






目录
前续文章
ID3算法:决策树(Decision Tree)-ID3算法-CSDN博客文章浏览阅读793次,点赞23次,收藏8次。决策树(Decision Tree)-ID3算法https://blog.csdn.net/2401_84069125/article/details/138294371决策树:将数据集用一些”标准”,将样本按照类别分到不同的叶子节点当中.
CART决策树是一个二叉树
CART决策树与ID3算法决策树
CART决策树与ID3算法决策树最大的区别在于:1离散的/连续的 2.用于区分构建的函数不同
算法的出现和发展:我个人认为关键在于一个符号化,量化:
Step1:研究明白我们的问题,具体化我们的问题,对某些事情尽情量化处理
Step2:我们能够获得的是什么(问题给出的时候,给我们的已知条件)
Step3:我们需要得到的是什么(我们是要得到什么:最大化一个目标?还是寻找一种关系?
对于决策树而言:
1我们的问题就是,如何找到这么样的一个树形分类结构,让我们的数据集经过处理后,更加的”纯粹”
2我们获得的是数据(数据的各种特征,以及该数据的类别等特征标签)
3我们需要通过输入数据的特征得到其标签值
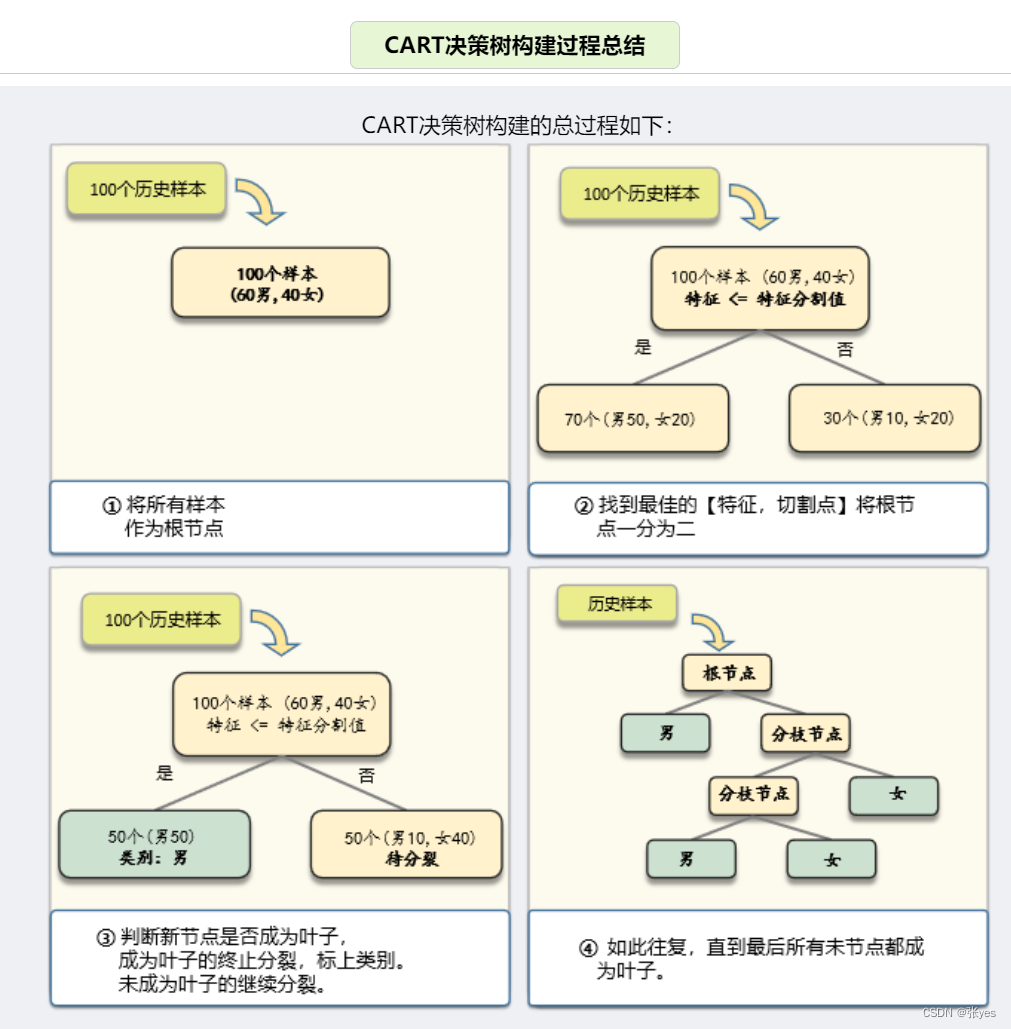
CART决策树的构建
CART决策树的构建,更像是一个树的生成:
步骤如下:
Step1:根节点分裂
Step2:对新生节点的性质进行判断:成为叶子节点?继续分裂?
