







 文章介绍了在ApacheSpark中,通过reduceByKey操作对省份和城市进行数据统计,以及如何处理数据倾斜问题,通过自定义分区器实现更均衡的负载。还强调了系统化学习的重要性,鼓励读者加入技术交流社区以共同成长。
文章介绍了在ApacheSpark中,通过reduceByKey操作对省份和城市进行数据统计,以及如何处理数据倾斜问题,通过自定义分区器实现更均衡的负载。还强调了系统化学习的重要性,鼓励读者加入技术交流社区以共同成长。
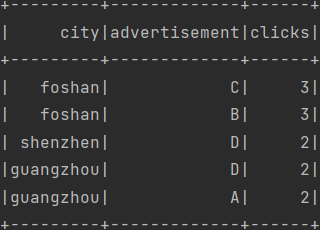
需求:省份点击数Top2
数据
// 创建SparkConf对象,并设定配置
import org.apache.spark.{SparkConf, SparkContext}
val conf = new SparkConf().setAppName("A").setMaster("local[8]")
// 创建SparkContext对象,Spark通过该对象访问集群
val sc = new SparkContext(conf)
// 创建数据
val r0 = sc.makeRDD(Seq(
4401, 4401, 4401, 4401, 4401, 4401, 4401,
4401, 4401, 4401, 4401, 4401, 4401,
4406, 4406, 4406, 4406, 4406, 4406, 4406, 4406,
4602, 4602, 4601,
4301, 4301,
))
方法1:reduceBy省份
// 省份汇总统计
val r1 = r0.map(a => (a.toString.slice(0, 2), 1)).reduceByKey(_ + _)
// 查看各分区元素
r1.mapPartitionsWithIndex((pId, iter) => {
println("分区" + pId + "元素:" + iter.toList)
iter
}).collect
// 省份TopN
r1.sortBy(-_._2).take(2).foreach(println)
方法2:先reduceBy城市,再reduceBy省份
reduceBy城市可以使并行更充分,缓解数据倾斜
// reduceBy城市
val r1 = r0.map((_, 1)).reduceByKey(_ + _)
// 查看各分区元素
r1.mapPartitionsWithIndex((pId, iter) => {
println("分区" + pId + "元素:" + iter.toList)
iter
}).collect
// reduceBy省份
val r2 = r1.map(t => (t._1.toString.slice(0, 2), t._2)).reduceByKey(_ + _)
// 查看各分区元素
r2.mapPartitionsWithIndex((pId, iter) => {
println("分区" + pId + "元素:" + iter.toList)
iter
}).collect
// 省份TopN
r2.sortBy(-_._2).take(2).foreach(println)
打印
reduceBy城市各分区元素
分区4元素:List()
分区3元素:List()
分区7元素:List()
分区0元素:List()
分区2元素:List((4602,2))
分区6元素:List((4406,8))
分区5元素:List((4301,2))
分区1元素:List((4401,13), (4601,1))
reduceBy省份各分区元素
分区5元素:List()
分区3元素:List()
分区1元素:List()
分区4元素:List()
分区6元素:List()
分区7元素:List((43,2))
分区0元素:List((44,21))
分区2元素:List((46,3))
结果
(44,21)
(46,3)
自定义分区器 求TopN
自定义分区器可以缓解数据倾斜,后面需要二次聚合
import org.apache.spark.{HashPartitioner, Partitioner, SparkConf, SparkContext}
import scala.util.Random
class MyPartitioner extends Partitioner {
val random: Random = new Random
// 总的分区数
override def numPartitions: Int = 8
// 按key分区,此处假设44数据倾斜
override def getPartition(key: Any): Int = key match {
case "44" => random.nextInt(7)
case _ => 7
}
}
object Hello {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设定配置
val conf = new SparkConf().setAppName("A").setMaster("local[8]")
// 创建SparkContext对象,Spark通过该对象访问集群
val sc = new SparkContext(conf)
// 创建数据
val r0 = sc.makeRDD(Seq(
44, 44, 44, 44, 44, 44, 44,
44, 44, 44, 44, 44, 44,
44, 44, 44, 44, 44, 44, 44, 44,
46, 46, 46,
43, 43,
))
// 省份汇总统计
val r1 = r0.map(a => (a.toString.slice(0, 2), 1))
// 自定义分区
val r2 = r1.reduceByKey(partitioner = new MyPartitioner, func = _ + _)
// 查看各分区元素
r2.mapPartitionsWithIndex((pId, iter) => {
println("分区" + pId + "元素:" + iter.toList)
iter
}).collect
// 二次聚合
val r3 = r2.reduceByKey(partitioner = new HashPartitioner(1), func = _ + _)
// 查看各分区元素
r3.mapPartitionsWithIndex((pId, iter) => {
println("分区" + pId + "元素:" + iter.toList)
iter
}).collect
// TopN
r3.sortBy(-_._2).take(2).foreach(println)
}
}
某次随机自定义分区打印
分区4元素:List()
分区6元素:List()
分区1元素:List()
分区3元素:List((44,1))
分区7元素:List((46,3), (43,2))
分区0元素:List((44,6))
分区5元素:List((44,7))
分区2元素:List((44,7))
二次聚合分区打印
分区0元素:List((46,3), (44,21), (43,2))
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









