







- 如果要绘制累计分布函数图,则只需在上边的density(bins)对象后再调用一下cumsum()函数,对数组数据进行累加后在传入即可。
以2020年沪深300指数(399300.SZ)的收益率(日涨跌幅)数据为例:
调取数据
import numpy as np
import tushare as ts
import pandas as pd
token = ‘Your Token’ # 输入你的接口密匙,获取方式及相关权限见Tushare官网。
pro = ts.pro_api(token)
df = pro.index_daily(ts_code=‘399300.SZ’)
df[‘trade_date’] = pd.to_datetime(df[‘trade_date’])
df.set_index([‘trade_date’], inplace=True) # 将日期列作为行索引
df = df.sort_index()
实现概率分布
import matplotlib.pyplot as plt
from scipy import stats
density = stats.kde.gaussian_kde(df.pct_chg[‘2020’]) #研究数据格式化
bins=np.arange(-5,5,0.02) # 设定分割区间
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
plt.rcParams[‘axes.unicode_minus’] = False
plt.subplot(211)
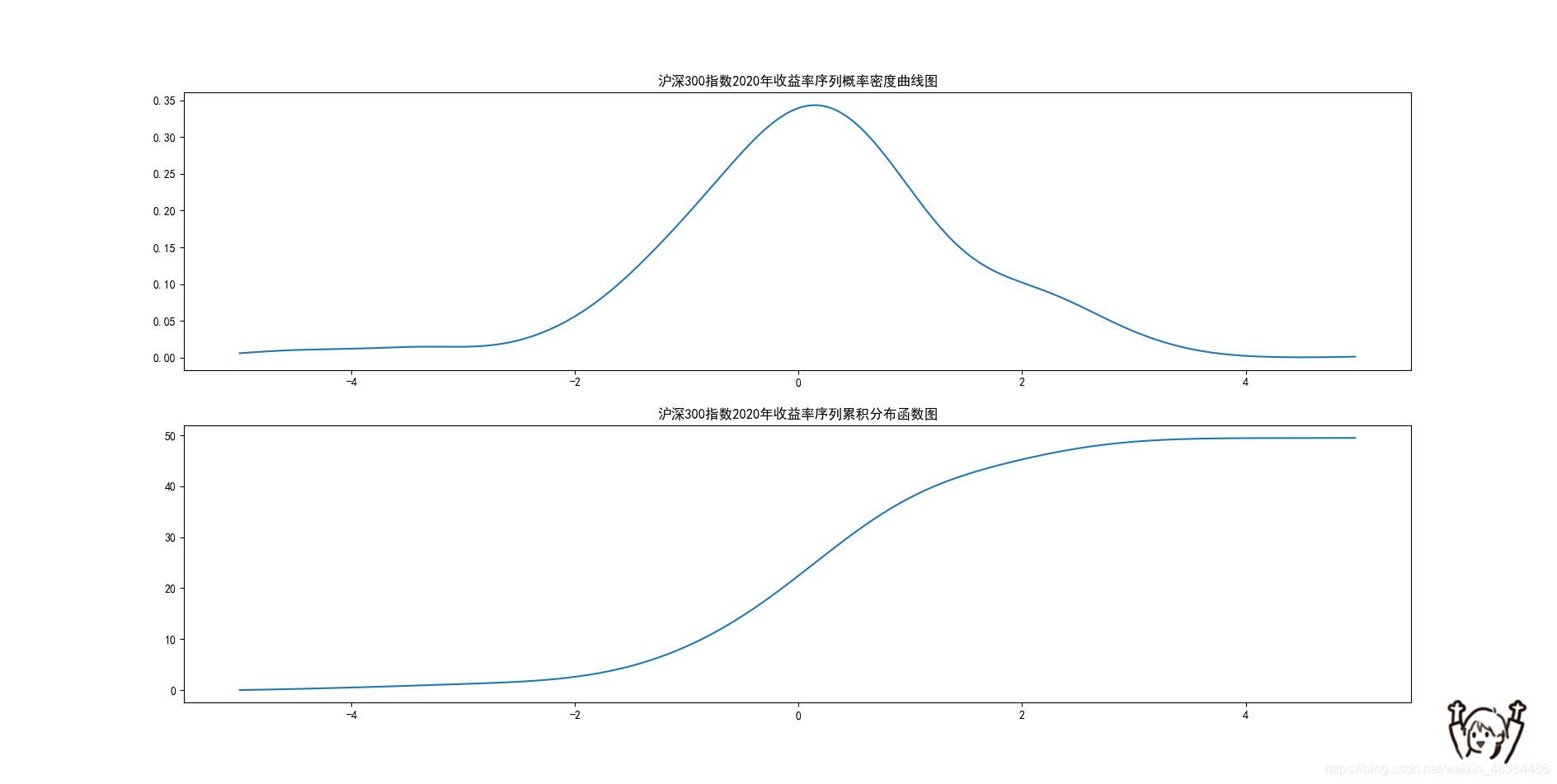
plt.plot(bins,density(bins))
plt.title(‘沪深300指数2020年收益率序列概率密度曲线图’)
plt.subplot(212)
plt.plot(bins,density(bins).cumsum())
plt.title(‘沪深300指数2020年收益率序列累积分布函数图’)
plt.show()
结果展示如下:
================================================================================
可以用样本数据的平均值来刻画样本的中心位置,期望(Expectation)是随机变量所有可能取的结果的均值,用来呈现总体的中心位置。对于离散型随机变量,期望是该随机变量所有可能结果的取值与其概率的乘积之和:
