







好家伙,出问题了,没有匹配到所有要提取信息的元素节点,列表为空,这可把阿牛整懵了,学到现在,阿牛对xpath一直用xpath helper,不会出错,不信你们看:
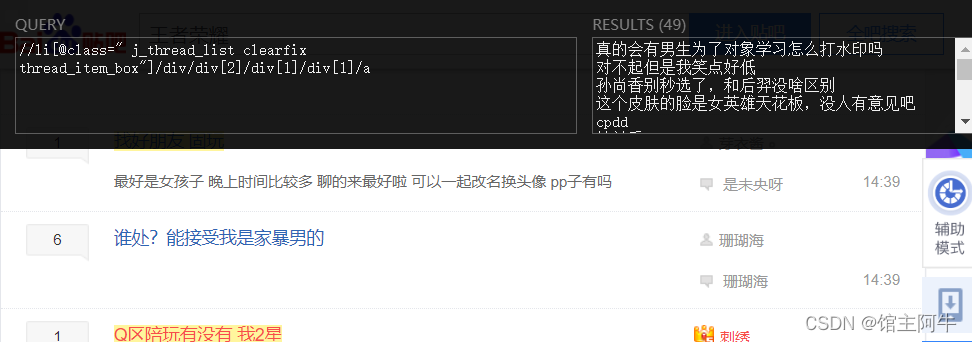
正常猜想是反爬了,不急,先打开网页源代码看一手,不看不知道,一看吓一跳,源码中内容是注释掉的,在浏览器通过渲染去掉了注释。
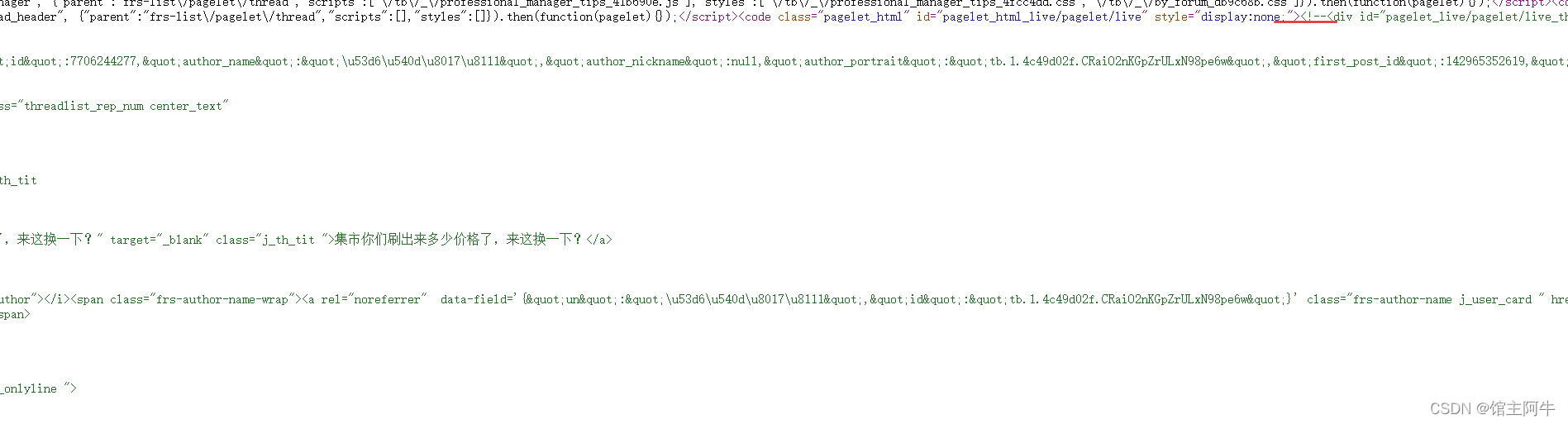
所以我们拿到的内容是注释掉的,需要处理去掉HTML的注释符号,我们的xpath才能生效。
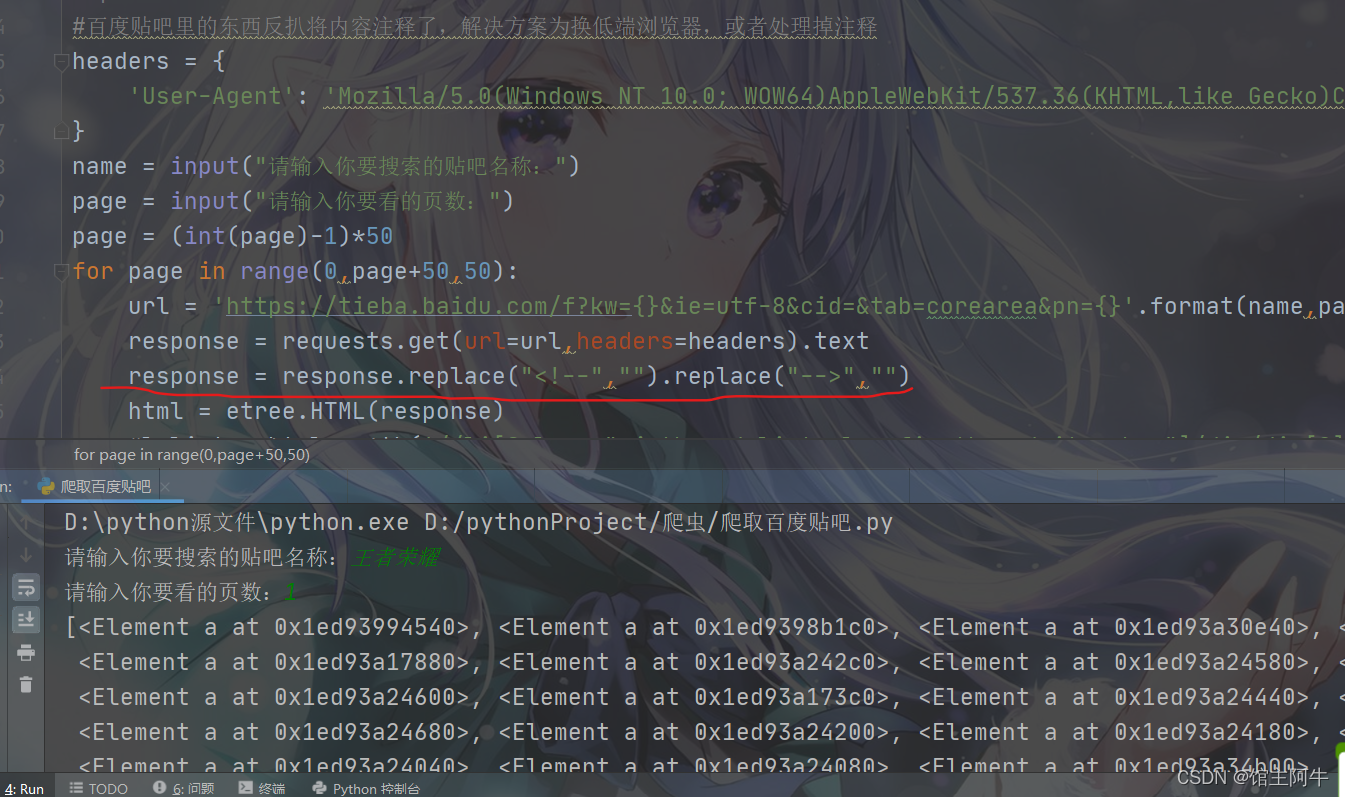
果然去掉注释后我们拿到了对象,接下来我们就可以进行数据提取了,最后把他存为csv文件。
import requests
from lxml import etree
import csv
#百度贴吧里的东西反扒将内容注释了,解决方案为换低端浏览器,或者处理掉注释
headers = {
‘User-Agent’: ‘Mozilla/5.0(Windows NT 10.0; WOW64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/90.0.4430.85 Safari/537.’,
}
name = input(“请输入你要搜索的贴吧名称:”)
page = input(“请输入你要看的页数:”)
page = (int(page)-1)*50
for page in range(0,page+50,50):
url = ‘https://tieba.baidu.com/f?kw={}&ie=utf-8&cid=&tab=corearea&pn={}’.format(name,page)
response = requests.get(url=url,headers=headers).text
#去掉html的注释符号
response = response.replace(“ ”,“”)
html = etree.HTML(response)
el_list = html.xpath(‘//li[@class=" j_thread_list clearfix thread_item_box"]/div/div[2]/div[1]/div[1]/a’)
print(el_list)
newline=‘’ 去掉存进csv文件内容之间的空行
with open(“贴吧.csv”, “w”, encoding=“utf-8”,newline=‘’) as csvfile:
fieldnames = [“title”, “link”]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for el in el_list:
temp = {}
temp[‘title’] = el.xpath(“./text()”)[0]
#给链接拼接域名
temp[‘link’] = ‘https://tieba.baidu.com’+el.xpath(“./@href”)[0]
print(temp)
writer.writerow(temp)
print(“爬取完毕!”)
