






 本文介绍了如何使用Python的requests、re、beautifulsoup库和os库进行网络爬虫,包括抓取《三国演义》全文、解析目录和正文,以及提取特定内容。通过实际操作展示了爬虫的基本流程和技巧。
本文介绍了如何使用Python的requests、re、beautifulsoup库和os库进行网络爬虫,包括抓取《三国演义》全文、解析目录和正文,以及提取特定内容。通过实际操作展示了爬虫的基本流程和技巧。
一、实验目的
1. 掌握requests库、re库、beautifulsoup库、os库以及time库的使用。
2. 掌握正则表达式的基本操作。
3. 掌握网络爬虫的基本流程。
二、实验内容
本次实验分为以下两个任务。
2.1 任务一
从http://guoxue.lishichunqiu.com/gdxs/sanguoyanyi/网址中抓取《三国演义》名著全文。首先使用requests库完成目录页的抓取,然后使用正则表达式完成目录内容的解析,接下来使用beautifulsoup库获得每一回合的正文内容,再使用os库结合open函数将每回合的正文写进一个一个txt文件并保存在同一个文件夹里。
2.2 任务二
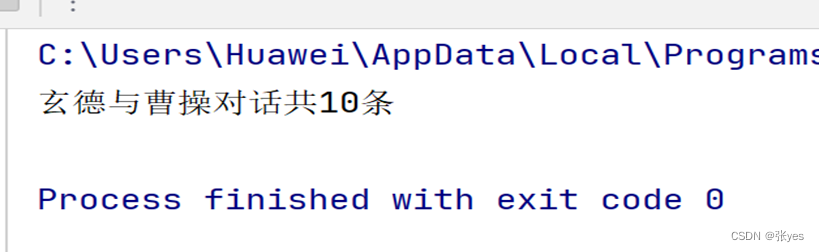
从抓取的“第二十一回·曹操煮酒论英雄 关公赚城斩车胄”文档中,使用正则表达式获取玄德与曹操的对话,并将这些对话写入一个txt文件。
三、实现方法
3.1 运行环境
PyCharm 2023.3.4 Python 3.10
3.2 基本操作
任务一的基本操作:
 |
| 图1:任务一的基本操作 |
任务二的基本操作:
|
|
| 图2:任务二的基本操作 |

四、实验结果
4.1 任务一
 |
| 图3:shell打印出来的结果截图 |
 |
| 图4:第二十回 |
 |
| 图5:第二十一回 |
 |
| 图6:二十二回 |
 |
| 图7:存放每章正文内容的文件夹截图 |
4.2 任务二
 |
| 图8:shell打印出来的结果截图 |
 |
| 图9:玄德与曹操对话txt文件截图 |
五、源程序清单
5.1 任务一
import requests
import re
from bs4 import BeautifulSoup
import os
import time
path = r"E:\Python_Study\Web_Spider_Data_Acquisition\Experiment03\三国演义" # 要存储的文件夹
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'
}
main_url = 'http://guoxue.lishichunqiu.com/gdxs/sanguoyanyi/'
page_text = requests.get(url=main_url, headers=headers)
page_text.encoding = 'UTF-8'
page = page_text.text # 获取html代码
index_regex = '''<a style="font:14px/24px '宋体';" href="(.*?)" title=".*?">(.*?)</a>''' # 定位目录,包括每一回的URL和每一回的题目
a_list = re.findall(index_regex, page)
print(a_list)
for i in a_list[19:22]:
detail_url = i[0] # detail_url=每一回的URL