Step3:不断迭代,直到终止
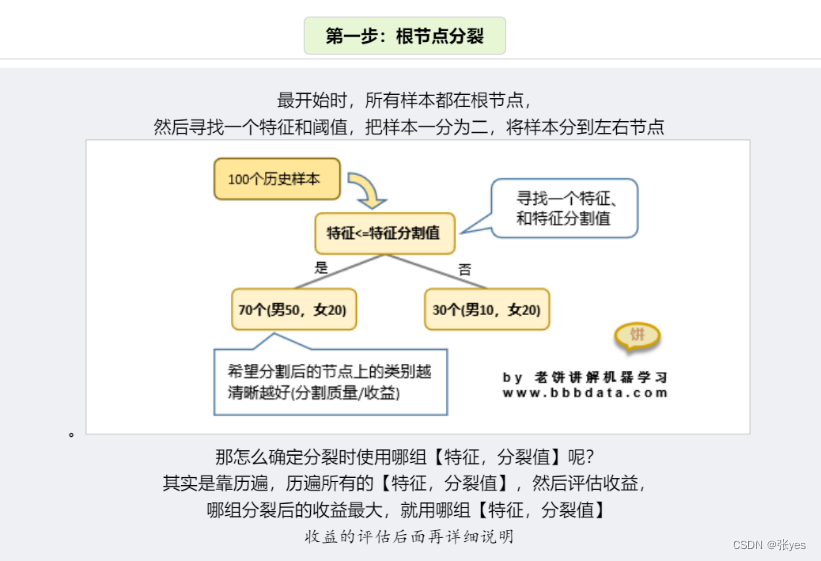
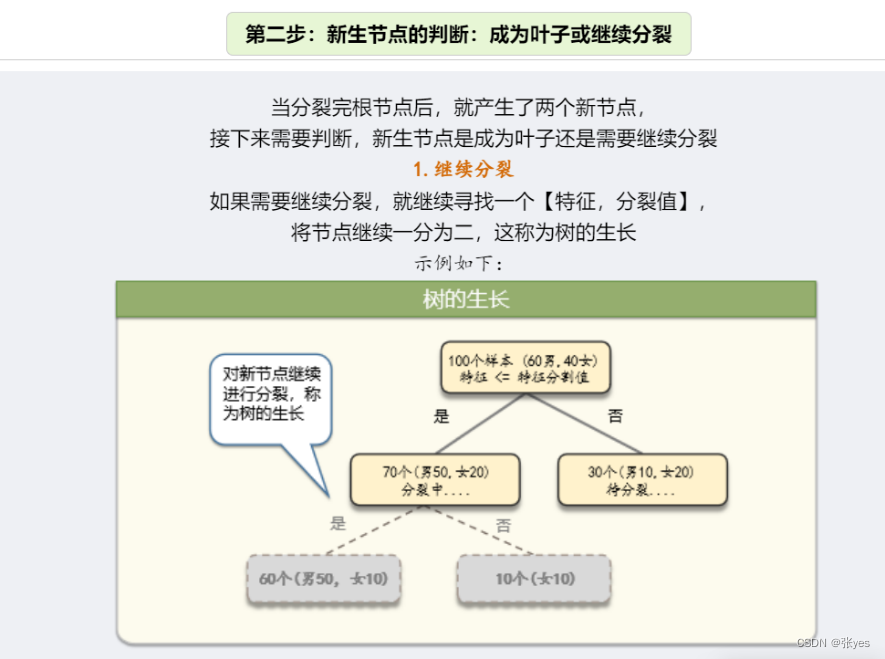
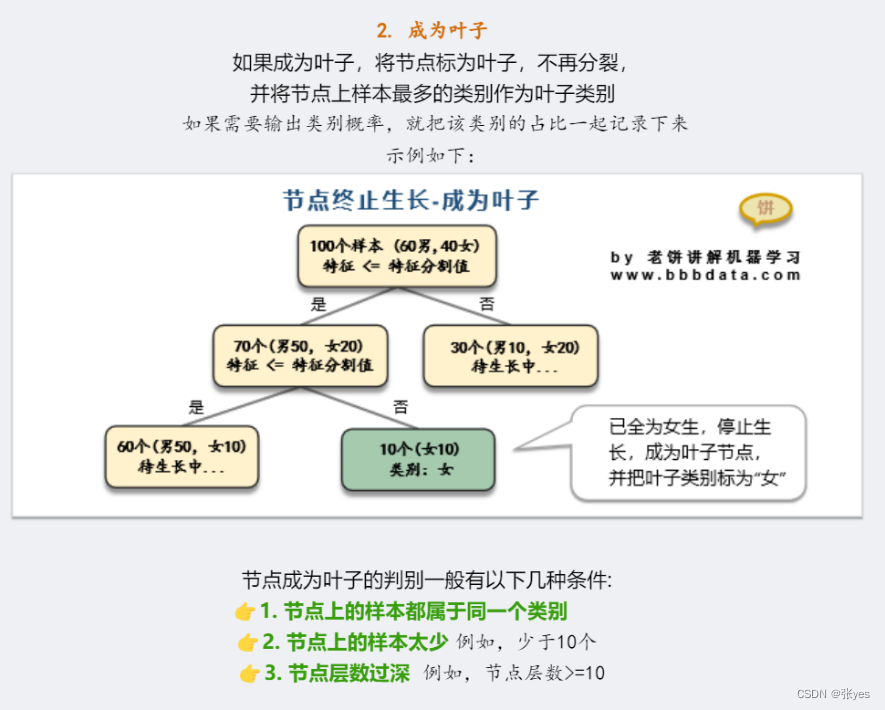
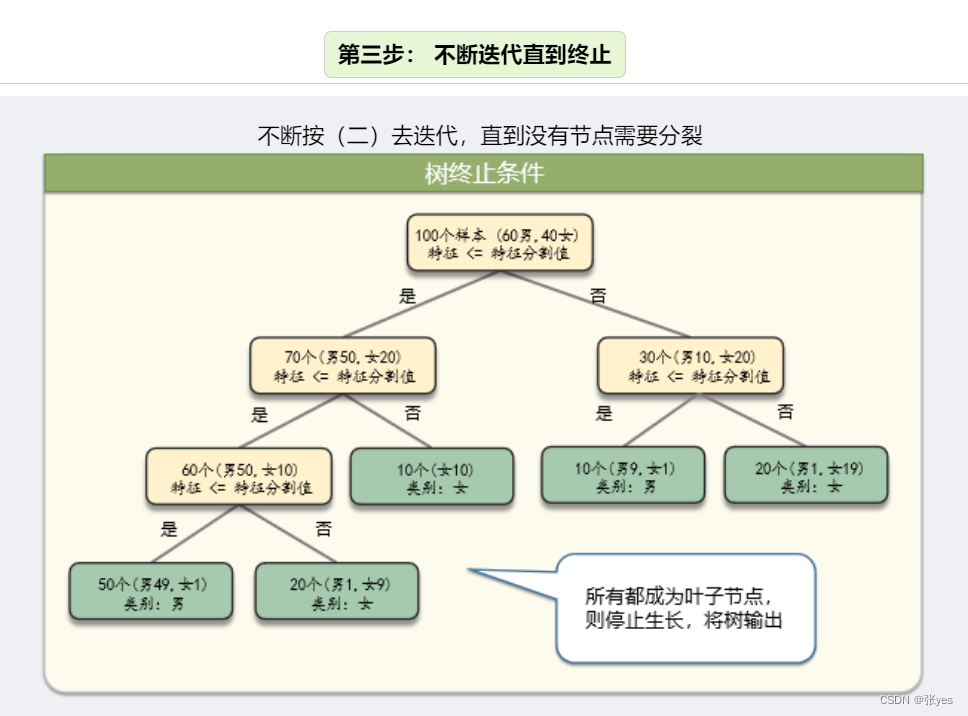
模型推导
定义数据集:D是数据集,(x,y)是元数据,其中x是p维向量,p代表x的各个特征
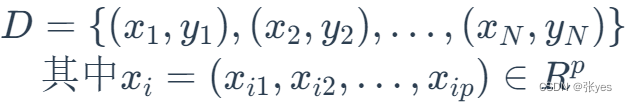
输出的值为离散情况下:
基尼系数/Gini不纯度
(在样本集合当中,一个随机选中的样本(概率为p)被分错的概率(概率为1-p),所以基尼指数为p(1-p))
