








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
T
(
o
)
=
N
(
1
)
T(o) = N(1)
T(o)=N(1)**
⛅指定节点的前插操作
typedef struct LNode{ //定义单链表节点类型
ElemType data; //每个节点存放一个数据元素
struct LNode \*next; //指针指向下一个节点
}LNode, \*LinkList
//后插操作:在p结点之前插入元素e
bool InsertNextNode(LNode \*p, ElemType e){
if(p == NULL){
return false;
}
LNode \*t = (LNode \*)malloc(sizeof(LNode));
if(s==NULL){ //内存分配失败
return false;
}
t->next = p->next;
p->next = t; //新结点t连接到p之后
t->data = p->data; //将p中元素复制到t中
p->data = e; //p中元素覆盖为e
}
**📌平均时间复杂度为
T
(
o
)
=
n
(
1
)
T(o) = n(1)
T(o)=n(1)**
👻删除操作
删除操作。删除表L中第
i
i
i个位置的元素,并用
e
e
e返回删除元素的值
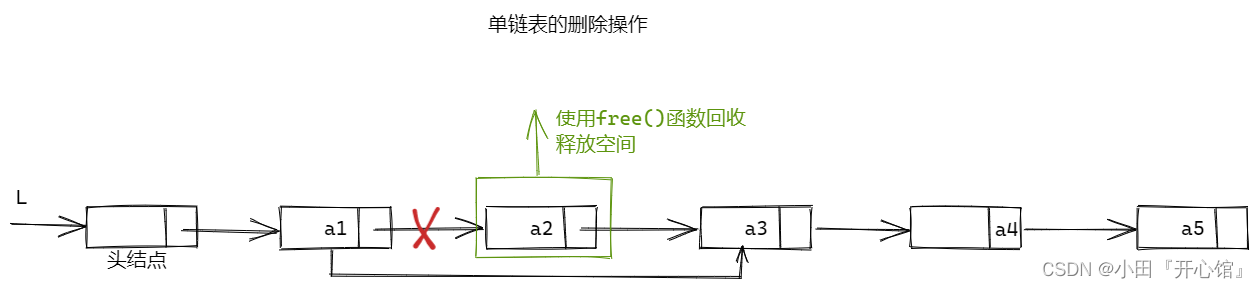
⛅按位序删除
带头结点情况:
typedef struct LNode{ //定义单链表节点类型
ElemType data; //每个节点存放一个数据元素
struct LNode \*next; //指针指向下一个节点
}LNode, \*LinkList
//带头结点的删除操作
bool ListDelete(LinkList &L, int i, ElemType &e){
if(i<1){
return false;
}
LNode \*p; //指针p指向当前扫描到的结点
int j=0; //当前p指向的是第几个结点
p = L; //L指向头结点,头结点是第0个结点(不存数据)
while(p != NULL && j<i-1){ //循环找到第i-1个结点
p = P->next;
j++;
}
if(p == NULL){ //i值不合法
return false;
}
if(p->next == NULL){ //第i-1个结点之后已无其他结点
return false;
}
LNode \*q = P->next; //令q指向被删除结点
e = q->data; //用e返回元素的值
p->next = q->next; //将\*q结点从链中断开
free(q); //释放结点的存储空间
return true; //删除成功
}
**📌在删除操作中,最坏和平均时间复杂度为
T
(
o
)
=
o
(
n
)
T(o) = o(n)
T(o)=o(n)**
最好时间复杂度:
T
(
n
)
=
O
(
1
)
T(n) = O(1)
T(n)=O(1)
⛅指定节点的删除
typedef struct LNode{ //定义单链表节点类型
ElemType data; //每个节点存放一个数据元素
struct LNode \*next; //指针指向下一个节点
}LNode, \*LinkList
//删除指定结点p
bool DeleteNode(LNode \*p){
if(p == NULL){
return false;
}
LNode \*q = p->next; //令q指向\*p的后继结点
p->data = p->next->data //和后继结点交换数据域
