







目录
2. 词汇表构建(Vocabulary Construction)
三、Word2Vec 核心模型:Skip - Gram 与 CBOW
八、word2vec的两种经典模型(Skip - Gram 和 CBOW)的Python代码实现
一、引言
本文介绍的项目实现了 Word2Vec 的两种经典模型(Skip - Gram 和 CBOW),并采用负采样(Negative Sampling)优化损失计算,用于学习词向量表示,并用Python代码实现出来。
二、数据预处理算法
数据预处理是词向量学习的基础,目的是将原始文本转化为模型可处理的结构化数据。
1. 文本分词(Tokenization)
使用 NLTK 的sent_tokenize和word_tokenize工具进行分词:
- 句子分词:将文本分割为独立句子(
sent_tokenize) - 单词分词:将句子分割为单词 / 令牌(
word_tokenize)

2. 词汇表构建(Vocabulary Construction)
通过build_vocab方法构建词汇表,核心步骤包括:

3. 词频分布计算
get_word_distribution方法计算词频分布向量P(w),用于负采样:

三、Word2Vec 核心模型:Skip - Gram 与 CBOW
Word2Vec 的核心思想是通过上下文预测任务学习词的分布式表示,即词向量。其本质是假设语义相近的词具有相似的上下文分布,通过优化预测损失使词向量捕捉语义信息。
1. Skip - Gram 模型
Skip - Gram 模型的任务是:给定中心词w,预测其周围的上下文词c。
模型结构

传统 Softmax 损失(计算瓶颈)
理想情况下,模型应最大化条件概率P(c∣w),传统方法用 Softmax 计算:
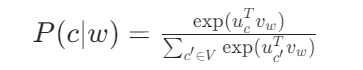
对数似然损失为:
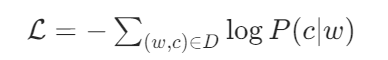
其中D为训练数据中的(中心词,上下文词)对集合。
但该方法计算复杂度极高(O(vocab_size)),因为分母需对整个词汇表求和,在大词汇表场景下不可行。
负采样(Negative Sampling)优化
负采样将多分类问题转化为多个二分类问题,核心思想:
- 对每个正样本(w,c)(真实上下文对),采样k个负样本
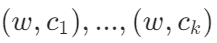 (非上下文对)
(非上下文对) - 用逻辑回归区分正样本和负样本
数学推导:

2. CBOW 模型
CBOW(Continuous Bag - of - Words)模型的任务是:给定上下文词集合C,预测中心词w。
模型结构

核心计算

四、负采样的采样分布
负采样的关键是如何选择负样本,代码采用 Word2Vec 原论文推荐的分布:
采样概率计算
- 基础分布:基于词频的0.75次方调整,降低高频词的采样概率:
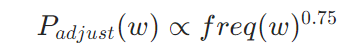
2. 归一化:确保分布和为 1:
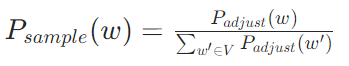
五、模型训练与优化
训练过程通过梯度下降最小化损失函数,核心算法包括:
1. 优化器
使用 Adam 优化器,其更新规则为:
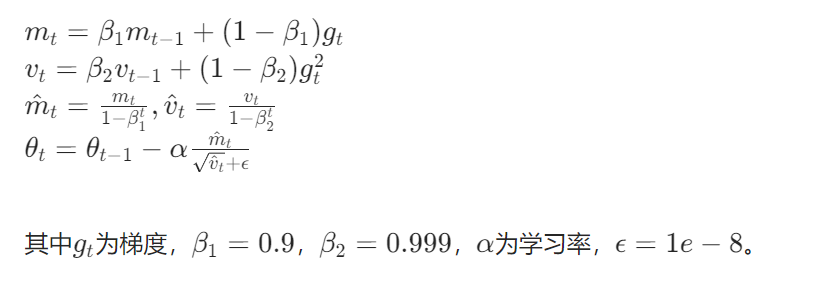
2. 梯度计算

总梯度为正项与负项梯度之和,PyTorch 通过自动求导(loss.backward())实现。
六、可视化算法:t - SNE 降维
