







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
目录
引出
1.散列表,key,散列函数;
2.哈希冲突的解决;
3.string中的hashCode;
散列表Hash table
查找树ADT,它允许对元素的集合进行各种操作。本章讨论散列表(hash table)ADT,不过它只支持二叉查找树所允许的一部分操作。散列表的实现常常叫作散列(hashing)。散列是一种用于以常数平均时间执行插入、删除和查找的技术。但是,那些需要元素间任何排序信息的树操作将不会得到有效的支持。因此,诸如findMin、findMax以及以线性时间将排过序的整个表进行打印的操作都是散列所不支持的。
- 看到实现散列表的几种方法。
- 解析地比较这些方法。
- 介绍散列的多种应用。
- 将散列表和二叉查找树进行比较。
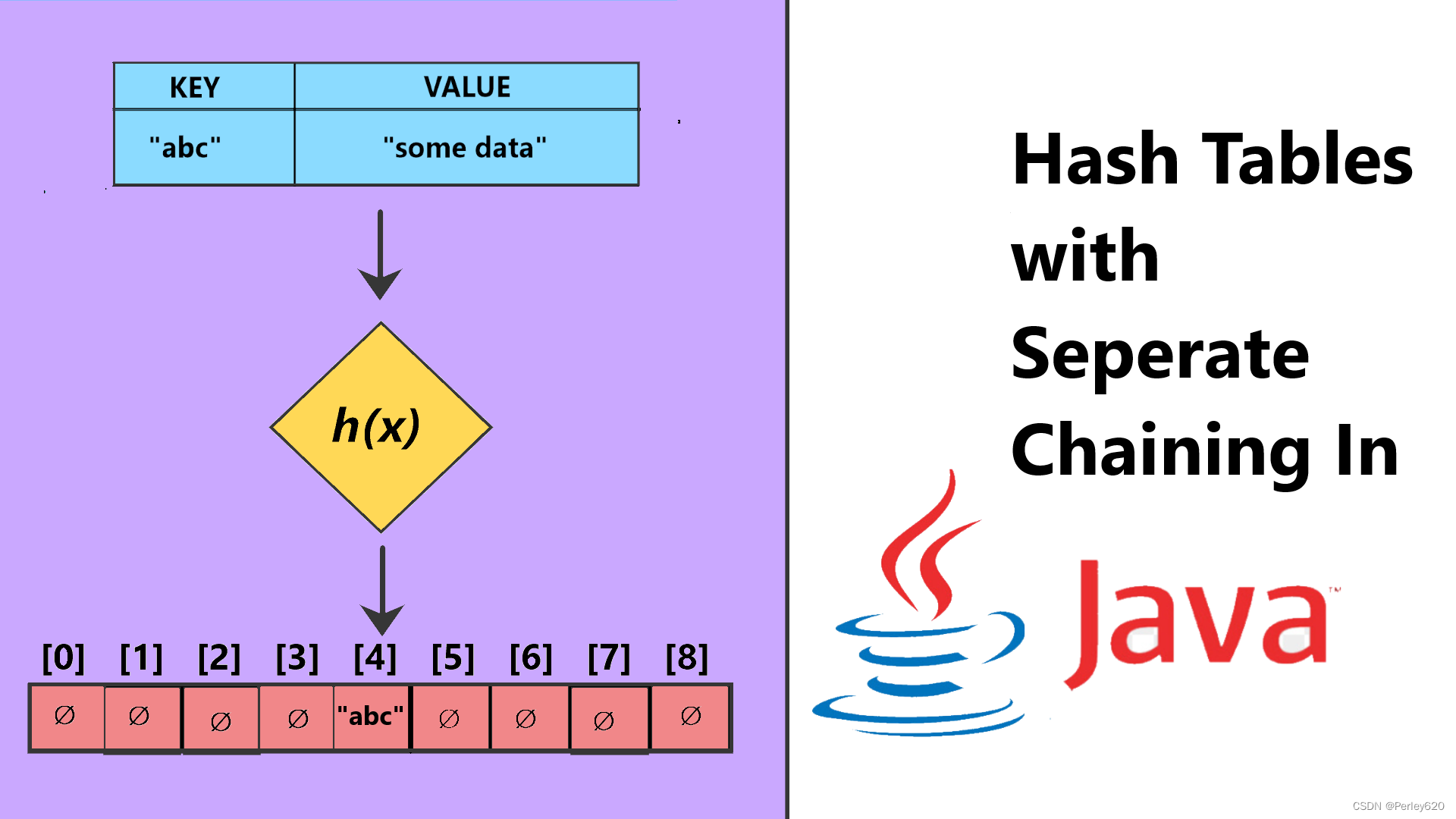
关键字Key和散列函数(hash function)
理想的散列表数据结构只不过是一个包含一些项(itm)的具有固定大小的数组。通常查找是对项的某个部分(即数据域)进行的。这部分就叫作关键字(key)。
例如,项可以由一个字符串(它可以作为关键字)和其他一些数据域组成(例如,姓名是大型雇员结构的一部分)。我们把表的大小记作TableSize,并将其理解为散列数据结构的一部分,而不仅仅是浮动于全局的某个变量。通常的习惯是让表从0到TableSize-1变化;稍后我们就会明白为什么要这样做。
每个关键字被映射到从0到TableSize-1这个范围中的某个数,并且被放到适当的单元中。这个映射就叫作散列函数(hash function),理想情况下它应该计算起来简单,并且应该保证任何两个不同的关键字映射到不同的单元。不过,这是不可能的,因为单元的数目是有限的,而关键字实际上是用不完的。因此,我们寻找一个散列函数,该函数要在单元之间均匀地分配关键字。
图5-1是完美情况的一个典型。在这个例子中,john散列到3,phil散列到4,dave散列到6,mary散列到7。

