是通过寻找具有特定属性的标签,对数据进行查询。
如寻找users,可以看到users全部在"class"属性值为"p_author_name j_user_card"的<a>标签里面。所以,调用soup对象的findAll方法,找所有的"class"属性值为"p_author_name j_user_card"的<a>标签,返回一个可迭代的对象,赋值给users进行后续操作。
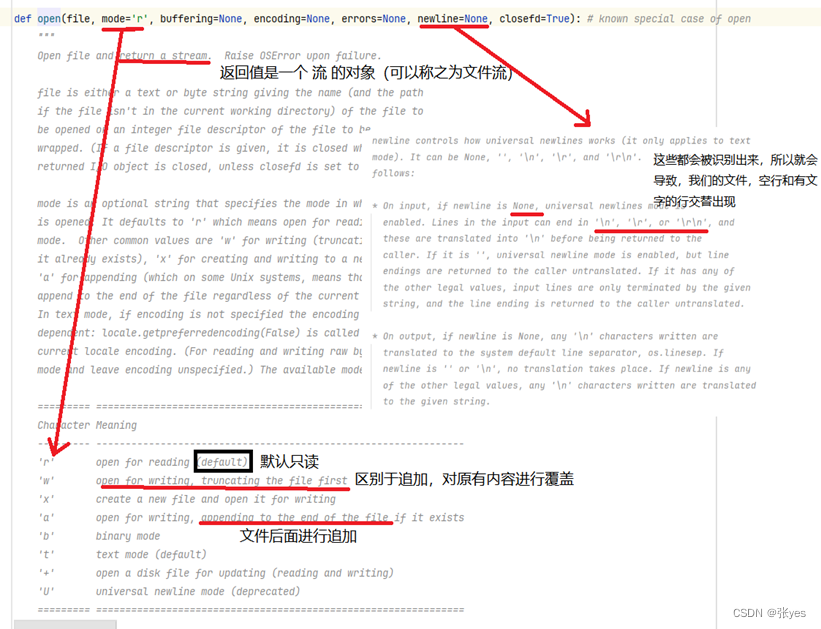 |
| 图6:Open函数使用解析 |
关键这里解析一下newline参数。因为我发现,如果没有去指定该参数,csv文件会出现一行空,一行值。这并不是我想要的。经过对源代码的查询和分析,我认识到了,其默认值为None,所以\n是会被识别出来的,故此,设定参数为空字符串,有效解决了该问题。同时在分析代码的时候,打开文件的mode参数设定为‘w’会更加合理,因为百度贴吧存在反爬,很容易在某次爬取的时候什么都没有爬到。而此时如果紧接着一次爬取爬到内容,两次内容会追加在一起,造成混乱。
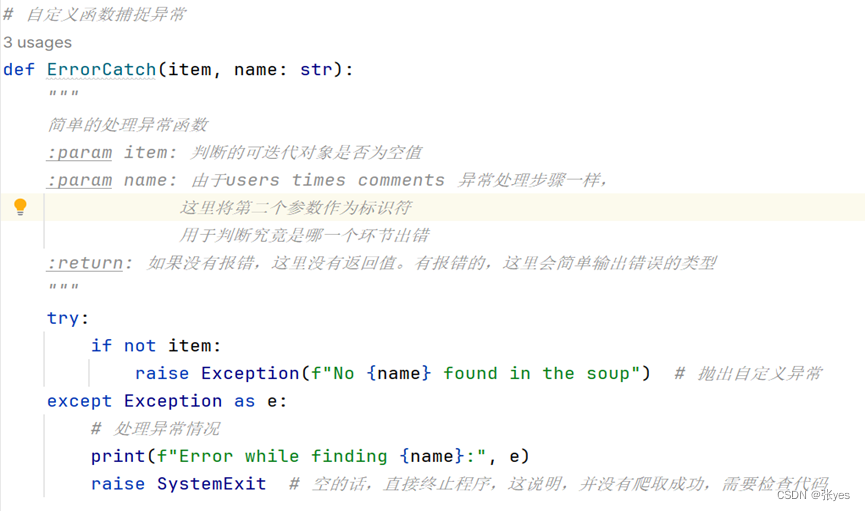 |
| 图7:自定义ErrorCatch处理异常函数使用解析 |
解释一下第二个参数的作用:因为异常出现,我们需要判断究竟是三块那一块出现了问题,而函数的重载增加了代码量,这里增加一个标记参数,便可以实现这个功能
 |
| 图8:ErrorCatch函数起作用的截图 |
总结
 |
| 图9:爬虫的一般步骤 |
BeautifulSoup库方便快捷,指向性强。对于多层的标签嵌套,通过循环的调用findAll方法,就能够实现每一个标签内容的解析等。但是个人认为,该库功能强大,但是对于结构性极强的数据,如日期,时间等,使用正则表达式代码量会更加简洁,也更好理解。所以爬虫是和网站一个斗智斗勇的一个过程,多掌握方法总是没有错的。
一些想法:
能否结合《红楼梦》词云代码结合,生成一个回复内容的词云图?
能否结合多线程和网络编程进行更为强大的爬虫程序的书写?
后续能否结合pyinstaller库,生成一个exe可执行文件?
我想这些都是可以的,总而言之,这次实验让我对python的爬虫有了全新的认识,不再仅仅停留在课本上的理论知识,也了解到了很多反爬有关的规定等等,本次实验课是对我的学习能力和问题解决能力的一次提升。















 2655
2655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