为可视化高维词向量,使用 t - SNE(t - Distributed Stochastic Neighbor Embedding)算法将词向量从embed_size维降至 2 维。
核心原理

七、模型对比与总结
| 模型 | 任务 | 优势 | 劣势 |
|---|---|---|---|
| Skip - Gram | 中心词→上下文 | 对低频词更友好,语义捕捉更精准 | 训练速度较慢 |
| CBOW | 上下文→中心词 | 训练速度快,对高频词更稳健 | 低频词表示较差 |
两种模型均通过负采样解决了传统 Softmax 的计算瓶颈,使大规模词向量训练成为可能。词向量的质量可通过损失曲线(Visualizer.plot_loss)和 t - SNE 可视化(Visualizer.plot_word_embeddings)直观评估。
八、word2vec的两种经典模型(Skip - Gram 和 CBOW)的Python代码实现
以'Economic globalization'为训练语料库,在'Economic Globalization.txt'中,和Python代码位于同一目录。
Economic Globalization.txt
Economic globalization has been progressing rapidly since the beginning of the 1950s. Several factors have
contributed to such development. Firstly, advancements in science and technology have offered a technical foundation by
providing the material basis and the technical means. Meanwhile, a solid economic foundation for such a globalization
has been laid by the market economy which is prevailing over the world. Others factors include the pillaring and
propelling role of multinationals in micro-economic operations, the ever growing coordinating and controlling power and
function exercised by such international economic organizations as WTO, IMF and WB in the international trade and
finance.Python代码
# 安装NLTK,使用如下代码安装punkt组件
import nltk
nltk.download('punkt')
import numpy as np
from nltk.tokenize import sent_tokenize, word_tokenize
from collections import defaultdict
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.optim import Adam
from tqdm import trange
# 数据处理类
class TheLitterPrinceDataset:
def __init__(self, tokenize=True):
try:
text = open('Economic Globalization.txt', 'r', encoding='utf-8').read()
