






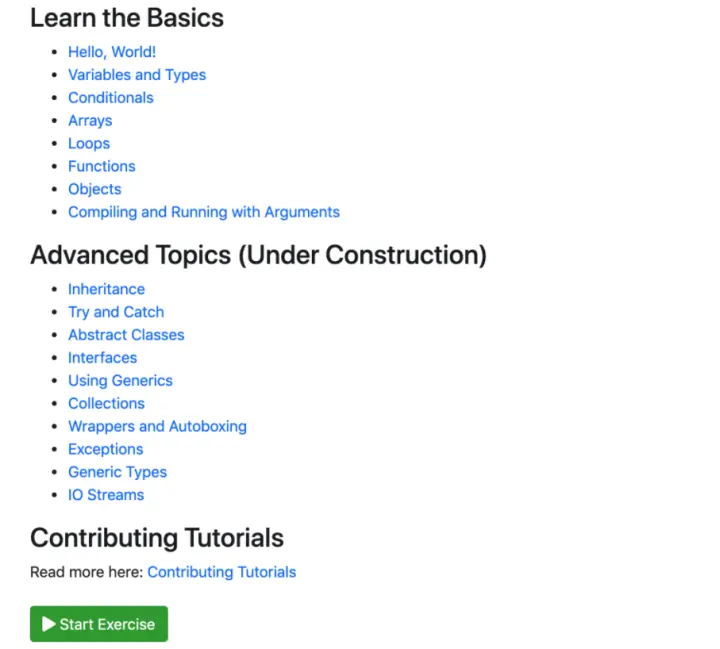
这也是一个教程网站,不仅仅只有 Java 的学习,也包括 Python、HTML、GO、C 和 C++ 等编程语言的学习,非常不错,你值得拥有