E ( X ) = ∑ k a k f X ( a k ) = ∑ k a k P { X = a k } \displaystyle E\relax{(X)}=\sum_ka_kf_X\relax{(a_k)}=\sum_ka_kP\{X=a_k\} E(X)=k∑akfX(ak)=k∑akP{X=ak}
方差(Variance)则是:
V a r ( X ) = E [ X − E ] 2 = ∑ k [ a k − E ( X ) 2 ] P { X = a k } \displaystyle Var\relax{(X)}=E\left[X-E\right]2=\sum_k\left[a_k-E(X)2\right]P\{X=a_k\} Var(X)=E[X−E]2=k∑[ak−E(X)2]P{X=ak}
对于一类特殊的离散型随机变量:伯努利(Bernoulli Random Variable)随机变量,伯努利随机变量X只能取到两个值,0或者1,对应的概率质量函数为:
f X ( a ) = P ( X = a ) = { p , a = 1 1 − p , a = 0 \displaystyle f_X\relax{(a)}=P\relax{(X=a)}=\begin{cases}p,&a=1 \\1-p,&a=0\end{cases} fX(a)=P(X=a)={p,1−p,a=1a=0
伯努利随机变量的期望值 E ( X ) = p \displaystyle E(X)=p E(X)=p
方差为 V a r ( X ) = ( 1 − p ) ⋅ p \displaystyle Var(X)=(1-p)·p Var(X)=(1−p)⋅p
若随机变量X为连续型随机变量,其概率密度函数为 f X \displaystyle f_X fX,则期望为: E ( X ) = ∫ − ∞ ∞ a f X ( a ) d a \displaystyle E(X)=\int_{-\infty}^{\infty}af_X\relax{(a)}d\relax{a} E(X)=∫−∞∞afX(a)da
方差为: V a r ( X ) = ∫ − ∞ ∞ [ a − E ( X ) ] 2 f X ( a ) d a \displaystyle Var\relax{(X)}=\int_{-\infty}{\infty}\left[a-E\relax{(X)}\right]2f_X\relax{(a)}d\relax{a} Var(X)=∫−∞∞[a−E(X)]2fX(a)da
随机变量可能的取值有很多(比如连续型随机变量的取值为无穷),但其观测值(实际值)个数有限,因此现实中随机变量的概率分布、期望、方差等特征值通常是不可知的,推断统计就是透过其观测值的集合——样本数据来刻画这些特征的。