except FileNotFoundError:
print("警告:未找到'Economic Globalization.txt'文件,使用示例文本替代")
text = ("Economic globalization has enabled companies to source raw materials from across the globe,"
" manufacture products in low-cost regions, and sell them in international markets, creating "
"a highly interconnected global supply chain.")
if tokenize:
self.sentences = sent_tokenize(text.lower())
self.tokens = [word_tokenize(sent) for sent in self.sentences]
else:
self.text = text
def build_vocab(self, min_freq=1):
frequency = defaultdict(int)
for sentence in self.tokens:
for token in sentence:
frequency[token] += 1
self.frequency = frequency
self.token2id = {'<unk>': 1, '<pad>': 0}
self.id2token = {1: '<unk>', 0: '<pad>'}
for token, freq in sorted(frequency.items(), key=lambda x: -x[1]):
if freq > min_freq:
self.token2id[token] = len(self.token2id)
self.id2token[len(self.id2token)] = token
else:
break
def get_word_distribution(self):
vocab_size = len(self.token2id)
distribution = np.zeros(vocab_size)
for token, freq in self.frequency.items():
if token in self.token2id:
distribution[self.token2id[token]] = freq
else:
distribution[1] += freq
distribution /= distribution.sum() if distribution.sum() > 0 else 1
return distribution
def convert_tokens_to_ids(self, drop_single_word=True):
self.token_ids = []
for sentence in self.tokens:
token_ids = [self.token2id.get(token, 1) for token in sentence]
if len(token_ids) == 1 and drop_single_word:
continue
self.token_ids.append(token_ids)
return self.token_ids
# Skip-Gram模型
class SkipGramNCE(nn.Module):
def __init__(self, vocab_size, embed_size, distribution, neg_samples=20):