p->next = q->next; //将\*q结点从链中断开
free(q); //释放后继结点的存储空间
return true;
}
但是,使用这个算法有个问题,如果p是最后一个结点,那么当程序执行到p->data = p->next->data这一句时,会出现空指针的错误,所以只能从表头开始依次寻找p的前驱
**📌时间复杂度为
T
(
n
)
=
O
(
n
)
T(n) = O(n)
T(n)=O(n)**
👻查找操作(带头结点)
⛅按位查找操作
按位查找操作。获取表L中第i个位置的元素的值
typedef struct LNode{ //定义单链表节点类型
ElemType data; //每个节点存放一个数据元素
struct LNode \*next; //指针指向下一个节点
}LNode, \*LinkList
//按位查找,返回第i个元素(带头结点)
LNode \* GetElem(LinkList L, int i){
if(i<0){
return NULL;
}
LNode \*p; //指针p指向当前扫描的结点
int j = 0; //当前p指向的是第几个结点
p = L; //L指向头结点,头结点是第0个结点(不存数据)
while(p != NULL && j<i){ //循环找到第i个结点
p = p->next;
j++;
}
return p;
}
**📌平均时间复杂度为
T
(
n
)
=
O
(
n
)
T(n) = O(n)
T(n)=O(n)**
⛅按值查找操作
按值查找操作。根据给定的值在表L中查找与之相同的指定元素
typedef struct LNode{ //定义单链表节点类型
ElemType data; //每个节点存放一个数据元素
struct LNode \*next; //指针指向下一个节点
}LNode, \*LinkList
//按值查找操作(带头结点)
LNode \* LocateElem(LinkList L, ElemType e){
LNode \*p = L->next;
// 从第1个结点开始查找数据域为e的结点
while(p != NULL && p->data != e){
p = p->next;
}
return p; //找到后返回该结点指针,否则返回NULL
}
**📌平均时间复杂度为
T
(
n
)
=
O
(
n
)
T(n) = O(n)
T(n)=O(n)**
👻单链表的创建
⛅尾插法
每次都在最后一个元素之后插入新的元素
LinkList List\_Taillnsert(LinkList &L){ //正向建立单链表
int x; //设ElemType为整型
L = (LinkList)malloc(sizeof(LNode)); //建立头结点,初始化空表
LNode \*s, \*r = L; //r为表尾指针
scanf("%d", &x); //输入结点的值
while(x != 9999){ //输入9999表示结束
s = (LNode \*)malloc(sizeof(LNode));
s->data = x;
r->next = s; //在r结点之后插入元素x
r = s; //r指向新的表尾结点,永远保持r指向最后一个结点
scanf("%d", &x);
}
r->next = NULL; //尾结点指针置空
return L;
}
**📌平均时间复杂度为:
T
(
n
)
=
O
(
n
)
T(n) = O(n)
T(n)=O(n)**
⛅头插法
每次都在头结点之后插入新元素,头插法较为重要,当遇到链表的逆置操作时,可以使用头插法实现
LinkList List\_Taillnsert(LinkList &L){ //逆向建立单链表