这就是散列的基本想法。剩下的问题就是要选择一个函数,决定当两个关键字散列到同一个值的时候(这叫作冲突(collision))应该做什么以及如何确定散列表的大小。
散列函数

这个散列函数利用到事实:允许溢出。这可能会引进负的数,因此在末尾有附加的测试。图5-4所描述的散列函数就表的分布而言未必是最好的,但确实具有极其简单的优点而且速度也很快。如果关键字特别长,那么该散列函数计算起来将会花费过多的时间。在这种情况下通常的经验是不使用所有的字符。此时关键字的长度和性质将影响选择。例如,关键字可能是完整的街道地址,散列函数可以包括街道地址的几个字符,也许还有城市名和邮政编码的几个字符。有些程序设计人员通过只使用奇数位置上的字符来实现他们的散列函数,这里有这么一层想法:用计算散列函数节省下的时间来补偿由此产生的对均匀地分布的函数的轻微干扰。

解决collision哈希冲突(碰撞)
剩下的主要编程细节是解决冲突的消除问题。如果当一个元素被插入时与一个已经插入的元素散列到相同的值,那么就产生一个冲突,这个冲突需要消除。解决这种冲突的方法有几种,我们将讨论其中最简单的两种:分离链接法和开放定址法。
分离链接法(separate chaining)
分离链接法(separate chaining)
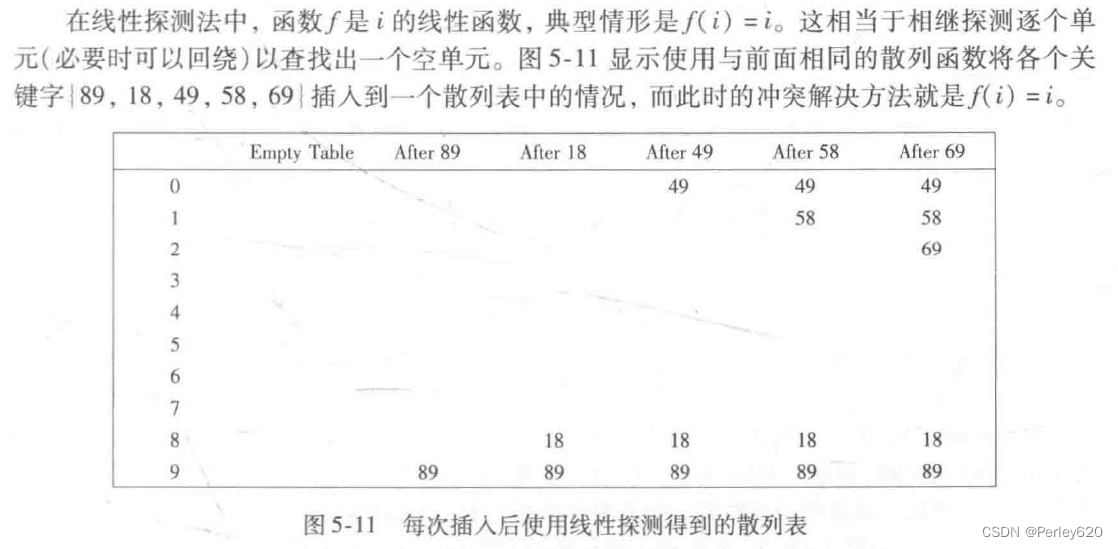
解决冲突的第一种方法通常叫作分离链接法(separate chaining),其做法是将散列到同一个值的所有元素保留到一个表中。我们可以使用标准库表的实现方法。如果空间很紧,则更可取的方法是避免使用它们(因为这些表是双向链接的并且浪费空间)。本节我们假设关键字是前10个完全平方数并设散列函数就是hash(x)=xmod10(表的大小不是素数,用在这里是为了简单)。
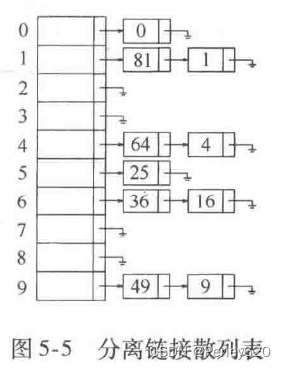
探测散列表(probing hash table)
探测散列表(probing hash table)

分离链接散列算法的缺点是使用一些链表。由于给新单元分配地址需要时间(特别是在其他语言中),因此这就导致算法的速度有些减慢,同时算法实际上还要求对第二种数据结构的实现。另有一种不用链表解决冲突的方法是尝试另外一些单元,直到找出空的单元为止。更常见的是,单元h(x),h,(x),h2(x),…相继被试选,其中h:(x)=(hash(x)+f(i)mod
TableSize,且f(0)=0。函数f是冲突解决方法。因为所有的数据都要置入表内,所以这种解决方案所需要的表要比分离链接散列的表大。一般说来,对于不使用分离链接的散列表来说,其装填因子应该低于入=0.5。我们把这样的表叫作探测散列表(probing hash table)。现在我们就来考察三种通常的冲突解决方案。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上软件测试知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