super(SkipGramNCE, self).__init__()
print(f'Skip-Gram: vocab_size={vocab_size}, embed_size={embed_size}, neg_samples={neg_samples}')
self.input_embeddings = nn.Embedding(vocab_size, embed_size)
self.output_embeddings = nn.Embedding(vocab_size, embed_size)
distribution = np.power(distribution, 0.75)
distribution /= distribution.sum() if distribution.sum() > 0 else 1
self.distribution = torch.tensor(distribution)
self.neg_samples = neg_samples
def forward(self, input_ids, labels):
i_embed = self.input_embeddings(input_ids)
o_embed = self.output_embeddings(labels)
batch_size = i_embed.size(0)
# 确保负采样数量合理
try:
n_words = torch.multinomial(self.distribution, batch_size * self.neg_samples,
replacement=True).view(batch_size, -1)
except:
# 处理分布可能出现的问题
self.distribution = torch.clamp(self.distribution, min=1e-8)
self.distribution /= self.distribution.sum()
n_words = torch.multinomial(self.distribution, batch_size * self.neg_samples,
replacement=True).view(batch_size, -1)
n_embed = self.output_embeddings(n_words)
pos_term = F.logsigmoid(torch.sum(i_embed * o_embed, dim=1))
neg_term = F.logsigmoid(-torch.bmm(n_embed, i_embed.unsqueeze(2)).squeeze())
neg_term = torch.sum(neg_term, dim=1)
loss = -torch.mean(pos_term + neg_term)
return loss
# CBOW模型
class CBOWNCE(nn.Module):
def __init__(self, vocab_size, embed_size, distribution, neg_samples=20):
super(CBOWNCE, self).__init__()
print(f'CBOW: vocab_size={vocab_size}, embed_size={embed_size}, neg_samples={neg_samples}')
self.embeddings = nn.Embedding(vocab_size, embed_size)
distribution = np.power(distribution, 0.75)
