








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
- [Hadoop简介](#Hadoop_10)
+ [一、配置环境](#_13)
+ - [购买云耀云服务器L实例](#L_15)
- [查看云耀云服务器L实例状态](#L_25)
- [重置密码](#_30)
- [查看弹性公网IP地址](#IP_36)
+ [FinalShell连接服务器](#FinalShell_42)
+ [二、搭建Hadoop单机版本](#Hadoop_48)
+ - [详细安装步骤如下:](#_50)
- * [我们先开始配置java环境](#java_51)
* [hadoop2.x](#hadoop2x_93)
* [接下来需要利用vim来操作core-site 和 hdfs-site](#vimcoresite__hdfssite_139)
* [踩坑:](#_216)
+ [三、验证成果](#_240)
+ [总结](#_252)
前言
这是Maynor创作的华为云云耀云服务器L实例测评的第二篇,上篇传送门:
华为云云耀云服务器L实例评测|单节点环境下部署ClickHouse21.1.9.41数据库
云耀云服务器L实例简介
云耀云服务器L实例是新一代的轻量应用云服务器,专门为中小企业和开发者打造,提供开箱即用的便利性。云耀云服务器L实例提供丰富且经过严格挑选的应用镜像,可以一键部署应用,极大地简化了客户在云端构建电商网站、Web应用、小程序、学习环境以及各类开发测试等任务的过程。
Hadoop简介
Hadoop是一个开源的分布式计算框架,能够处理大规模数据的存储和处理。它基于Google的MapReduce算法和Google File System(GFS)的思想,可以在廉价的硬件上进行高效的分布式计算。Hadoop有两个核心组件,一个是分布式文件系统Hadoop Distributed File System(HDFS),另一个是分布式计算框架MapReduce。HDFS将大规模数据分散存储在多个节点上,而MapReduce则将计算分散到多个节点上进行并行计算,最终将结果汇总输出。Hadoop的优点是具有高可靠性、可扩展性和高效性,适合处理大规模数据。Hadoop被广泛应用于数据挖掘、机器学习、人工智能、搜索引擎等领域。
一、配置环境
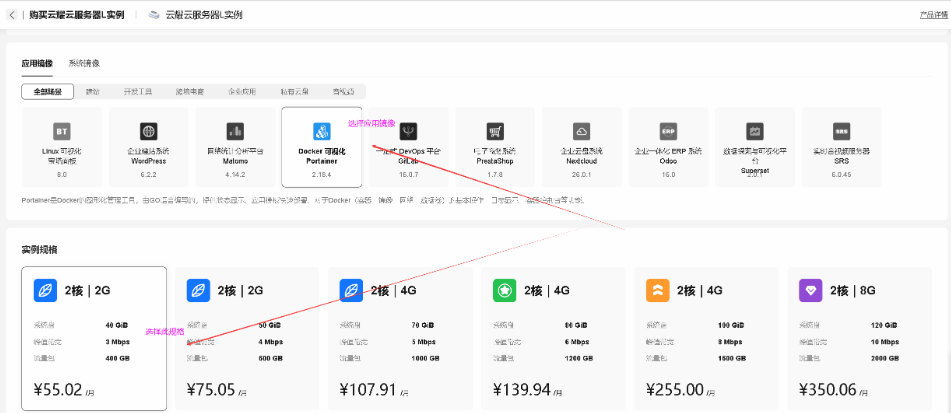
购买云耀云服务器L实例
在云耀云服务器L实例详情页,点击购买。