==============================================================================
研究伯努利分布时,我们关注的期望是进行一次试验结果的期望值,这样的结果有两种情况,所以伯努利分布也称“两点分布”。
而研究二项分布时,我们关注的是n次试验的结果,这样的结果有多种组合。
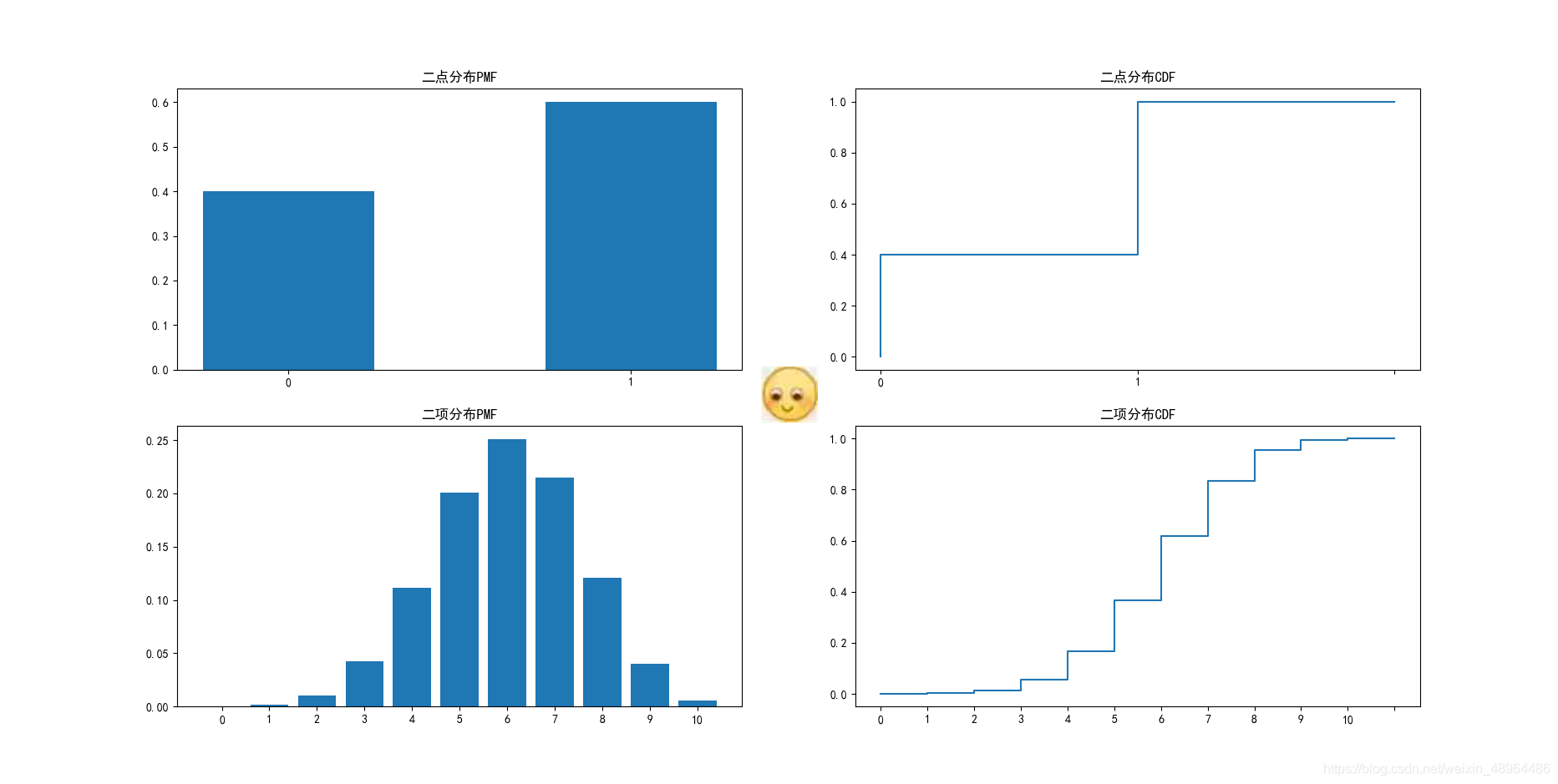
为直观说明,假设二点分布结果0的概率为0.4,结果为1的概率为0.6;
二项分布结果为0的概率为0.4,结果为1的概率为0.6,且进行十次。
则:
n = 10
p1 = 0.6
p2 = 0.6
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
plt.rcParams[‘axes.unicode_minus’] = False
plt.subplot(221)
plt.bar([‘0’,‘1’], [1-p1,p1], width=0.5)
plt.title(“二点分布PMF”)
plt.subplot(222)
plt.plot([‘0’,‘0’,‘1’,‘1’,’ '], [0, 0.4, 0.4, 1.0,1.0])
plt.title(“二点分布CDF”)
plt.subplot(223)
b = [stats.binom.pmf(i,10,0.6) for i in range(0,11)]
plt.bar([str(i) for i in range(0,n+1)],b)
plt.title(‘二项分布PMF’)
plt.subplot(224)
plt.title(“二项分布CDF”)
c = [str(i//2) for i in range(0,2*(n+1))]
c.append(‘’)
d = [stats.binom.cdf(i//2,10,0.6) for i in range(0,22)]
d.insert(0,0)
plt.plot(c,d)
plt.show()
展示结果:
当np≥10,n(1-p)≥10都满足时,二项分布可以近似为正态分布。
在Numpy库中可以使用binomial()函数来生成二项分布随机数。
形式为:binomial(n, p, size=None)
参数n是进行伯努利试验的次数,参数p是伯努利变量取值为1的概率,size是生成随机数的数量。
np.random.binomial(100, 0.5, 20)

3.3.1 PMF及其图像绘制
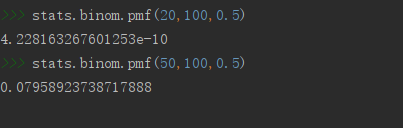