distribution /= distribution.sum() if distribution.sum() > 0 else 1
self.distribution = torch.tensor(distribution)
self.neg_samples = neg_samples
def forward(self, input_ids, labels):
embed = self.embeddings(input_ids)
context_embed = torch.mean(embed, dim=1)
o_embed = self.embeddings(labels)
batch_size = context_embed.size(0)
# 确保负采样数量合理
try:
n_words = torch.multinomial(self.distribution, batch_size * self.neg_samples,
replacement=True).view(batch_size, -1)
except:
self.distribution = torch.clamp(self.distribution, min=1e-8)
self.distribution /= self.distribution.sum()
n_words = torch.multinomial(self.distribution, batch_size * self.neg_samples,
replacement=True).view(batch_size, -1)
n_embed = self.embeddings(n_words)
pos_term = F.logsigmoid(torch.sum(context_embed * o_embed, dim=1))
neg_term = F.logsigmoid(-torch.bmm(n_embed, context_embed.unsqueeze(2)).squeeze())
neg_term = torch.sum(neg_term, dim=1)
loss = -torch.mean(pos_term + neg_term)
return loss
# 数据处理工具
class DataCollator:
@classmethod
def collate_batch_skipgram(cls, batch):
batch = np.array(batch)
input_ids = torch.tensor(batch[:, 0], dtype=torch.long)
labels = torch.tensor(batch[:, 1], dtype=torch.long)
return {'input_ids': input_ids, 'labels': labels}
@classmethod
def collate_batch_cbow(cls, batch):
contexts, targets = zip(*batch)
contexts = [torch.tensor(ctx, dtype=torch.long) for ctx in contexts]
contexts = nn.utils.rnn.pad_sequence(contexts, batch_first=True)
targets = torch.tensor(targets, dtype=torch.long)
return {'input_ids': contexts, 'labels': targets}
# 可视化工具
class Visualizer:
@staticmethod
def plot_loss(epoch_loss, model_name="Model"):
