







ρ
∣
Q
∣
)
O(\rho\sqrt{|Q|})
O(ρ∣Q∣
)(pure-DP为
O
(
ρ
∣
Q
∣
)
O(\rho|Q|)
O(ρ∣Q∣)),当
∣
Q
∣
|Q|
∣Q∣很大的时候(比如
n
2
n^2
n2),这个误差没什么意义,那么我们可以得到大量查询下仍旧有意义的误差吗?
这是可以的,使用boosting技术可以实现一个差分隐私算法,对于每个回答误差大致为
O
(
ρ
n
log
3
/
2
∣
Q
∣
)
O(\rho\sqrt{n}\log^{3/2}|Q|)
O(ρn
log3/2∣Q∣)!并且针对线性查询,该算法运行时间可以变为多项式时间。
算法概述
简单叙述一下这个算法,它有T轮迭代,在每一轮当中,
- 我们根据分布
D
t
\mathcal{D}_t
Dt选出来k个query,然后送到bsg(base synopsis generator)里面,bsg返回对于所有query的回答。
2. 我们对于bsg给出的回答做个评判,然后分别打个分,越准确的回答,对应系数
a
t
,
q
a_{t,q}
at,q约大。
3. 归一化打分,把它作为一个分布更新。
T轮之后,我们得到了
T
∣
Q
∣
T|Q|
T∣Q∣个结果,对于每个query选一个好的回答,返回。

