







# 加载文档做处理文档的准备工作
loader = UnstructuredFileLoader("test.txt")
# 调用load发开始进行预处理的过程
data = loader.load()
langchain.text_splitter.RecursiveCharacterTextSplitter
RecursiveCharacterTextSplitter将使用UnstructuredFileLoader加载之后的样本进行切分,利于对长文本的精细化处理。
其中的两个主要参数chunk_size和chunk_overlap的作用如下
chunk_size:切割的最长长度,该长度的单位是字符不是token长度
chunk_overlap:切割的重叠长度
以上两个参数均没有默认值需要手动设置
# 初始化加载器
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(data)
2.读取本地Embedding模型
考虑到使用在线OpenAI 的Embedding模型消耗的Token过高,决定使用HuggingFaceEmbeddings加载离线的Embedding模型,代码如下。
from langchain_community.embeddings import HuggingFaceEmbeddings
model_name = r"bce-embedding-vase\_v1"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize\_embeddings': False}
hf = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
其中model_name指代的不是模型名称,是包含训练好的模型在内的配置文件夹名称,在配置文件夹下面包含各类配置文件,且目前需要使用官方支持的模型,如果官方的不支持该模型,虽然在指定路径下存在着模型文件pytorch_model.bin,会出现以下警告信息,虽然程序没有报错,但是其没有成功加载模型,会提示找不到模型文件然后用平均策略创造了一个新的模型。还有可能出现找不到配置文件等错误,后续评估不同Embedding模型的效果。
No sentence-transformers model found with name ernie-3.0-xbase-zh. Creating a new one with MEAN pooling.
在可用其中使用最多的是bce-embedding-vase_v1模型,其是有道公司发布的一个embedding模型,基于pytorch框架编写,支持对中文和英文生成嵌入向量,链接网址如下,下载文件内容需要注册HuggingFace账号。
网址https://huggingface.co/maidalun1020
3. 保存向量数据库
使用langchain_community.vectorstores.Chroma保存知识向量库,其保存的完整代码如下,关键行解释在后。
官方文档地址:https://api.python.langchain.com/en/latest/vectorstores/langchain_community.vectorstores.chroma.Chroma.html#
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
import sentence_transformers
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 导入文本
loader = UnstructuredFileLoader("test.txt")
data = loader.load()
# 文本切分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
split_docs = text_splitter.split_documents(data)
model_name = r"bce-embedding-vase\_v1"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize\_embeddings': False}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
#保存向量数据库部分
# 初始化数据库
db = Chroma.from_documents(split_docs, embeddings,persist_directory="./chroma/news\_test")
# 持久化
db.persist()
# 对数据进行加载
db = Chroma(persist_directory="./chroma/news\_test", embedding_function=embeddings)
- 初始化数据库
使用Chroma.from_documents来初始化也就生成一个词向量数据库,他对原始文档中的数据进行处理并通过模型映射成向量 ,其中split_docs为切分之后的文本,embeddings为初始化之后的模型
db = Chroma.from_documents(split_docs, embeddings,persist_directory="./chroma/news_test")
- 持久化
在实例化了一个用于初始化向量数据库的类之后,需要调用persist函数对其进行保存,之后再使用的时候加载之前初始化得到的向量数据库即可,不需要重新初始化,也就是通过模型生成向量数据库。
db.persist()
- 对数据进行加载
persist_directory该变量为初始化数据库中指定的路径,embedding_function表示使用的embedding模型,如果不对已经生成的向量数据库添加新的文档则不需要指定。
db = Chroma(persist_directory="./chroma/news\_test", embedding_function=embeddings)
4.检索数据库中的相似样本
在使用大语言模型对数据库中的内容进行总结归纳之前,需要去搜被切分的文本中哪些文本于问题相似,然后将搜索到的相似的样本和问题发给大模型大模型在根据相似样本和问题得到总结。在代码中使用到的是similarity_search其作用是需要对搜索到的相似文本进行输出的时候采用。
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
import IPython
import sentence_transformers
from langchain_community.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQA
from langchain_community.llms import Tongyi
model_name = r"bce-embedding-vase\_v1"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize\_embeddings': False}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
db = Chroma(persist_directory="./chroma/news\_test", embedding_function=embeddings)
question = "浩浩的科研笔记的原力等级"
# 寻找四个相似的样本
similarDocs = db.similarity_search(question,k=4)
print(similarDocs)
5.使用通义千问总结归纳
在使用LangChain的过程中,使用langchain.chains.RetrievalQA对从向量数据库中检索出来的类似样本进行总结归纳。自建的知识库文本如下:
CSDN中浩浩的科研笔记博客的作者是啊浩,博客的地址为 www.chen-hao.blog.csdn.net。
其原力等级为5级,在其学习评价中,其技术能力超过了99.6%的同码龄作者,且超过了97.9%的研究生用户。
该博客中包含了,单片机,深度学习,数学建模,优化方法等,相关的博客信息,其中访问量最多的博客是《Arduino 让小车走实现的秘密 增量式PID 直流减速编码电机》。
其个人能力主要分布在Python,和Pytorch方面,其中python相对最为擅长,希望可以早日成为博客专家。
提问问题:
浩浩的科研笔记的原力等级是多少?