plt.figure(figsize=(10, 6))
plt.plot(range(len(epoch_loss)), epoch_loss)
plt.xlabel('Training Epoch')
plt.ylabel('Loss')
plt.title(f'{model_name} Training Loss')
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
@staticmethod
def plot_word_embeddings(model, dataset, top_n=100, model_type="skipgram"):
# 获取词汇表大小
vocab_size = len(dataset.token2id)
# 确保top_n不超过词汇表大小
top_n = min(top_n, vocab_size)
# 获取词向量
if model_type == "skipgram":
embeddings = model.input_embeddings.weight.detach().cpu().numpy()
else:
embeddings = model.embeddings.weight.detach().cpu().numpy()
# 使用t-SNE降维
tsne = TSNE(n_components=2, random_state=42, perplexity=min(15, top_n - 1))
embeddings_2d = tsne.fit_transform(embeddings[:top_n])
plt.figure(figsize=(12, 10))
for i in range(top_n):
# 确保索引在id2token中存在
if i not in dataset.id2token:
continue
word = dataset.id2token[i]
x, y = embeddings_2d[i]
plt.scatter(x, y, marker='o', color='blue')
plt.annotate(word, (x, y), xytext=(5, 2), textcoords='offset points',
ha='right', va='bottom', fontsize=9)
plt.title(f'Word Embeddings Visualization ({model_type})')
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
@staticmethod
def compare_models_loss(losses, model_names):
plt.figure(figsize=(10, 6))
for i, loss in enumerate(losses):
plt.plot(range(len(loss)), loss, label=model_names[i])
plt.xlabel('Training Epoch')
plt.ylabel('Loss')
plt.title('Comparison of Model Training Losses')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
# 训练函数
def train_model(model, dataloader, optimizer, epochs, model_name="Model"):
epoch_loss = []
model.train()