整个算法流程大致就是这样,然后有几个比较有趣的点。
- bsg是什么?bsg有四个参数(
k
k
k,
λ
\lambda
λ,
η
\eta
η,
β
\beta
β),分别构建所需要的查询数量,回答误差,平衡参数,失败概率。代表简单地说,他是一个黑盒,你给他k个query,它就能给你一系列回答,对于这k个query有着比较好的近似。然后有一个事实,如果k个query是从一个分布里选的,那对k个query的良好近似,可以得到对于
∣
Q
∣
|Q|
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数网络安全工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
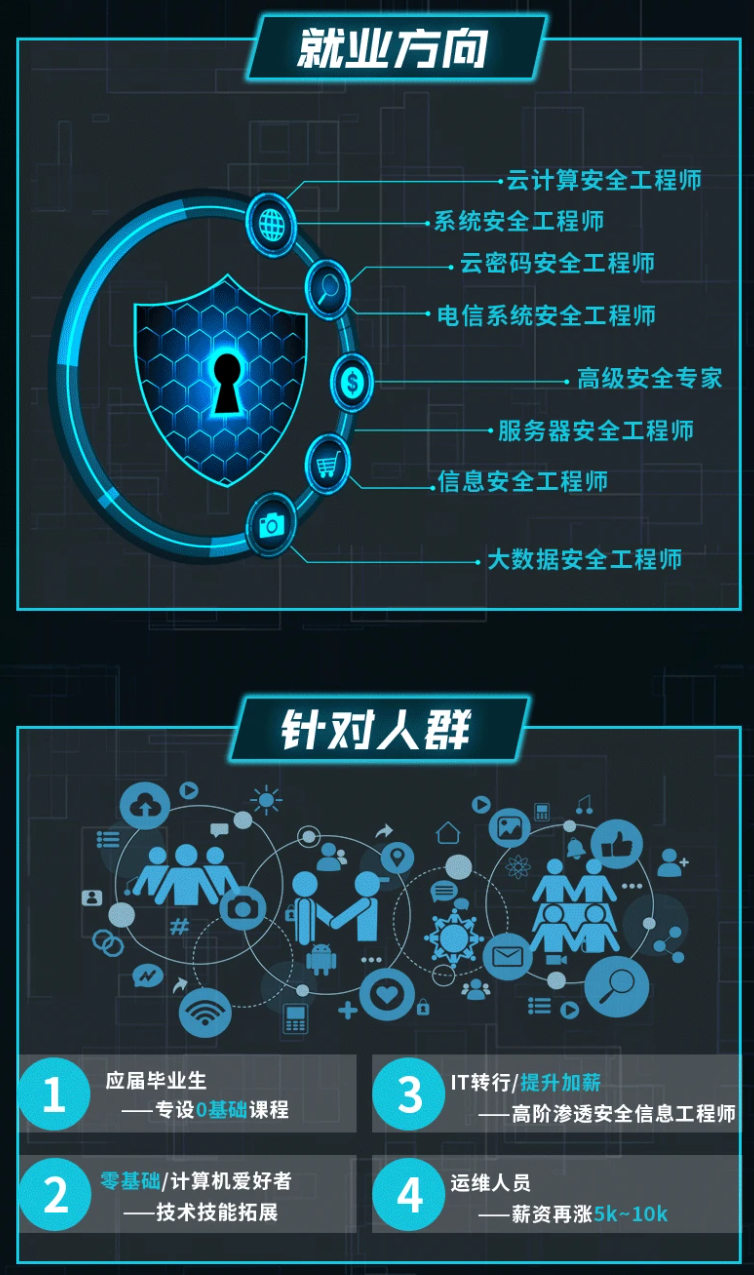
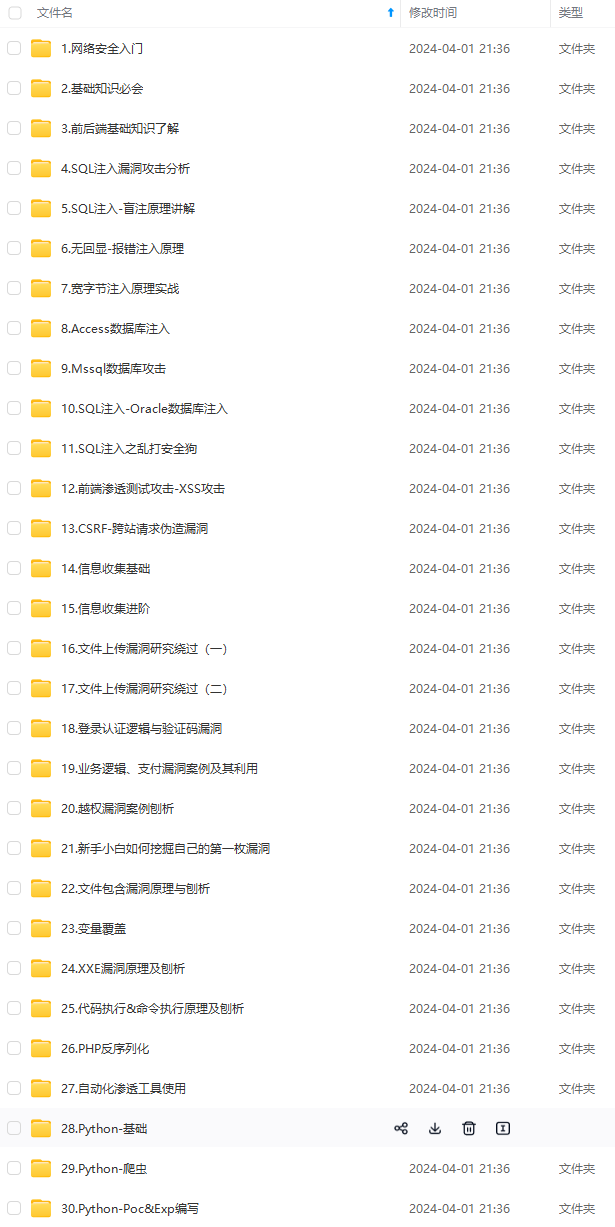
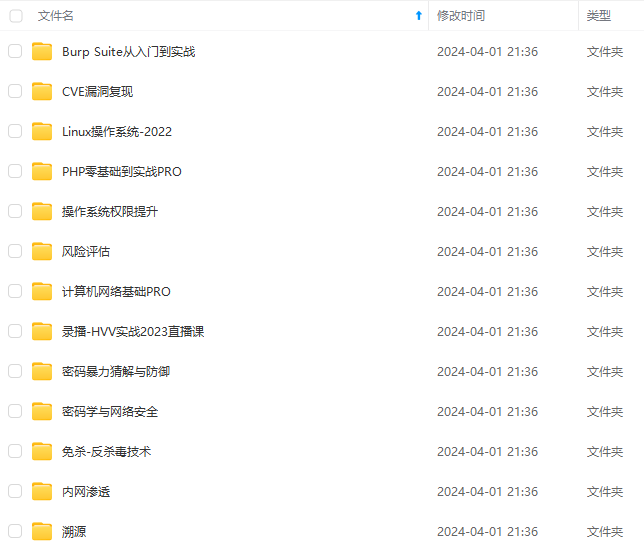
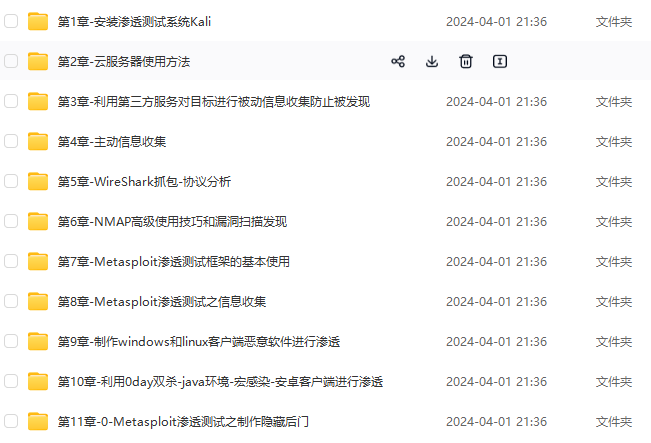
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注网络安全获取)

写在最后
在结束之际,我想重申的是,学习并非如攀登险峻高峰,而是如滴水穿石般的持久累积。尤其当我们步入工作岗位之后,持之以恒的学习变得愈发不易,如同在茫茫大海中独自划舟,稍有松懈便可能被巨浪吞噬。然而,对于我们程序员而言,学习是生存之本,是我们在激烈市场竞争中立于不败之地的关键。一旦停止学习,我们便如同逆水行舟,不进则退,终将被时代的洪流所淘汰。因此,不断汲取新知识,不仅是对自己的提升,更是对自己的一份珍贵投资。让我们不断磨砺自己,与时代共同进步,书写属于我们的辉煌篇章。
需要完整版PDF学习资源私我
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

划舟,稍有松懈便可能被巨浪吞噬。然而,对于我们程序员而言,学习是生存之本,是我们在激烈市场竞争中立于不败之地的关键。一旦停止学习,我们便如同逆水行舟,不进则退,终将被时代的洪流所淘汰。因此,不断汲取新知识,不仅是对自己的提升,更是对自己的一份珍贵投资。让我们不断磨砺自己,与时代共同进步,书写属于我们的辉煌篇章。**
需要完整版PDF学习资源私我
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-XDiXF4oq-1712647191501)]















 6206
6206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