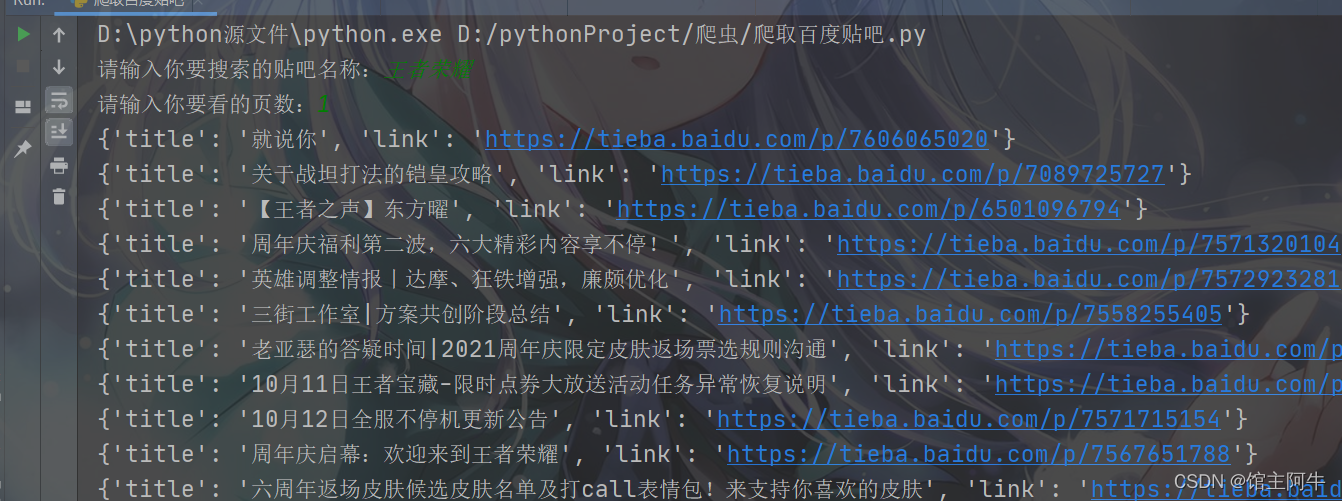
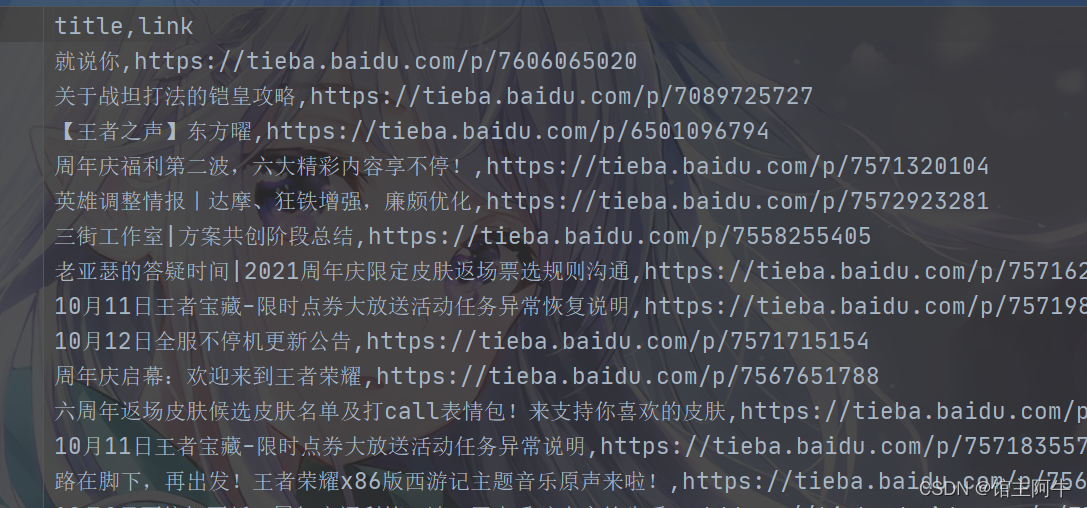
===================================================================
这都是阿牛很久以前写的,抽空把它写出来,希望对大家有所帮助,我会持续将以前学的慢慢发布到专栏哦!感谢大家的支持!!!
[

创作挑战赛 
新人创作奖励来咯,坚持创作打卡瓜分现金大奖
](https://blogdev.blog.csdn.net/article/details/124124117?utm_campaign=marketingcard&utm_source=qq_57421630&utm_content=122684357)
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数前端工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Web前端开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:前端)

最后
你要问前端开发难不难,我就得说计算机领域里常说的一句话,这句话就是『难的不会,会的不难』,对于不熟悉某领域技术的人来说,因为不了解所以产生神秘感,神秘感就会让人感觉很难,也就是『难的不会』;当学会这项技术之后,知道什么什么技术能做到什么做不到,只是做起来花多少时间的问题而已,没啥难的,所以就是『会的不难』。
我特地针对初学者整理一套前端学习资料,免费分享给大家,戳这里即可免费领取
来花多少时间的问题而已,没啥难的,所以就是『会的不难』。
我特地针对初学者整理一套前端学习资料,免费分享给大家,戳这里即可免费领取
[外链图片转存中…(img-X16wmF8e-1712377261525)]

















 63万+
63万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