# 对详情页发起请求解析出章节内容
page_detail = requests.get(url=detail_url, headers=headers)
page_detail.encoding = 'UTF-8'
page_detail = page_detail.text # 获取该回合的html代码
soup = BeautifulSoup(page_detail, 'html.parser')
soup = soup.find_all('div', attrs={'id': "content"}) # 使用find_all方法,定位到'div'标签,属性为'id':"content",从而获得正文内容
# soup.find_all(标签,attrs={属性})
content = ''
for con in soup:
c = con.text
content += c
# 数据持久化,存储小说
if not os.path.exists(path):
os.mkdir(path)
with open(path + './%s' % i[1] + '.txt', 'w', encoding='utf-8') as file:
file.write(content + '\n')
print("正在下载:" + i[1])
time.sleep(2)
5.2 任务二
import re
f = open(
r"E:\Python_Study\Web_Spider_Data_Acquisition\Experiment03\三国演义\第二十一回·曹操煮酒论英雄 关公赚城斩车胄.txt",
"r", encoding="utf-8")
txt = f.read()
f.close()
pt = "(玄德.{0,2}曰:“.{1,40}”操.{0,10}曰:“[^”]{1,100}”)"
count = 0
with open(r'E:\Python_Study\Web_Spider_Data_Acquisition\Experiment03\三国演义\曹操煮酒论英雄对话.txt', 'w',
encoding='utf-8') as f:
for i in re.finditer(pt, txt):
f.write(i.group() + '\n')
count += 1
print(f"玄德与曹操对话共{count}条")
六、思考及总结
6.1with语句:(python中的关键字)
一个上下文管理器:在代码块执行前准备,代码块执行后收拾
相当于是创建了一个环境,处理上下文环境产生的异常
最关键的作用:代码块执行完毕后自动执行清理操作,无论代码块是否成功执行
1:最简单,经典的例子就是文件操作:
f = open("File_Path")
data = f.read()
"""
data的一系列操作
"""
f.close()这样的代码:
1.过于冗长,不够优雅
2. 忘记关闭文件,导致文件一直被占用着
3.读取文件时出现异常,代码无法进行
改为如下代码:
with open("File_Path") as f:
data = f.read()
"""
data的一系列操作
"""2: with的底层
相当于封装了两个魔术方法(在执行with语句时会自动执行)__enter__()和__exit__()
(是以双下划线(__)开头和结尾的特殊方法,这些方法在对象的创建、操作和销毁等过程中被自动调用,从而实现对对象的控制和定制)
3.with的三个步骤:
step1. 执行with语句前:__enter__()方法先被执行