求100次试验,20次成功的概率,p=0.5
stats.binom.pmf(20,100,0.5)
求100次试验,50次成功的概率,p=0.5
stats.binom.pmf(50,100,0.5)
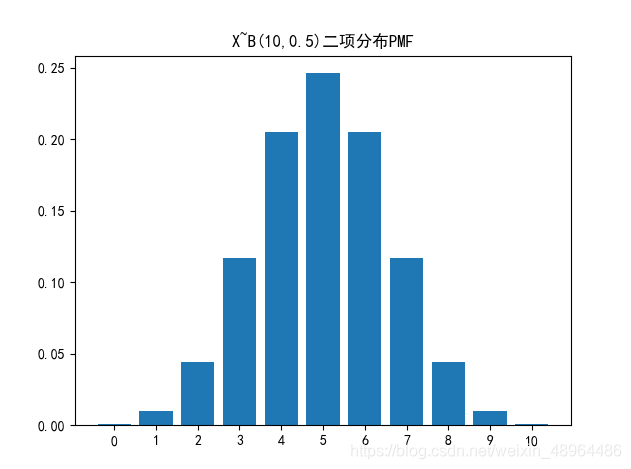
图像绘制
#传入时n+1是因为10次实验有十一种可能的结果组合。
n=10 # 十次试验
p=0.5
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
b = [stats.binom.pmf(i, n, p) for i in range(0,n+1)]
plt.bar([str(i) for i in range(0,len(b))],b)
plt.title(‘X~B({},{})二项分布PMF’.format(n,p))
plt.show()
3.3.2 CDF及其图像绘制
可以直接用pmf()函数解决这个问题。
#stats.binom.pmf函数很神奇,传入的第一个参数是数字(指定伯努利试验成功的次数),生成结果就也是一个数字。如果传入的第一个参数是数组,则会将会以该数组的shape输出其中每个数字成功次数的条件下,对应的概率。
dd = stats.binom.pmf(np.arange(0, 21, 1), 100, 0.5)
dd

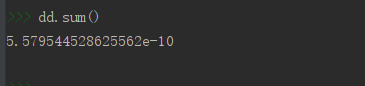
然后对数组求和即求出小于等于20次发生这一事件的概率
dd.sum()
此外,也可以用binom中的cdf()函数来直接解决这个问题
依然100次试验成功20次,每次p=0.5
stats.binom.cdf(20,100,0.5)

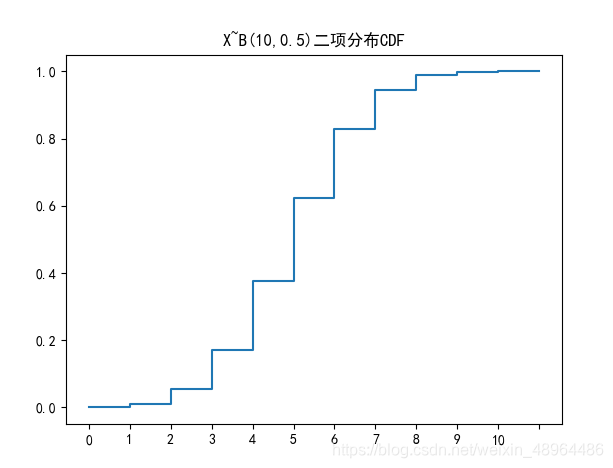
图像绘制
n=10 # 十次试验
p=0.5
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
plt.title(‘X~B({},{})二项分布CDF’.format(n,p))
c = [str(i//2) for i in range(0, 2*(n+1))]
c.append(‘’)
d = [stats.binom.cdf(i//2, n, p) for i in range(0, 22)]
d.insert(0,0)
plt.plot(c,d)
plt.show()
3.3.3 二项分布在金融市场的应用
二项分布常常用于描述金融市场中只有两个结果的重复事件。
如研究平安银行股票2020年数据:
导入相关模块
import numpy as np