with trange(epochs, desc='epoch', ncols=80) as pbar:
for epoch in pbar:
batch_losses = []
for step, batch in enumerate(dataloader):
optimizer.zero_grad()
loss = model(**batch)
loss.backward()
optimizer.step()
batch_losses.append(loss.item())
pbar.set_description(f'{model_name} epoch-{epoch}, loss={loss.item():.4f}')
if batch_losses: # 确保有损失值才添加
epoch_loss.append(np.mean(batch_losses))
return epoch_loss
# 主程序
if __name__ == "__main__":
# 数据准备
dataset = TheLitterPrinceDataset()
dataset.build_vocab(min_freq=1)
sentences = dataset.convert_tokens_to_ids()
vocab_size = len(dataset.token2id)
print(f"词汇表大小: {vocab_size}")
if vocab_size < 2:
print("词汇表太小,无法继续训练")
else:
distribution = dataset.get_word_distribution()
embed_size = 128
window_size = 2
# 准备Skip-Gram数据
skipgram_data = []
for sentence in sentences:
for i in range(len(sentence)):
for j in range(i - window_size, i + window_size + 1):
if j == i or j < 0 or j >= len(sentence):
continue
skipgram_data.append([sentence[i], sentence[j]])
skipgram_data = np.array(skipgram_data)
print(f"Skip-Gram数据量: {len(skipgram_data)}")
# 准备CBOW数据
cbow_data = []
for sentence in sentences:
for i in range(len(sentence)):
context = []
for j in range(i - window_size, i + window_size + 1):
if j == i or j < 0 or j >= len(sentence):
continue
context.append(sentence[j])
if len(context) > 0:
cbow_data.append([context, sentence[i]])
print(f"CBOW数据量: {len(cbow_data)}")
# 模型训练参数
epochs = 50
batch_size = 128
learning_rate = 1e-3
# 训练Skip-Gram模型
if len(skipgram_data) > 0:
skipgram_model = SkipGramNCE(vocab_size, embed_size, distribution)
skipgram_dataloader = DataLoader(
skipgram_data,
