







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
一、模式
redis集群有三种模式,分别是主从同步/复制、哨兵模式、Cluster。
在Redis中,实现高可用的技术主要包括持久化、主从复制、哨兵和集群。1.存储池
(1)主从复制
主从复制是高可用Redis的基础,哨兵和集群都是在主从复制基础上实现高可用的。主从复制主要实现了数据的多机备份,以及对于读操作的负载均衡和简单的故障恢复。
缺陷:故障恢复无法自动化:写操作无法负载均衡:存储能力受到单机的限制。(2)哨兵
在主从复制的基础上,哨兵实现了自动化的故障恢复。
缺陷:写操作无法负载均衡:存储能力受到单机的限制。(3)集群(cluster实现了分布式)
通过集群,Redis解决了写操作无法负载均衡,以及存储能力受到单机限制的问题,实现了较为完善的高可用方案。
缺点:“使用场景并不那么普遍” ( 容器化之后)。2.Redis群集
1)redis是一个开源的kevvalue存储系统,受到了广大互联网公司的青睐。redis3. 0版本之前只支持单例模式,在3.0版本及以后才支持集群。redis 集群采用P2P模式,是完全去中心化的,不存在中心节点或者代理节点。
2)为了实现集群的高可用,即判新节点是否健康(能否正常使用),redis-cluster有一个投票容错机制。如果集群中超过半数的节点投票认为某个节点挂了,那么这个节点就挂了(fail)。这是判断节点是否挂了的方法。
判新集群是否正常:如果 集群中任意一个节点挂了,而且该节点没有从节点(备份节点),那么这个集群就挂了。这是判断集群是否挂了的方法。任意一个节点挂了(没有从节点)这个集群就挂了:
因为集群内置了16384个slot (哈希槽),并且把所有的物理节点映射到了这16384[0-16383]个slot上,或者说把这些slot均等的分配给了各个节点。
当需要在Redis集群存放一个数据(key-value)时,redis 会先对这个key进行crc16算法,然后得到一个结果再把这个结果对16384进行求余,这个余数会对应[0-16383]其中一个槽,进而决定key-value存储到哪个节点中。所以一旦某个节点挂了,该节点对应的slot就无法使用,那么就会导致集群无法正常工作。(三个节点) :
节点A覆盖0-5460;
节点B覆盖5461-10922;
节点C覆盖10923-16383
即:每个节点有5460个哈希槽新增一个节点:
节占A覆盖1365-5460
节占B覆盖6827-10922
节点c覆盖12288-16383
节点D覆盖0-1364,5461-6826,10923-12287
即:每个节点有4095个哈希槽
所以每个Redis集群理论上最多可以有16384个节点。
二、Redis三种模式介绍
1.主从模式
通过持久化功能,redis保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,因为持久化会把内存中的数据保存到硬盘上,重启会从硬盘上加载数据,但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务,为此,redis提供了复(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
在复制的概念中,数据库分为两类,一类是主数据库(master),另一-类是从数据(slave)。主数据可以进行读写操作,当写操做导致数据变化时自动将数据同步给数据库,而从数据库一般是只读的,并接收主数据同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。2.主从复制流程
1)若启动一个Slave机器进程,则它会向Master机器发送一个"sync_ command"命令,请求同步连接。
2)无论是第一次连接还是重新连接,Master机器都会启动一个后台进程,将数据快照(RDB)保存到数据文件中(执行rdb操作),同时Master还会记录修改数据的所有命令并缓存在数据文件中。
3)后台进程完成缓存操作之后,Master机 器就会向Slave机器发送数据文件,Slave端 机器将数据文件保存到硬盘上,然后将其加载到内存中,接着Master机器就会将修改数据的所有操作一并发送给Slave端机器。若Slave出现故障导致宕机,则恢复正常后会自动重新连接。
4)Master机器收到slave端机器的连接后,将其完整的数据文件发送给Slave端机几器,如果Mater同时收到多个slave发来的同步请求则Master会在后台启动一个进程以保存数据文件,然后将其发送给所有的Slave端机器,确保所有的Slave端机器都正常。
3.哨兵模式(Sentinel)
(1)哨兵模式集群架构
哨兵是Redis集群架构中非常重要的一个组件,哨兵的出现主要是解决了主从复制出现故障时需要人为干预的问题。