import tushare as ts
import pandas as pd
from scipy import stats
设定好接口 注意这句不能照抄,需要输入自己的接口密匙
token = ‘Your token’ # 输入你的接口密匙,获取方式及相关权限见Tushare官网。
pro = ts.pro_api(token)
获取数据
df = pro.daily(ts_code=‘000001.SZ’) # daily为tushare的股票日线数据接口。
df[‘trade_date’] = pd.to_datetime(df[‘trade_date’])
df.set_index([‘trade_date’], inplace=True) # 将日期列作为行索引
df = df.sort_index()
ret = df.pct_chg[‘2020’]
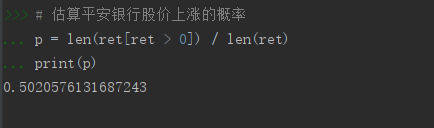
估算平安银行股价上涨的概率
p = len(ret[ret > 0]) / len(ret)
print§
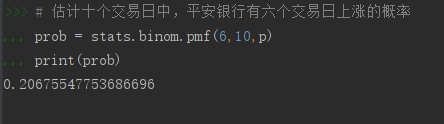
估计十个交易日中,平安银行有六个交易日上涨的概率
prob = stats.binom.pmf(6,10,p)
print(prob)
==============================================================================
正态分布(Normal Distribution)又名高斯分布(Gaussiam Distribution),是人们最常用的描述连续型随机变量的概率分布。在金融学研究中,收益率等变量的分布假定为正态分布或者对数正态分布(取对数后服从正态分布)。因为形状的原因,正态分布曲线也被经常称为钟形曲线。
正态分布分布律: 若随机变量X满足服从一个数学期望为u, 方差为 σ 2 \displaystyle \sigma^2 σ2的正态分布,记为X ~ ( N , σ 2 ) \displaystyle(N,\sigma^2 ) (N,σ2),则X的取值范围为( − ∞ , + ∞ \displaystyle -\infty,+\infty −∞,+∞),其概率密度为:
f X ( x ) = 1 2 π σ e x p [ − ( x − u ) 2 2 σ 2 ] \displaystyle f_X\relax{(x)}=\frac{1}{\sqrt{2\pi\sigma}}exp\left[\frac{-(x-u)2}{2\sigma2}\right] fX(x)=2πσ 1exp[2σ2−(x−u)2]
