








平均池化和最大池化是CNN中使用最多的下采样方式,所谓的池化,是指特征图分别在高、长方向上的缩小运算,下采样目的在于增加模型的鲁棒性,所谓的鲁棒性,可以简单理解为当输入数据发生微小偏差时,结果仍是相同的。池化的特征主要有3个:
-
①池化层没有要学习的参数,这与卷积层有质的区别。
-
②经过池化层后,特征图的通道数不会发生变化,即输入数据和输出数据的通道数是相同的。
-
③对微小的位置变化具有鲁棒性。
下面我们分别介绍最大池化(MaxPool)和平均池化(AvgPool)两种最常见的下采样方式。
1.1 最大池化
假设有一张特征图X,size为(4,4),池化窗口kernel size为2,池化步长为2。
step1:

step2:

step3:

step4:

1.2 平均池化
平均池化的运行原理跟最大池化基本一样,唯一不同之处在于平均池化是计算目标区域的平均值。
step1:

- (1+2+0+1)/ 4=1
step2:
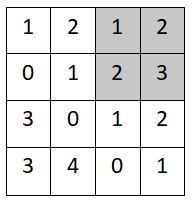
- (1+2+2+3)/ 4=2
step3:

- (3+0+3+4)/ 4=2
step4:

- (1+2+0+1)/ 4=1
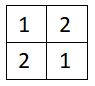
最后特征图变为:
1.3 size的变化
假设输入大小为(H, W),滤波器大小为(FH, FW),输出大小为(OH, OW),填充为P,步幅为S,输出大小可通过下式计算得到。
最后
经过日积月累, 以下是小编归纳整理的深入了解Java虚拟机文档,希望可以帮助大家过关斩将顺利通过面试。
由于整个文档比较全面,内容比较多,篇幅不允许,下面以截图方式展示 。







由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!
sf-1714812630829)]
[外链图片转存中…(img-S7yN33Ry-1714812630829)]
由于篇幅限制,文档的详解资料太全面,细节内容太多,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!















 1514
1514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