batch_size=batch_size,
shuffle=True,
collate_fn=DataCollator.collate_batch_skipgram
)
skipgram_optimizer = Adam(skipgram_model.parameters(), lr=learning_rate)
skipgram_loss = train_model(skipgram_model, skipgram_dataloader,
skipgram_optimizer, epochs, "Skip-Gram")
# 可视化
Visualizer.plot_loss(skipgram_loss, "Skip-Gram")
Visualizer.plot_word_embeddings(skipgram_model, dataset, model_type="skipgram")
else:
print("没有足够的Skip-Gram数据进行训练")
# 训练CBOW模型
if len(cbow_data) > 0:
cbow_model = CBOWNCE(vocab_size, embed_size, distribution)
cbow_dataloader = DataLoader(
cbow_data,
batch_size=batch_size,
shuffle=True,
collate_fn=DataCollator.collate_batch_cbow
)
cbow_optimizer = Adam(cbow_model.parameters(), lr=learning_rate)
cbow_loss = train_model(cbow_model, cbow_dataloader,
cbow_optimizer, epochs, "CBOW")
# 可视化
Visualizer.plot_loss(cbow_loss, "CBOW")
Visualizer.plot_word_embeddings(cbow_model, dataset, model_type="cbow")
# 比较两个模型
if 'skipgram_loss' in locals():
Visualizer.compare_models_loss([skipgram_loss, cbow_loss], ["Skip-Gram", "CBOW"])
else:
print("没有足够的CBOW数据进行训练")
九、程序运行结果

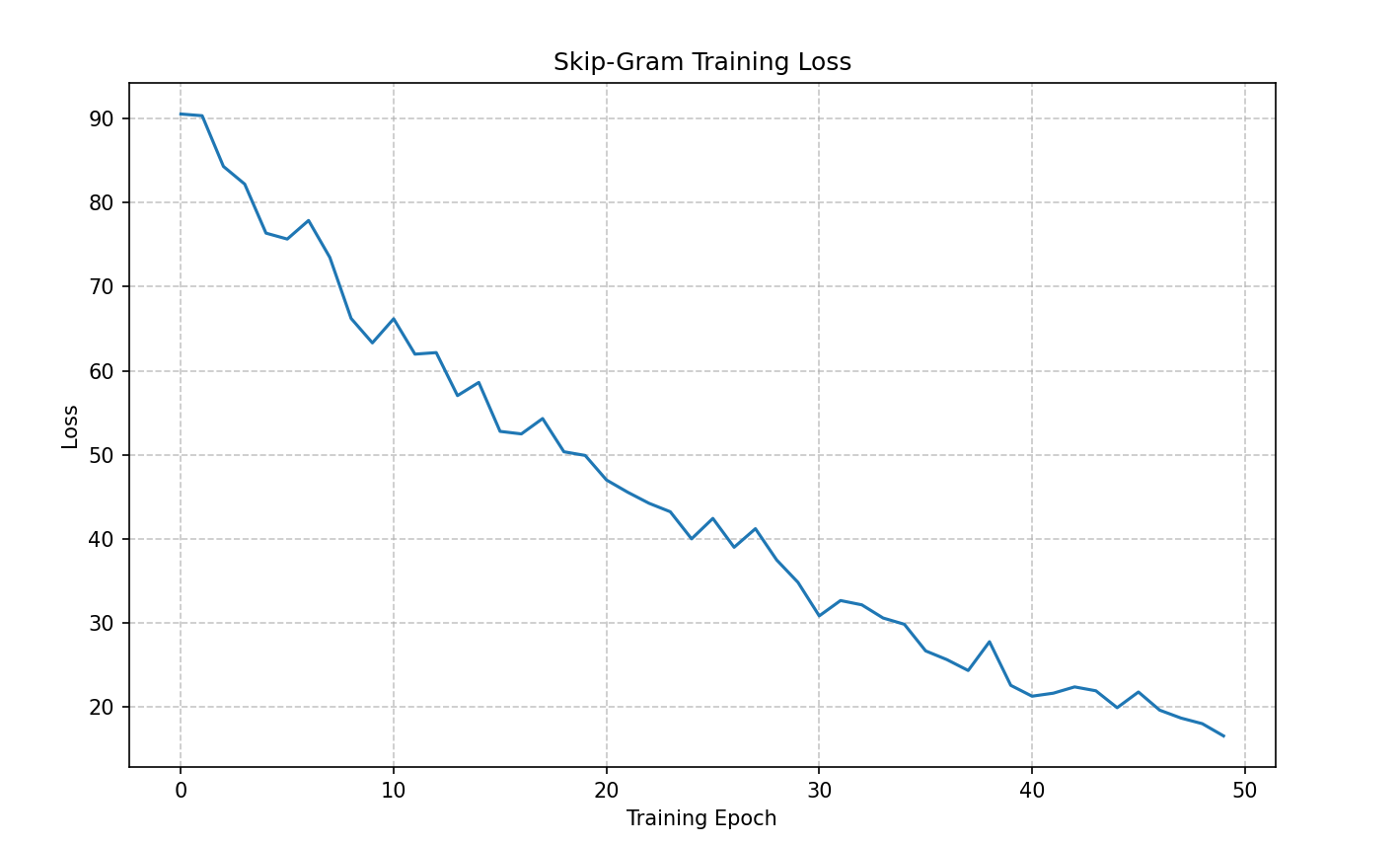
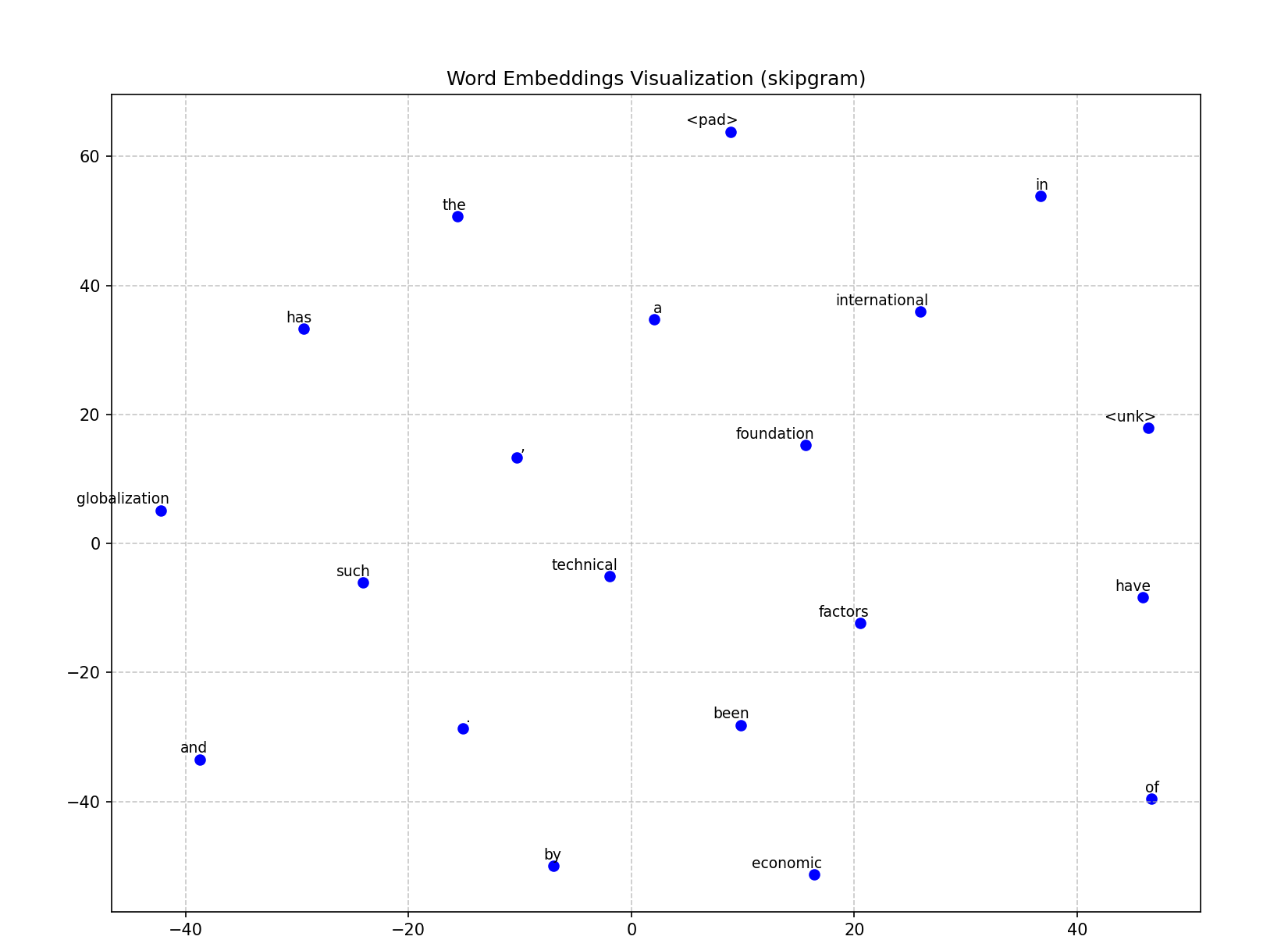

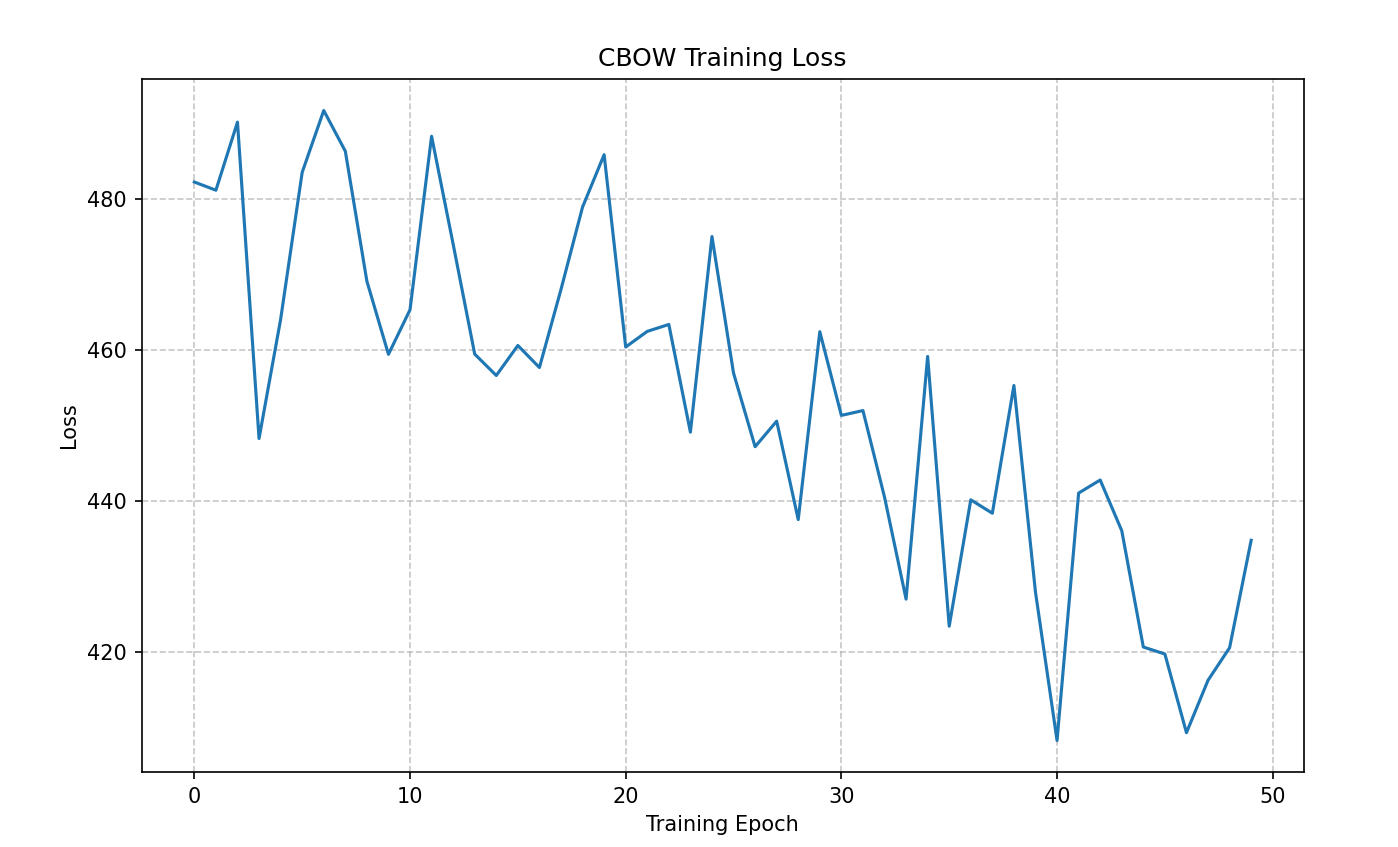
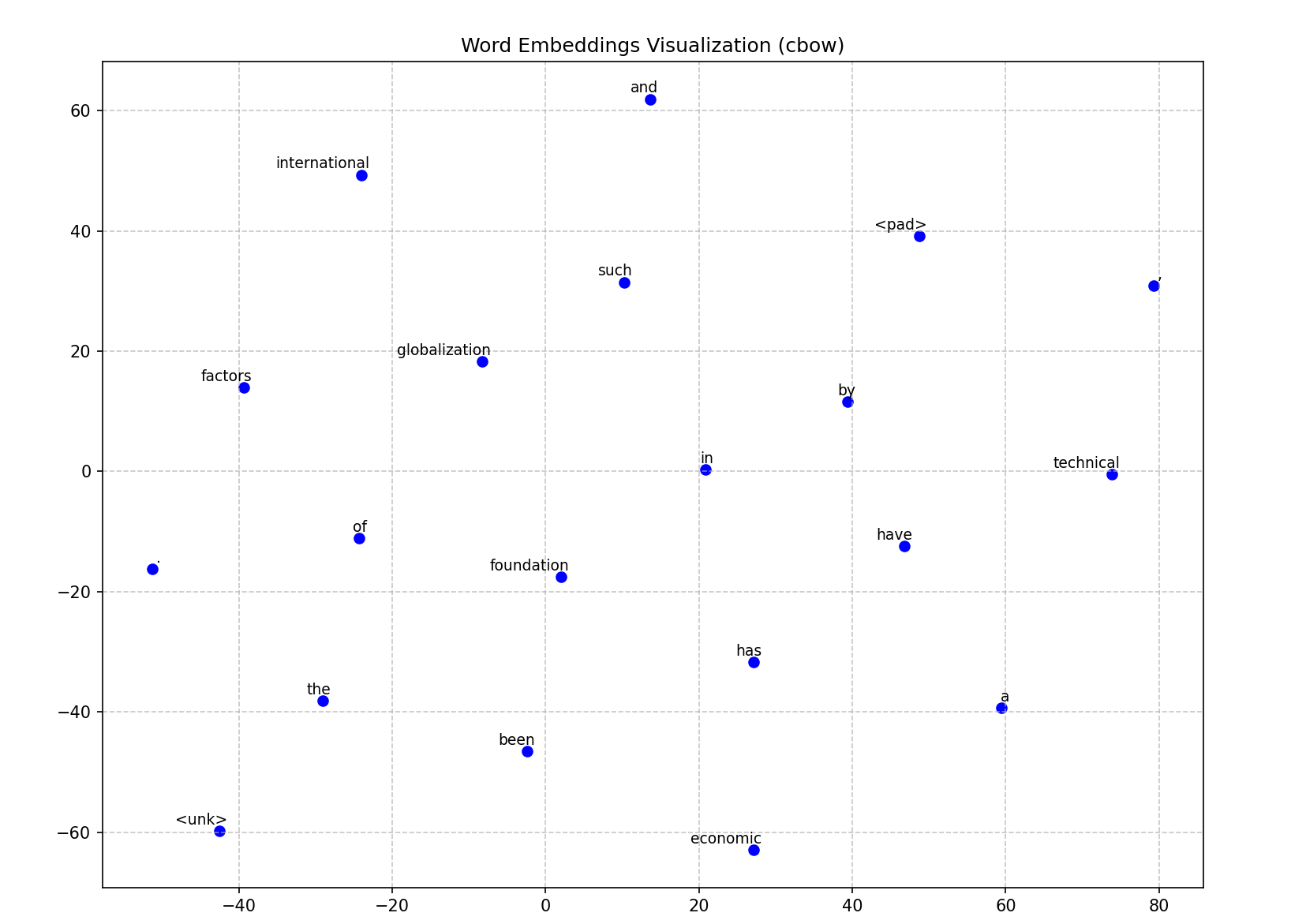
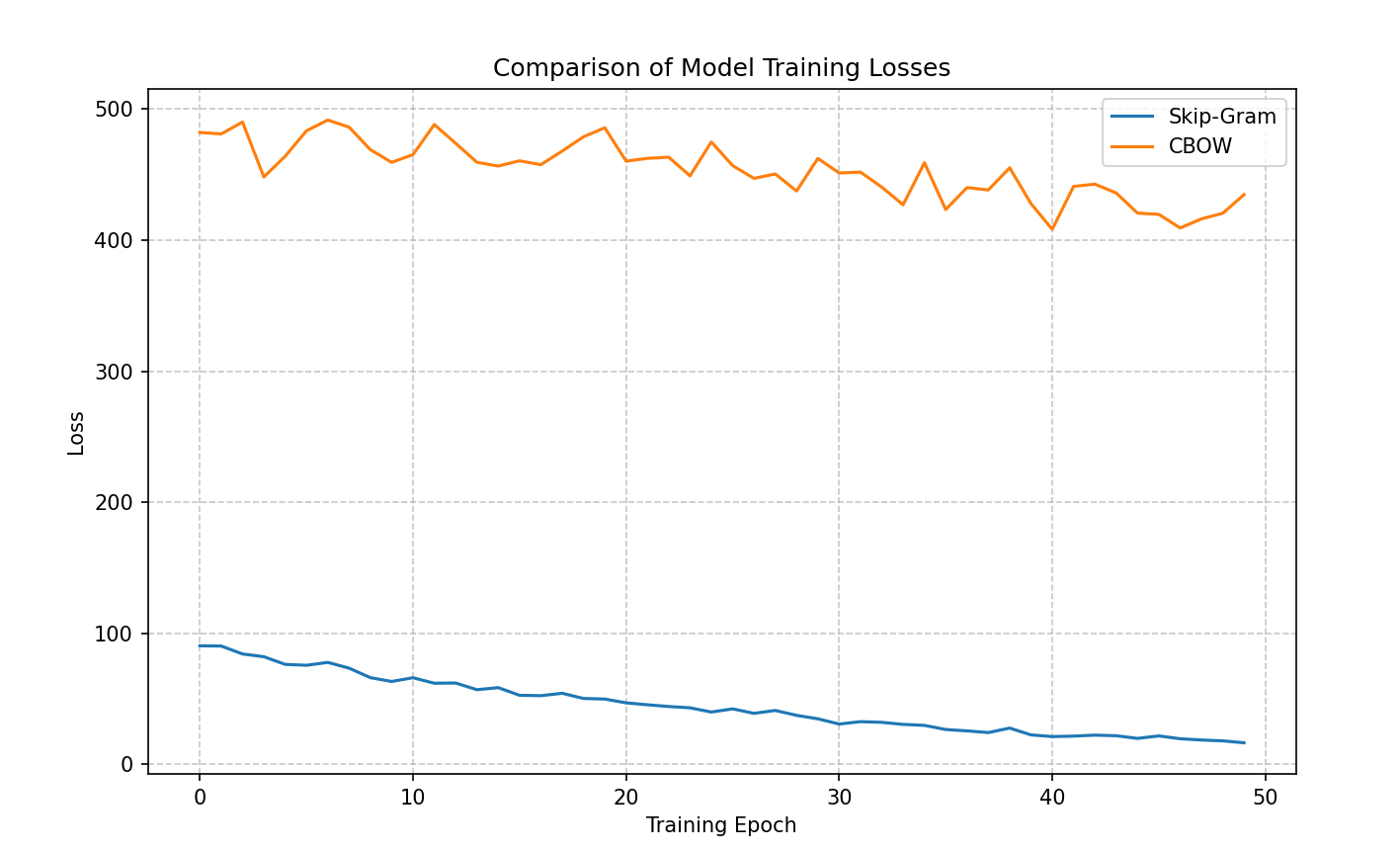
十、总结
本文介绍了Word2Vec的两种经典模型(Skip-Gram和CBOW)的Python实现,采用负采样优化计算效率。通过NLTK工具进行文本预处理,构建词汇表并计算词频分布。两种模型分别采用中心词预测上下文和上下文预测中心词的方式,使用负采样技术将多分类问题转化为二分类问题,降低计算复杂度。模型训练采用Adam优化器,并通过t-SNE降维可视化词向量。实验结果表明,Skip-Gram对低频词更友好,CBOW训练速度更快。该实现为自然语言处理任务提供了有效的词向量表示方法。

















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