均值越大图像越靠右,方差越小图像越瘦高
服从正态分布的变量X满足其线性变换aX+b~( a u + b , a 2 σ 2 \displaystyle au+b,a2\sigma2 au+b,a2σ2)。
若令a = 1 σ \displaystyle\frac{1}{\sigma} σ1,b = − u σ \displaystyle\frac{-u}{\sigma} σ−u,即可得到标准正态分布,该过程即标准化,数学式记作:
Z = X − u σ \displaystyle Z=\frac{X-u}{\sigma} Z=σX−u ~ N ( 0 , 1 ) \displaystyle(0,1) (0,1)
任何正态分布都可以进行标准化,转变成标准正态分布。
正态分布随机数的生成函数是normal(),其语法为:
normal(loc=0.0, scale=1.0, size=None)
-
参数loc:表示正态分布的均值
-
参数scale:表示正态分布的标准差,默认为1
-
参数size:表示生成随机数的数量
生成五个标准正态分布随机数
Norm = np.random.normal(size=5)
求生成的正态分布随机数的密度值
stats.norm.pdf(Norm)
求生成的正态分布随机数的累积密度值
stats.norm.cdf(Norm)
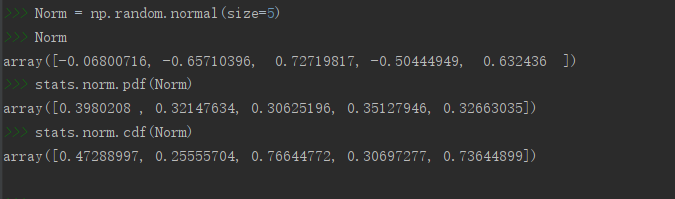
绘制正态分布PDF
注意这里使用的pdf和cdf函数是norm包里的
u=0
sigma=1
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
plt.title(‘X~N({},{})正态分布PDF’.format(u,sigma**2))
x = np.linspace(-5,5,100000) # 设定分割区间
y1 = stats.norm.pdf(x,u,sigma**2)
plt.plot(x,y1)
plt.tight_layout() # 自动调整子图,使之充满画布整个区域
plt.show()
图像效果:
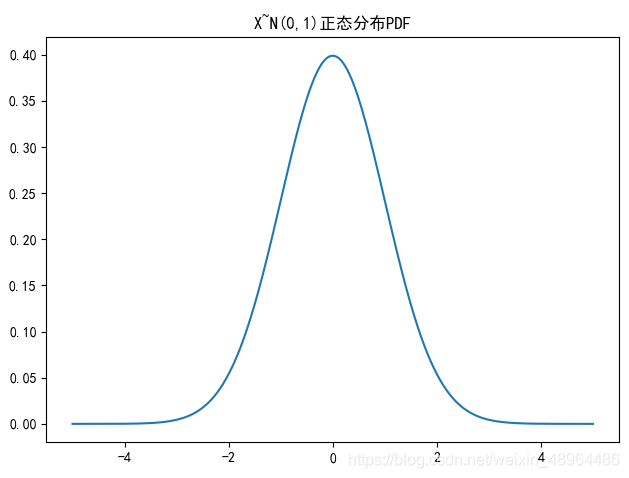
绘制正态分布CDF
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
plt.title(‘X~N({},{})正态分布CDF’.format(u,sigma**2))
x = np.linspace(-5,5,100000) # 设定分割区间
y2 = stats.norm.cdf(x,u,sigma**2)