- 检查配置,确认购买。
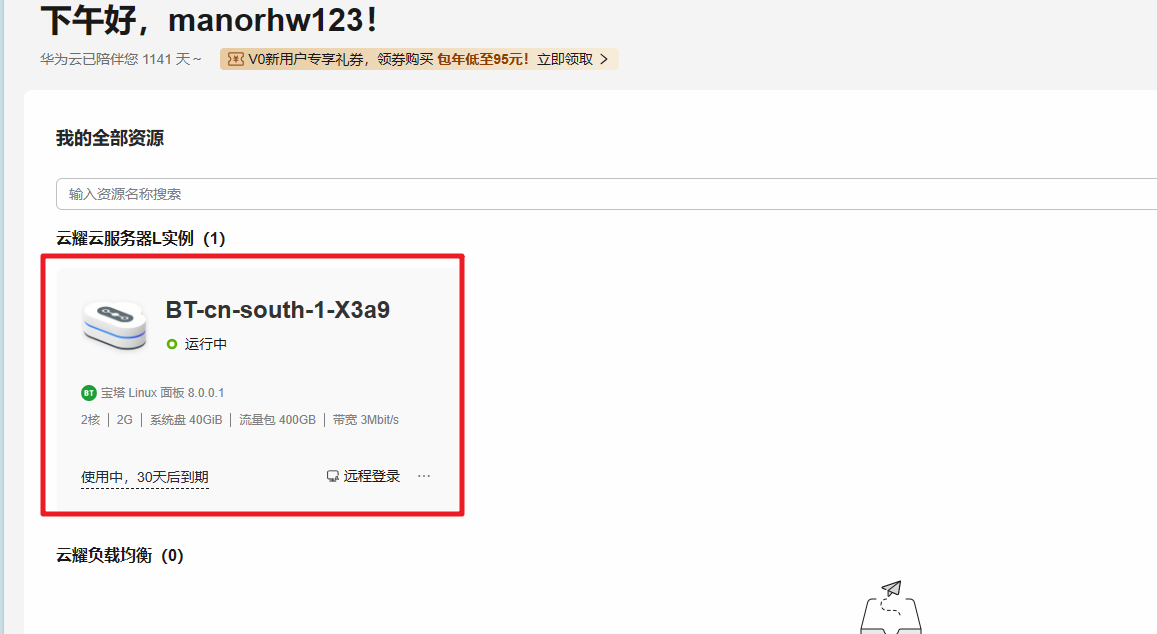
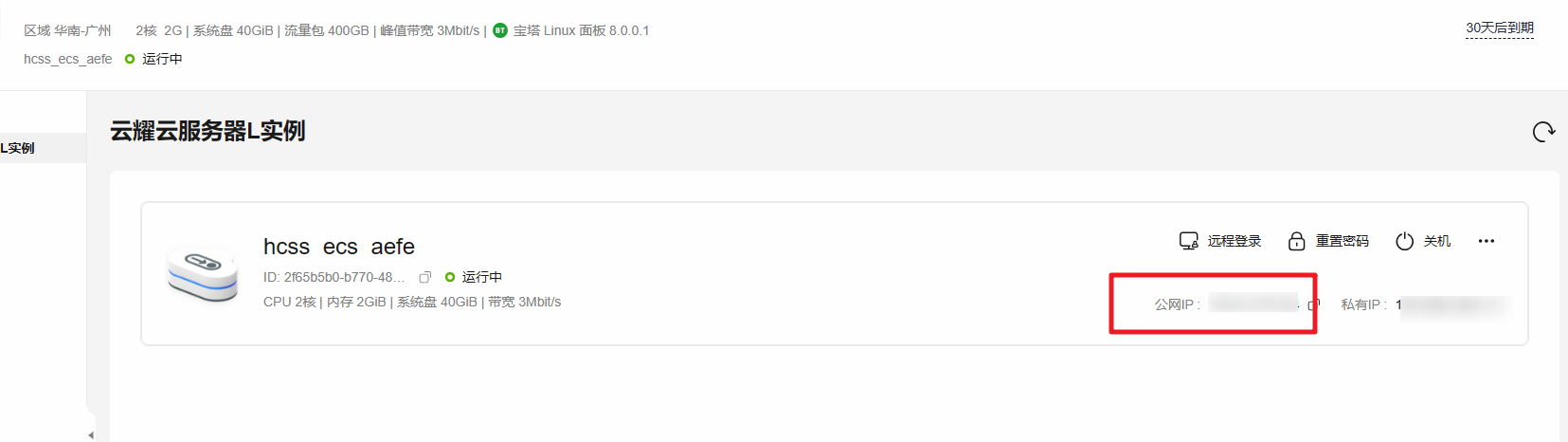
查看云耀云服务器L实例状态
查看购买的云耀云服务器L实例状态,处在正常运行中。
重置密码
重置密码,点击重置密码选项,需要进行身份验证,选择手机验证后,即可重置密码成功。
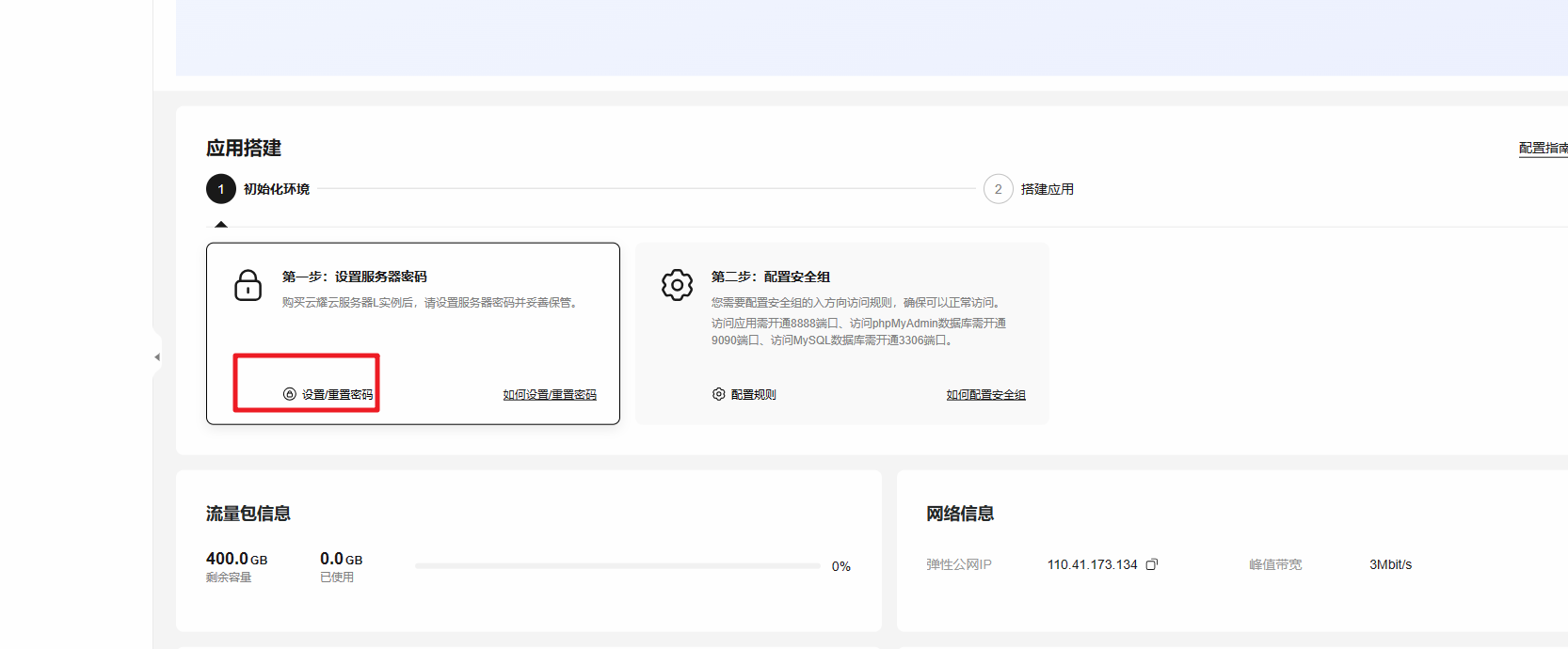
查看弹性公网IP地址
- 复制弹性公网IP地址,远程连接服务器时使用。
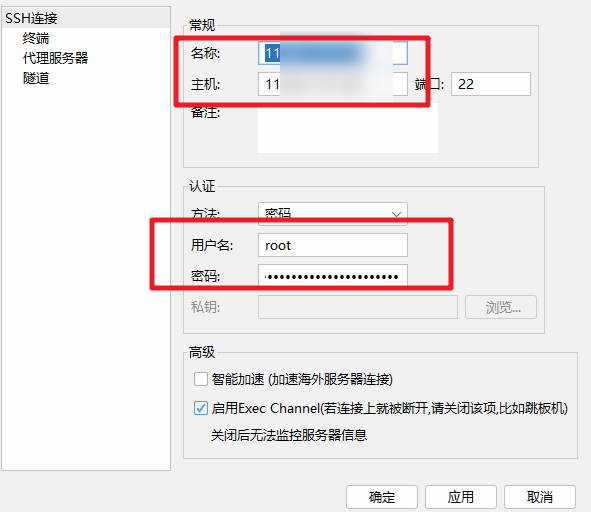
FinalShell连接服务器
在FinalShell工具中,填写服务器弹性公网IP地址、账号密码信息,ssh连接远程服务器。
二、搭建Hadoop单机版本
详细安装步骤如下:
我们先开始配置java环境
首先下载java的jdk
wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz

然后解压
tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz

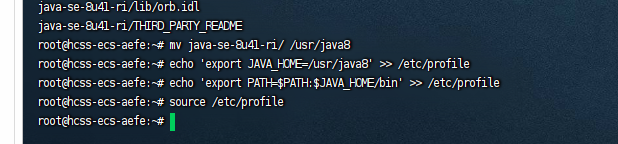
移动位置并且配置java路径
mv java-se-8u41-ri/ /usr/java8
echo 'export JAVA_HOME=/usr/java8' >> /etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile
source /etc/profile
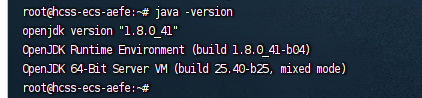
检查是否安装成功
java -version
这是理想情况,若安装成功会出现如下结果
hadoop2.x
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
tar -zxvf hadoop-2.10.1.tar.gz -C /opt/
mv /opt/hadoop-2.10.1 /opt/hadoop
配置地址
echo 'export HADOOP_HOME=/opt/hadoop/' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/bin' >> /etc/profile
echo 'export PATH=$PATH:$HADOOP_HOME/sbin' >> /etc/profile
source /etc/profile

配置yarn和hadoop
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh
echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh
查看Hadoop 安装情况
hadoop version
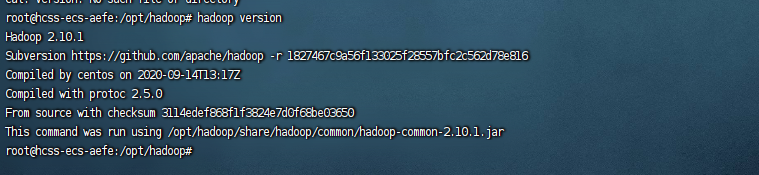
若出现上图情况,则说明安装成功
接下来需要利用vim来操作core-site 和 hdfs-site
vim /opt/hadoop/etc/hadoop/core-site.xml

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
715135089424)]
[外链图片转存中…(img-xlUatM1a-1715135089424)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1670
1670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