代码实现:
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.chains import RetrievalQA
from langchain_community.llms import Tongyi
model_name = r"bce-embedding-vase\_v1"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize\_embeddings': False}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
db = Chroma(persist_directory="./chroma/news\_test", embedding_function=embeddings)
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(llm=Tongyi(), retriever=retriever)
query = "浩浩的科研笔记的原力等级是多少?"
print(qa.run(query))
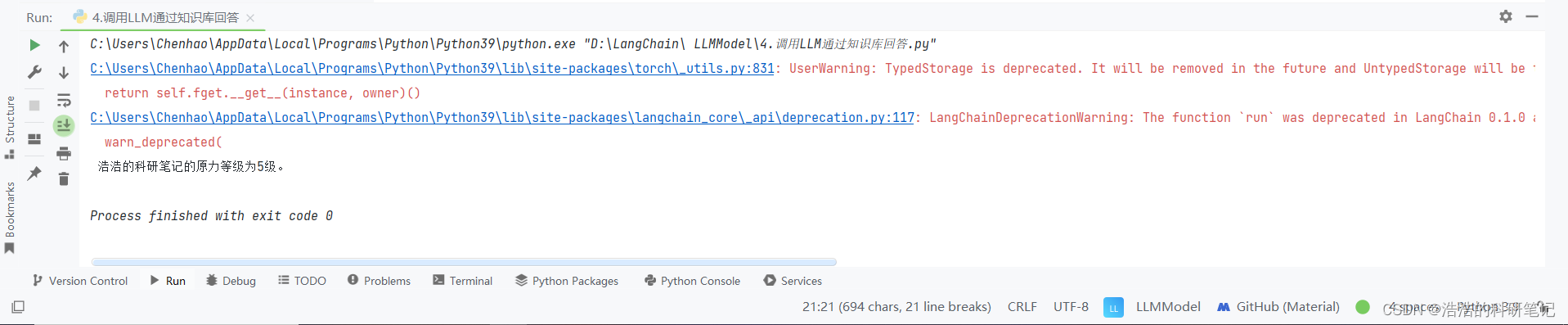
retriever = db.as_retriever()创建一个检索器,其作用是在数据库中于问题相似的样本片段,默认搜索的样本为4,其和配置详细参数参考官方文档.
6.额外补充 LangChain 使用通义模型进行流式输出
当前阶段,使用LangChain对通义千问的支持性仍然不高,官方文档的所有例程都是OpenAI模型,所以想使用同义前文API进行多轮对话,或者流式输出等都有各种各样的BUG,其中我找到了使用流式输出的解决办法,但是依旧需要对按照好的库文件进行更改。
这里是将官方的流式输出代码,换成Tongyi模型,官方代码里使用的模型是OpenAI,
from langchain.prompts import ChatPromptTemplate
from langchain_community.llms import Tongyi
llm = Tongyi(streaming=True, max_tokens=2048)
prompt = ChatPromptTemplate.from_messages(
[("system", "你是一个专业的AI助手。"), ("human", "{query}")]
)
llm_chain = prompt | llm
ret = llm_chain.stream({"query": "你是谁?"})
for token in ret:
print(token, end="", flush=True)
print()
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 616
616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