plt.plot(x,y2)
plt.tight_layout()
plt.show()
图像效果:
VAR(Value at Risk),即在险价值。是指在一定概率水平(α%)下,某一金融资产或金融资产组合在未来特定一段时间内的最大可能的损失,该定义可表达为: P { X t < − V a R } \displaystyle P\{X_t < -VaR\} P{Xt<−VaR} = α%
其中,随机变量Xt为金融资产或金融资产组合在持有期 Δ t \displaystyle \Delta t Δt内的损失,1-α%被叫做VaR的置信水平。
这里用到了ppf() 函数,来获取指定分位数的累积密度值。
假设平安银行股价2020年日收益率序列服从正态分布,下面用Python来求解当概率水平为5%时平安银行股价日收益率在2021年初个交易日的VaR:
上边已经定义过ret变量了,为平安银行2020年股价日收益率数据,
这里直接接着使用
ret_mean = ret.mean() # 求均值
ret_variance = ret.var() # 求方差
查询累积密度值为0.05的分位数
stats.norm.ppf(0.05, ret_mean, ret_variance**0.5)

也就是说,在2021年的第一个交易日,有95%概率平安银行股票的损失不会超过3.475523569%。
(虽然当天实际跌了3.83,产生了异常值。)
================================================================================
若Z1, Z2, … Zn,为n个服从标准正态分布的随机变量,则变量:
X = Z 1 2 + Z 2 2 + ⋯ + Z n 2 \displaystyle X=Z_12+Z_22+\cdots+Z_n^2 X=Z12+Z22+⋯+Zn2
服从自由度(Degree of Freedom)为n的卡方分布,
通常表示为 X 2 \displaystyle X^2 X2~ χ 2 \displaystyle \chi^2 χ2
因为n的取值可以不同,所以卡方分布是一族分布而不是一个单独的分布。根据X的表达式,服从卡方分布的随机变量值不可能取负值,其期望值为n,方差为2n。
plt.plot(np.arange(0, 5, 0.002),\
stats.chi.pdf(np.arange(0, 5, 0.002), 3))
plt.title(‘卡方分布PDF(自由度为3)’)
生成图像如下:
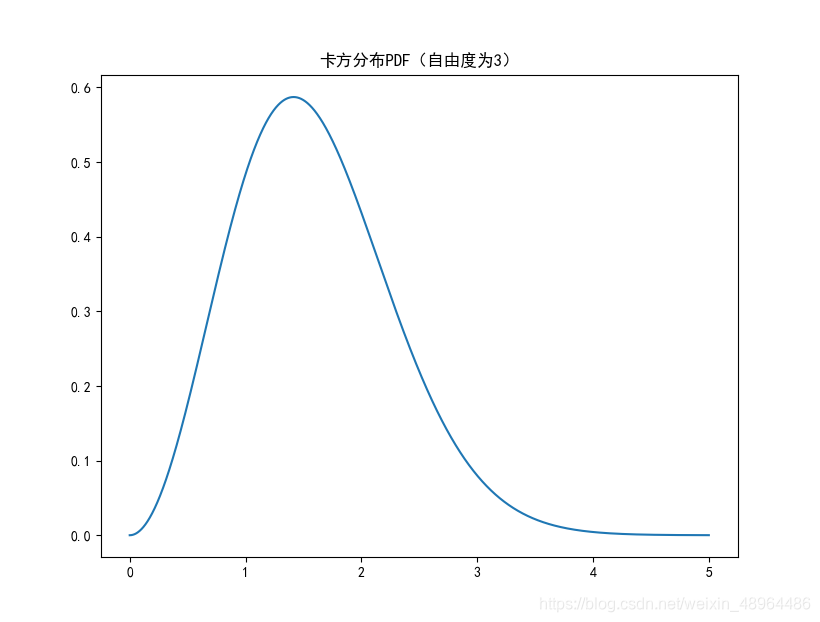