受这个的启发,对于二叉树而言,一个节点最多只有左右两个孩子节点,我们对根节点记为D,a记作分类的标准,按照分类标准a可以将D分为两部分,定义基于a下的D的基尼系数:
同一个节点,不属同一类的概率越小(即属于同一类的概率越大),说明节点上的杂质越小(也叫纯度越纯),当一个节点的纯度达到最高,即节点上所有样本所属类别都一样时,说明该节点说明分割得越好,这正是我们想要的结果.显然基尼系数应该越小越好,这样的话可以保证,采用分割,使得分割的样本集合越”纯粹”
目标函数
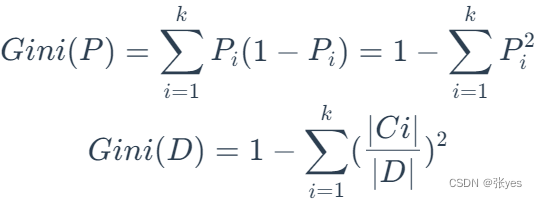
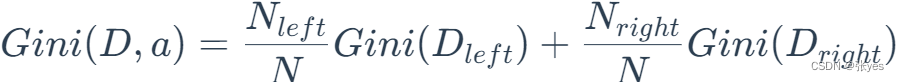

这样我们就是寻找这个分割a使得G取得最大值.