官网:https://www.learnjavaonline.org/
2、StackOverflow
===============
说到学习 Java ,怎么能不提 StackOverflow 呢?
StackOverflow 是一个与程序相关的 IT 技术问答网站。用户可以在网站免费提交问题,浏览问题,索引相关内容,在创建主页的时候使用简单的 HTML。在问题页面,不会弹出任何广告,销售信息,JavaScript 窗口等。
干净清爽,基本上所有的问题你在 StackOverflow 都能找到答案,你可以提出公共问题,也可以提出私人问题,甚至可以在 StackOverflow 上找工作
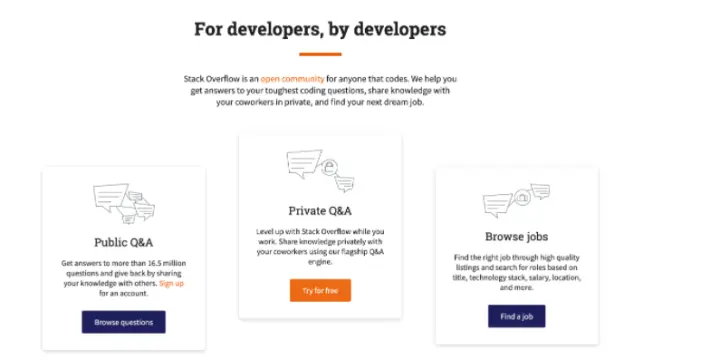
官网:https://stackoverflow.com/
3、DZone
=======
DZone 上会有 IT 前沿的新闻和文章,会有 AI、大数据、云、数据库、DevOps、IoT、Java 还有开源项目
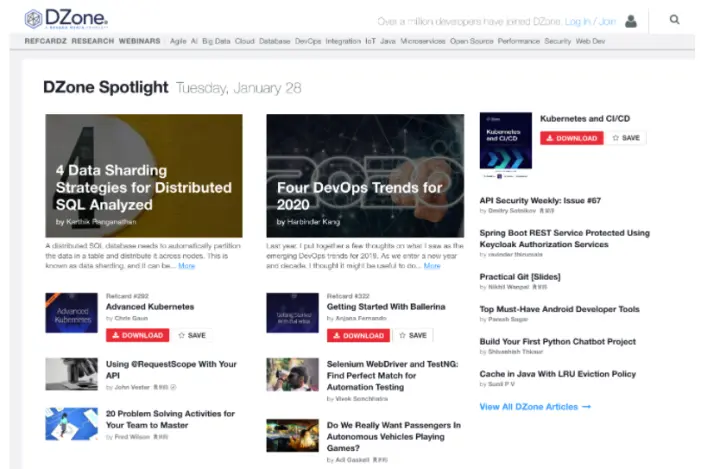
关于 Java 新特性的介绍,新特性的使用都会在上面,是你掌握前沿动态不可或缺的网站
官网:https://dzone.com/
4、LeetCode
==========
LeetCode 是一个很牛逼的刷题网站,它的重要性不用我多说了吧
看到这个界面就爱了,里面包括大量的算法题,这些算法题是大厂面试必出的题型,据说掌握了这些算法题后,你可以吊打中国任何一家大厂,是不是真的咱也不知道,毕竟咱们没做过几道题。
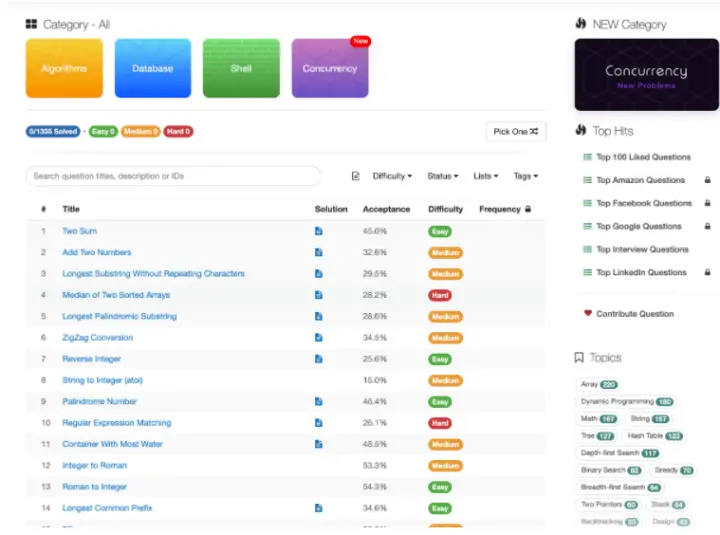
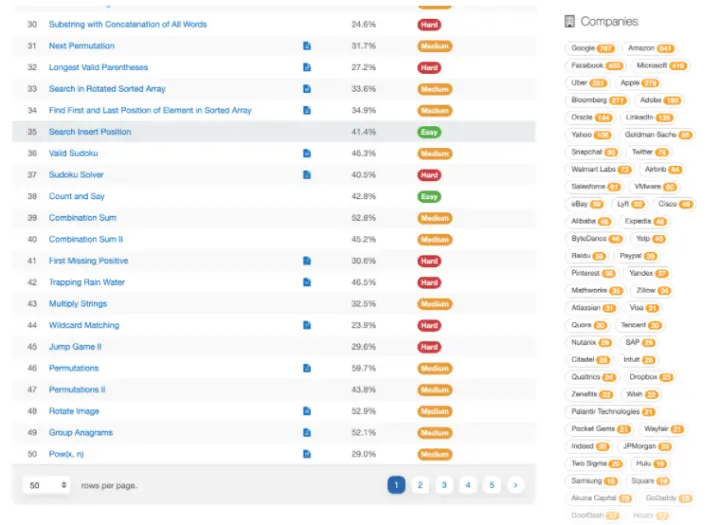
问题可以区分难易程度,有解决措施,接受度,困难程度等,下面还有大厂公司的面试题
因为 LeetCode 太牛逼了,LeetCode 推出了中文版,中文为力扣
几乎和英文版的一模一样,如果小伙伴英文不是很好可以看看中文版 刷题
官网:https://leetcode.com/ ;https://leetcode-cn.com
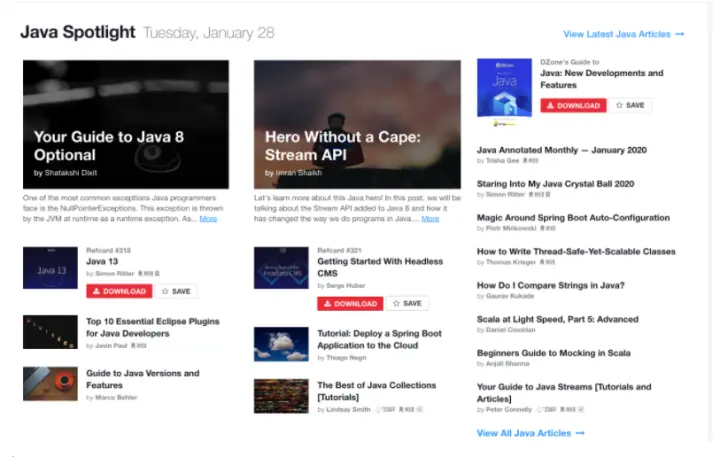
5、Java 官方文档
===========
学习 Java,还有什么比官网更权威的呢?我之前一直不知道官网能做的这么干净,你来看一下
总结
以上是字节二面的一些问题,面完之后其实挺后悔的,没有提前把各个知识点都复习到位。现在重新好好复习手上的面试大全资料(含JAVA、MySQL、算法、Redis、JVM、架构、中间件、RabbitMQ、设计模式、Spring等),现在起闭关修炼半个月,争取早日上岸!!!
下面给大家分享下我的面试大全资料
- 第一份是我的后端JAVA面试大全

后端JAVA面试大全
- 第二份是MySQL+Redis学习笔记+算法+JVM+JAVA核心知识整理

MySQL+Redis学习笔记算法+JVM+JAVA核心知识整理
- 第三份是Spring全家桶资料

MySQL+Redis学习笔记算法+JVM+JAVA核心知识整理
hXJsF8e-1714189598070)]
MySQL+Redis学习笔记算法+JVM+JAVA核心知识整理
- 第三份是Spring全家桶资料
[外链图片转存中…(img-rdkmg1xE-1714189598071)]
MySQL+Redis学习笔记算法+JVM+JAVA核心知识整理















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