卡方分布以0为起点,分布是偏斜的,即非对称的,在自由度为3的卡方分布下,大多数值都小于8,查表可知只有5%的值大于7.82%。
若随机变量 Z \displaystyle Z Z ~ N ( 0 , 1 ) \displaystyle N(0,1) N(0,1), Y \displaystyle Y Y ~ χ 2 ( n ) \displaystyle\chi^2(n) χ2(n),且二者相互独立,
则变量 X = Z Y / n \displaystyle X=\frac{Z}{\sqrt{Y/n}} X=Y/n Z服从自由度为n的t分布,
可以记作 X \displaystyle X X~ t ( n ) \displaystyle t(n) t(n)。
类似卡方分布,t分布也是整整一族,自由度n不同t分布即不同。
t分布变量取值范围为( − ∞ , + ∞ \displaystyle -\infty,+\infty −∞,+∞),其期望值与方差存在于否,取值大小均与t分布的自由度有关。
-
t(1)分布无有限期望值。
-
t(2)有有限期望值,但方差不存在。
-
n>2时,t(n)才同时有有限的期望值和方差,其中期望值为0,方差为n/(n-2),因此自由度越大,变量的方差越小,也就是说分布的离散程度越小。
下边使用Python绘制不同自由度下的t分布的概率分布图:
x = np.arange(-4,4.004,0.004)
plt.plot(x, stats.norm.pdf(x), label=‘Normal’)
plt.plot(x, stats.t.pdf(x,5), label=‘df=5’)
plt.plot(x, stats.t.pdf(x,30), label=‘df=30’)
plt.legend()
结果如图所示:
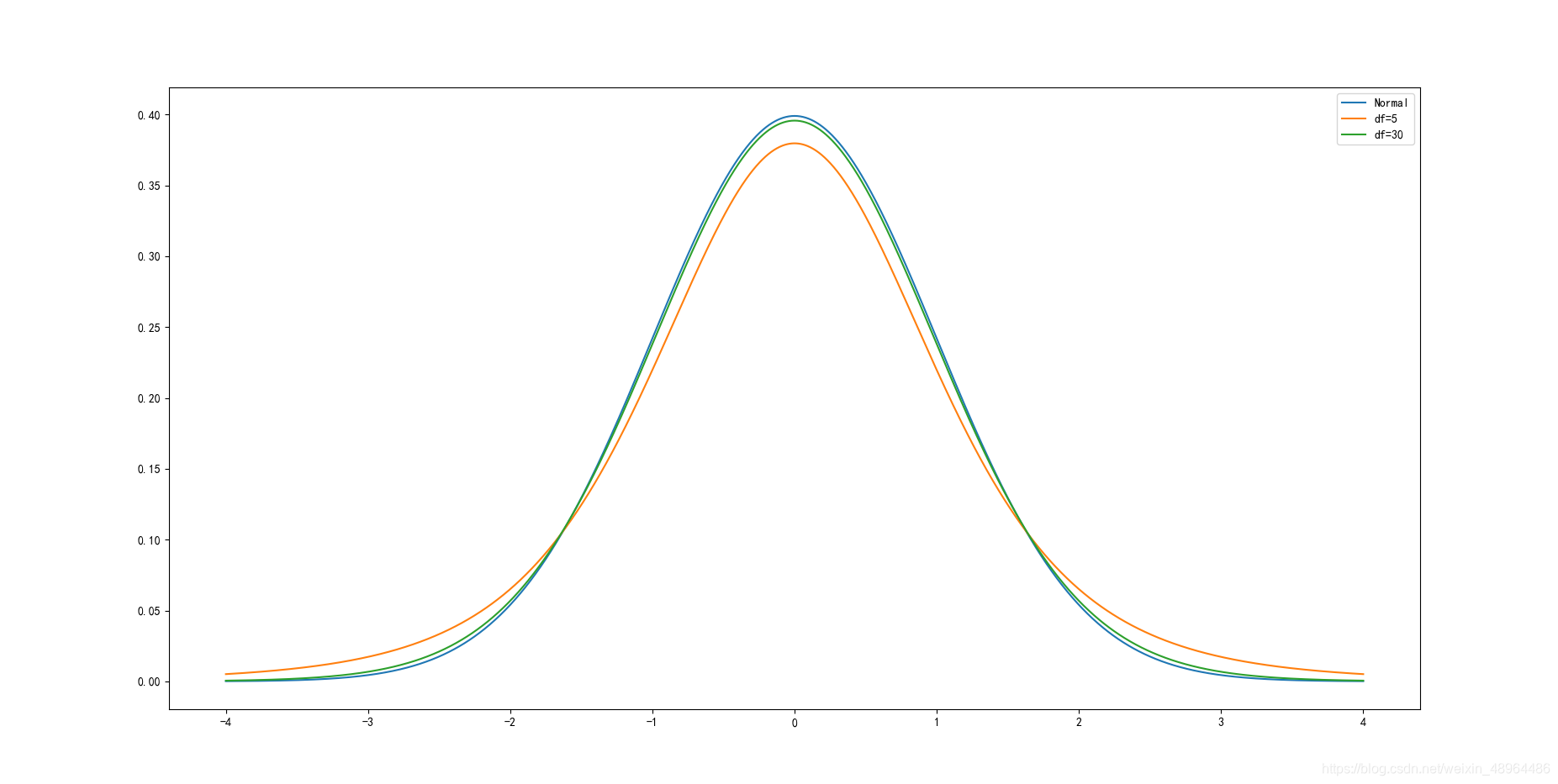
t分布的pdf曲线是以0为中心,左右对称的单峰分布,其形态变化与自由度n的大小有关,自由度越小,分布越分散;自由度越大,变量在其均值周围的聚集程度越高,也越接近标准正态分布曲线。
自由度为30时,t分布已经接近标准正态分布曲线。相较于标准正态分布,t分布的密度函数呈现出“尖峰厚尾”的特点。在现实中资产收益率分布往往呈现这种形态,因此t分布在对实际抽样结果的刻画上更为精确。t分布是在推断统计中常用的分布。
————
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 7342
7342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