LNode \*s;
int x;
L = (LinkList)malloc(sizeof(LNode)); //创建头结点
L->next = NULL; //初始为空链表
scanf("%d", &x); //输入结点的值
while(x != 9999){ //输入9999标志结束
s = (LNode\*)malloc(sizeof(LNode)); //创建新结点
s->data = x;
s->next = L->next;
L->next = s; //将性结点插入表中,L为头指针
scanf("%d", &x);
}
return L;
}
**📌平均时间复杂度为:
T
(
n
)
=
O
(
n
)
T(n) = O(n)
T(n)=O(n)**
🚢静态链表
这种存储结构需要预先分配一个比较大的空间,但在做线性表的插入和删除时不需要移动元素,仅需要修改指针,所以仍然具有链式存储结构的主要优点,为了和指针型描述的线性链表相区别,所以称这种用数组描述的链表为静态链表
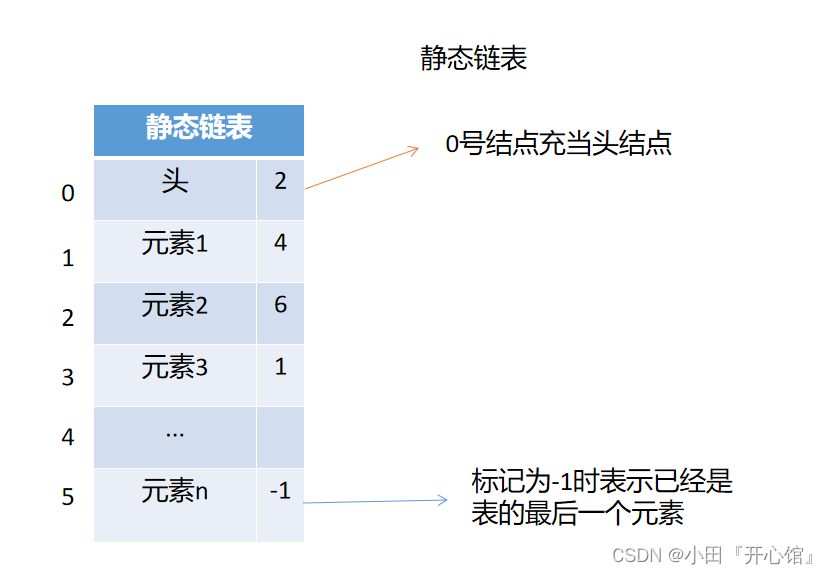
静态链表的优点和缺点
- 📌优点:增、删操作不需要移动大量的数据
- 📌缺点:不能随机存取,只能从头结点开始依次往后查找,容量固定不可变,静态分配
🚢循环链表
循环链表(circular linked list)是另外一种形式的链式存储结构,它的特点是从表中最后一个结点的指针域指向头结点,整个链表形成一个环,由此,从表中任一结点触发均可找到表中的其他结点
循环链表的操作和线性表基本一致,差别仅在于算法中的循环条件不是P—>next是否为空,而是是否等于头指针
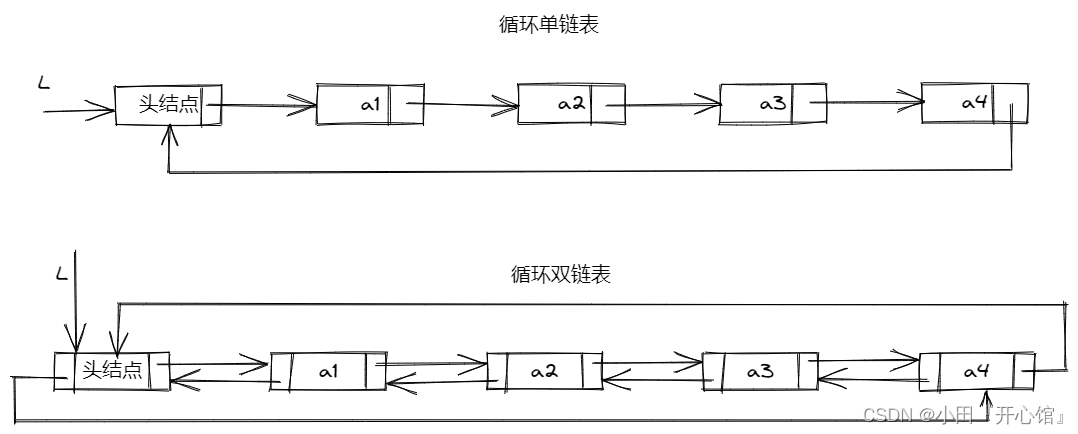
📌**在循环单链表中,从头部找到尾部元素,时间复杂度为
T
(
n
)
=
O
(
n
)
T(n) = O(n)
T(n)=O(n)**
📌**从尾部找到头部元素,时间复杂度为
T
(
n
)
=
O
(
1
)
T(n) = O(1)
T(n)=O(1)**
🚢双向链表
上述的链式存储结构的结点中只有一个指示直接后继的指针域,由此,从某结点出发只能顺指针往后查询其他结点,若要寻查结点的直接前驱,则需要从头指针出发。换句话说,在单链表中,NextElem的执行时间为
O
(
1
)
O(1)
O(1),而PriorElem的执行时间为
O
(
n
)
O(n)
O(n),为克服单链表这种单向性的缺点,可利用双向链表。

顾名思义,在双向链表的结点中有两个指针域,其一指向直接后继,其二指向直接前驱。和单链表的循环链表类似,双向链表也有循环链表。
双向链表不可随机存取,按位查找、按值查找操作只能用遍历的方式实现
**📌时间复杂度为:
T
(
n
)
=
O
(
n
)
T(n) = O(n )
T(n)=O(n)**
👻双向链表的初始化(带头结点)
typedef struct DNode{
ElemType data;
struct DNode \*prior, \*next;
}DNode, \*DLinklist;
bool InitDLinkList(DLinklist &L){
L = (DNode \*)malloc(sizeof(DNode)); //分配一个头结点
if(L == NULL){ //内存不足,分配失败
return false;
}
L->prior = NULL; //头结点的prior永远指向NULL
L->next = NULL; //头结点之后暂时还没有结点
return true;
}
void testDLinkList(){
//初始化双链表
InitDLinkList(L);
......