step 2. 执行with语句中:执行with中的代码块
step 3. 执行with语句后(with代码被执行完毕):
__exit__()方法被调用
即使出现错误,也会调用 __exit__() 方法,关闭文件流
4.with在python中其他用法
多线程:acquire()->代码块->release()
Python Threading中的Lock模块有acquire()和release()两种方法
数据库连接:__enter__()->代码块->__exit__()
import sqlite3
with sqlite3.connect('database.db') as conn:
cursor = conn.cursor()
cursor.execute("SELECT * FROM table_name")
rows = cursor.fetchall()
# 在 with 代码块结束后,数据库连接会自动关闭网络请求:__enter__()->代码块->__exit__()
import requests
with requests.get('url') as response:
print(response.text)
# 在 with 代码块结束后,网络连接会自动关闭6.2:复制的元素与直接打印出来的html不一致的问题
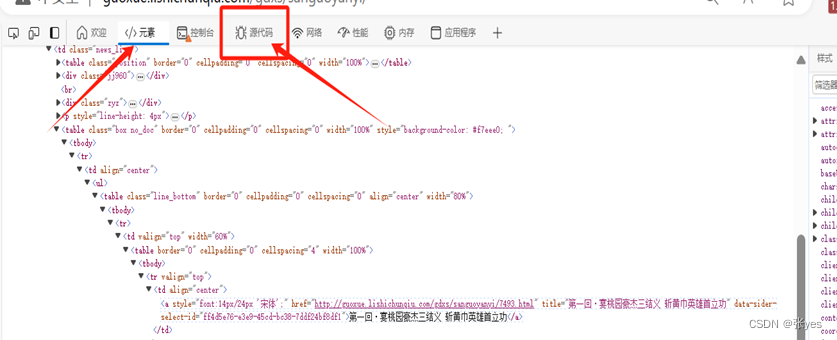
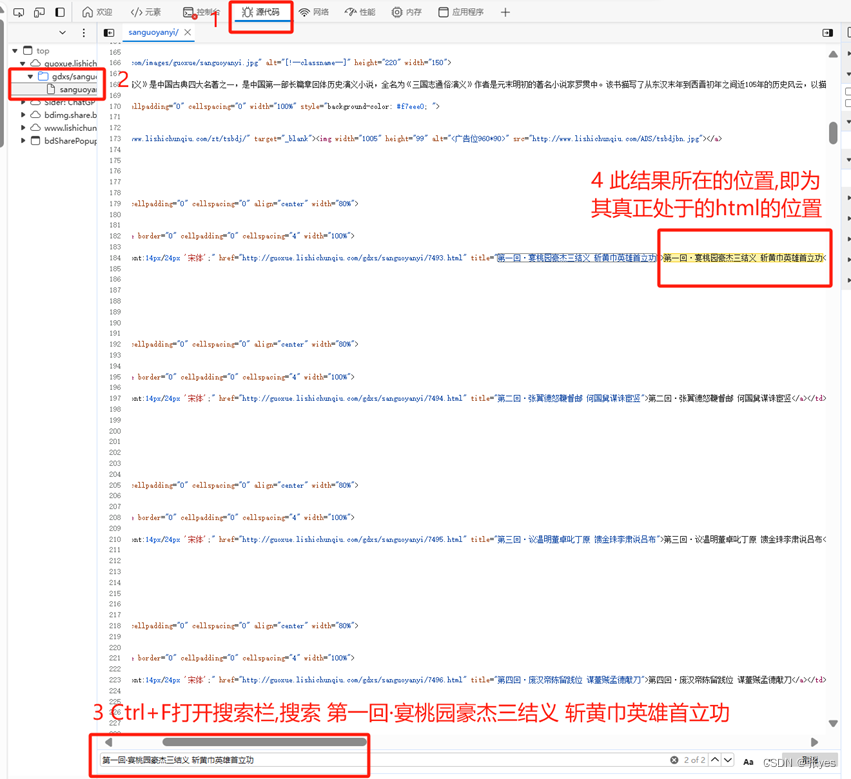
在使用检查,copy element的时候出现了一个很严重的问题,即复制的元素与直接打印出来的html不一致的问题,具体情况如下:
| 在Edge和谷歌浏览器中,出现以下问题:
这样就初步解决了上述html '不同'的问题 那么更进一步: 为什么其他属性的都有,偏偏只有这一个属性值没有呢?这里涉及到前端的知识:data-*诸如此类的属性值是供JavaScript 或 CSS 使用.我们所看到的html代码是浏览器自动优化过的,我们爬虫的时候的html也是经过处理过的,只有裸露的html代码 仍然是该网站:
|





6.3: re.finditer()方法源代码解析:
 |
| 图16:finditer源代码 |
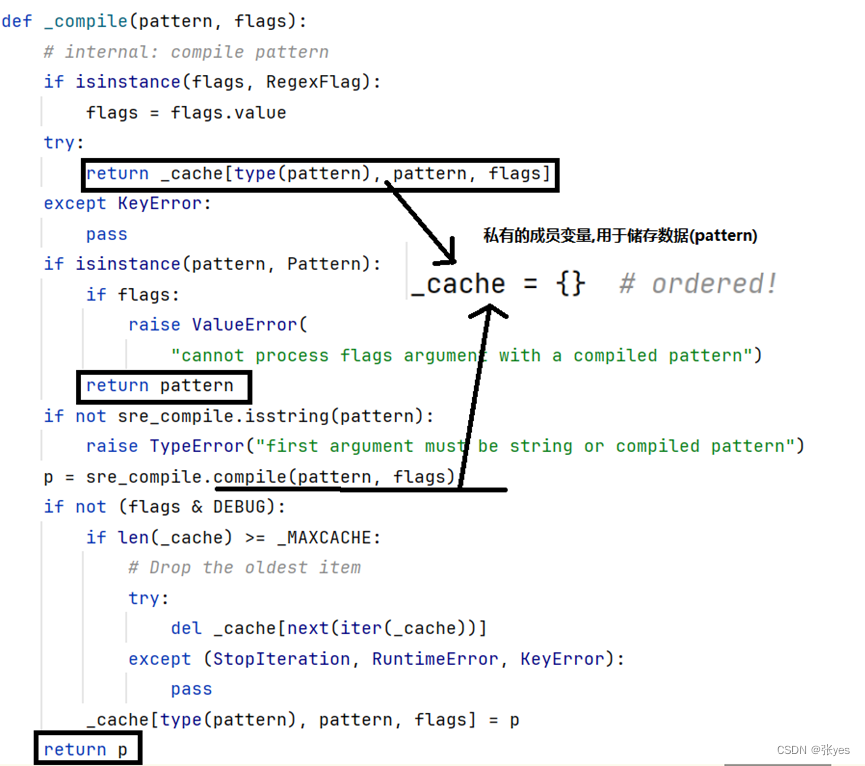
这段代码的含义是使用re.compile()函数编译正则表达式pattern并设置标志flags,然后调用编译后的正则表达式对象的finditer()方法在字符串string中查找所有匹配项。最后仍然调用了_compile()方法.
 |
| 图17: _compile()源代码 |
(在 Python 中,将方法名字前面加一个单下划线(_)是一种约定俗成的方式,它表示这个方法是“私有”的,不应该被其他模块或代码直接调用。)
_compile(pattern,flags) 其实就是使用该正则表达式模板,去不断对string匹配,用于生成一个可迭代对象.这样做的好处是可以提高性能,因为编译后的正则表达式对象可以被重复使用,避免了每次都重新编译正则表达式。
6.4:心得体会
爬虫无外乎就是这几步,有难度的就只有解析数据这一步,只要我们能够熟练的掌握基本解析库中的方法,方法三要素(方法名,参数,返回值),并对可能产生的异常结果进行一个处理等,更好,更健壮的爬虫程序都能被做出来(暂时不考虑反爬的情况)
 |
| 图18: 爬虫一般步骤 |















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