输出的值为连续的情况下(回归)
目标是找到一个分割a,使得MSE(均方误差)取得最小值

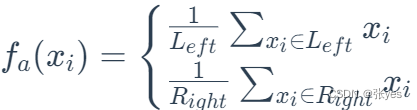
核心就转换到了a的寻找上面的了! 遍历寻找的方法
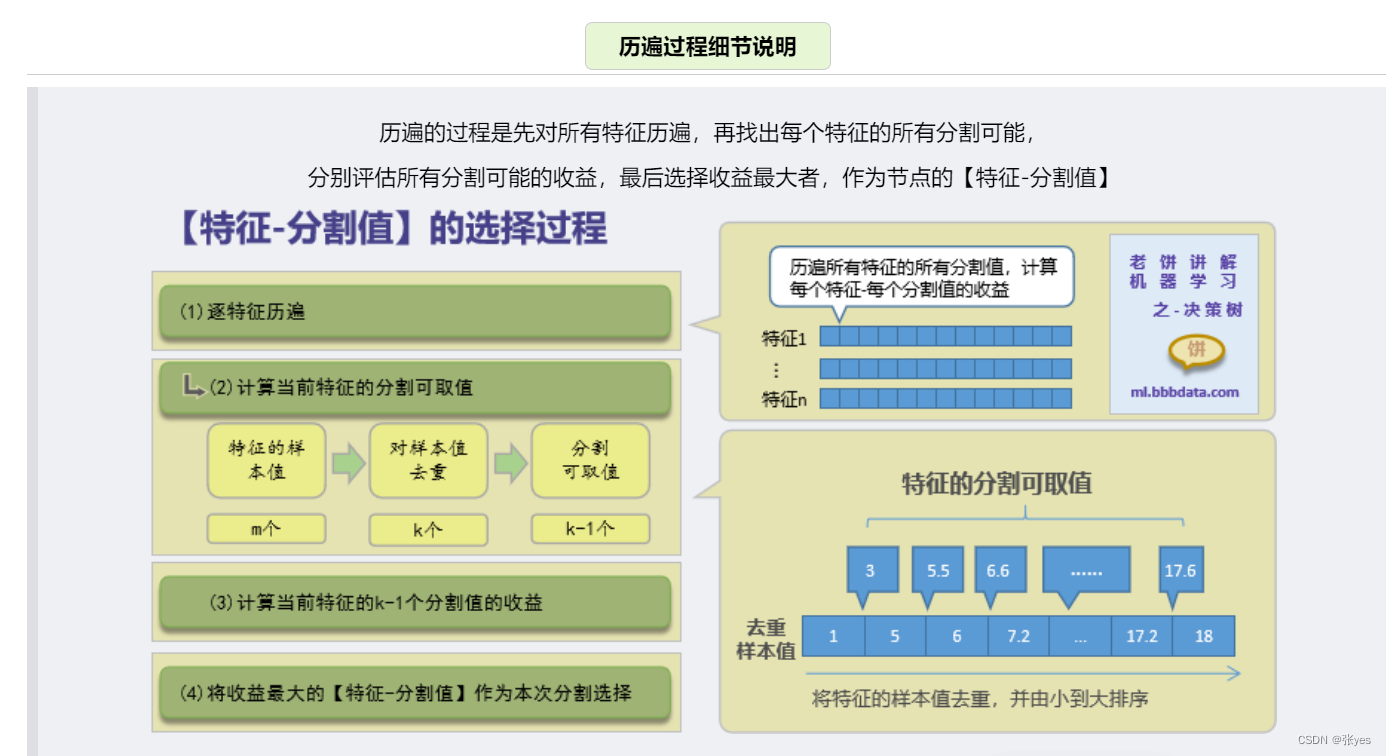
综上,基于CART的决策树就成功构造成功!
代码实现
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
from sklearn import datasets
# 加载数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
print("特征数据:", X)
print("标签数据:", y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 创建决策树分类器
clf = DecisionTreeClassifier()
# 拟合模型
clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = clf.predict(X_test)
# 输出预测结果
print("预测结果:", y_pred)
# 输出准确率
print("准确率:", clf.score(X_test, y_test))
CART分类树构建原理-老饼讲解-机器学习-通俗易懂![]() https://www.bbbdata.com/ml/text/91;bbb=702F3F612F0E139248E00FF53B9592D8
https://www.bbbdata.com/ml/text/91;bbb=702F3F612F0E139248E00FF53B9592D8















 2386
2386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