}
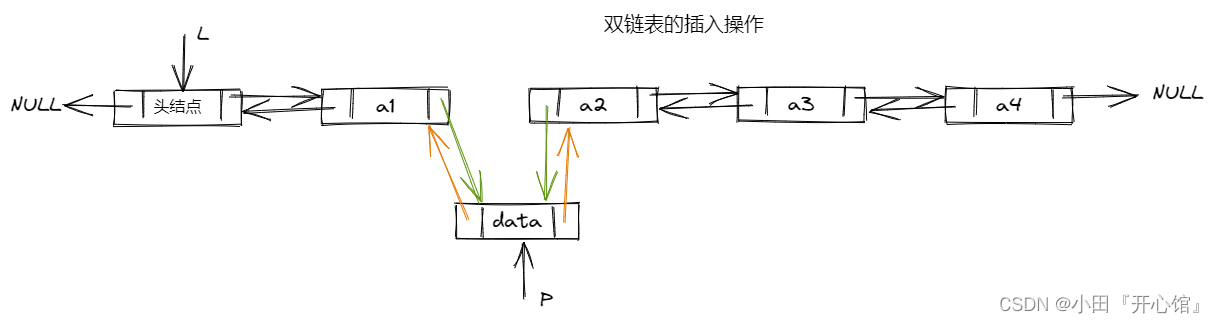
👻双向链表的插入操作
typedef struct DNode{
ElemType data;
struct DNode \*prior, \*next;
}DNode, \*DLinklist;
// 在p结点之后插入s结点
bool InsertNextDNode(DNode \*p, DNode \*s){
if(p == NULL || s == NULL){ //非法参数
return false;
}
s->next = p->next;
if(p->next != NULL){ //如果p结点有后继结点
p->next->prior = s;
}
s->prior = p;
p->next = s;
return true;
}
👻双向链表的删除操作
typedef struct DNode{
ElemType data;
struct DNode \*prior, \*next;
}DNode, \*DLinklist;
// 删除p结点的后继结点
bool DeletenextDNode(DNode \*p){
if(p == NULL || s == NULL){ //非法参数
return false;
}
DNode \*p = p->next; //找到p的后继结点q
if(q == NULL){
return false; //p没有后继
}
if(q->next != NULL){ //q结点不是最后一个结点
q->next->prior = p;
}
free(q); //释放结点空间
return true;
}

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
NULL){ //如果p结点有后继结点
p->next->prior = s;
}
s->prior = p;
p->next = s;
return true;
}
##### 👻双向链表的删除操作
typedef struct DNode{
ElemType data;
struct DNode *prior, *next;
}DNode, *DLinklist;
// 删除p结点的后继结点
bool DeletenextDNode(DNode *p){
if(p == NULL || s == NULL){ //非法参数
return false;
}
DNode *p = p->next; //找到p的后继结点q
if(q == NULL){
return false; //p没有后继
}
if(q->next != NULL){ //q结点不是最后一个结点
q->next->prior = p;
}
free(q); //释放结点空间
return true;
}
[外链图片转存中...(img-bK61vtmM-1715622995882)]
[外链图片转存中...(img-pAOep6hS-1715622995882)]
[外链图片转存中...(img-lhL0uQOT-1715622995883)]
**既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
**由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**
**[需要这份系统化资料的朋友,可以戳这里获取](https://bbs.csdn.net/topics/618545628)**















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