(2)哨兵模式主要功能
1)集群监控:负责监控Redismaster和slave进程是否正常工作。
2)消息通知:如果某个Redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
3)故障转移:如果masternode挂掉了,会自动转移到slave node上。
4)配置中心:如果故障转移发生了,通知client客户端新的master地址。使用一个或者多个哨兵(Sentinel)实例组成的系统,对redis节点进行监控在主节点出现故障的情况下,能将从节点中的一个升级为主节点,进行故障转义,保证系统的可用性。
(3)哨兵们监控整个系统节点的过程
1)首先主节点的信息是配置在哨兵(Sentinel)的配置文件中。
2)哨兵节点会和配置的主节点建立起两条连接命令连接和订阅连接。
Redis发 布订阅(pub/ sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub) 接收消息。3)哨兵会通过命令连接每10s发送一次INFO命令,通过INFO命令,主节点会返回自己的run_ id和自己的从节点信息。
4)哨兵会对这些从节点也建立两条连接命令连接和订阅连接。
5)哨兵通过命令连接向从节点发送INFO命令,获取到他的一些信息
①run id(redis服务器id)
②role (职能)
③从服务器的复制偏移量offset
④其他6)通过命令连接向服务器的sentinel:he1lo频道发送一条消息, 内容包括自己的ip端口、run
id、配置(后续投票的时候会用到)等。7)通过订阅连接对服务器的sentinel:hello频道做了监听,所以所有的向该频道发送的哨兵的消息都能被接受到。
8)解析监听到的消息,进行分析提取,就可以知道还有那些别的哨兵服务节点也在监听这些主从节点了,更新结构体将这些哨兵节点记录下来。
9)向观察到的其他的哨兵节点建立命令连接→没有订阅连接。
(4)哨兵模式下的故障迁移
1)主观下线
哨兵(Sentinel)节点会每秒一次的频率向建立了命令连接的实例发送PING命令,如果在down-after–milliseconds毫秒内没有做出有效响应包括(PONG/ LOADINC/MASTERDOWN)以外的响应,哨兵就会将该实例在本结构体中的状态标记为SRI_S_DOWN主观下线。2)客观下线
当一个哨兵节点发现主节点处于主观下线状态是,会向其他的哨兵节点发出询问,该节点是不是已经主观下线了。如果超过配置参数quorum个节点认为是主观下线时,该哨兵节点就会将自己维护的结构体中该主节点标记为SRIO DOWN客观下线询问命令SENTINEL is-master-down-by- addr。3)master选举
在认为主节点客观下线的情况下,哨兵节点节点间会发起一 次选举,命令为: SENTINEL is-master-down-by-addr。
只是runid这次会将自己的runid带进去, 希望接受者将自己设置为主节点。如果超过半数以上的节点返回将该节点标记为leacer的情况下,会有该leader对故障进行迁移。4)故障转移
在从节点中挑选出新的主节点
①通讯正常
②优先级排序
③优先级相同时选择offset最大的
将该节点设置成新的主节点SLAVEOFnoone,并确保在后续的ING0命令时该节点返回状态为master,将其他的从节点设置成从新的主节点复制,SLAVE0F 命令将旧的主节点变成新的主节点的从节点。5)优缺点
①优点:高可用,哨兵模式是基于主从模式的,所有主从模式的优点,哨兵模式都具有有;主从可以自动切换,系统更健壮,可用性更高。
②缺点:redis比较难支持在线扩容,在群集容量达到上限时在线扩容会变得很复杂。(5) Cluster群集
redis的哨兵模式基本已经可以实现高可用、读写分离,但是在这种模式每台redis服务器都存储相同的数据,很浪费内存资源,所以在redis3.0上加入了Cluster群集模式,实现了redis的分布式存储,也就是说每台redis节点存储着不同的内容根据官方推荐,集群部署至少要3台以上的master节点,最好使用3主3从六个节点的模式。
Cluster 群集由多个redis服务器组成的分布式网络服 务群集,群集之中有多个master主节点,每一个主节点都可读可写,节点之间会相互通信,两两相连,redis群集无中心节点。
在redis-cluster群集中,可以给每个一个主节点添加从节点,主节点和从节点直接尊循主从模型的特性,当用户需要处理更多读请求的时候, 添加从节点可以扩展系统的读性能。
redis-cluster的故障转移:redis群集的主机节点内置了类似redissentinel的节点故障检测和自动故障转移功能,当群集中的某个主节点下线时,群集中的其他在线主节点会注意到这一点,并且对已经下线的主节点进行故障转移。
集群进行故障转移的方法和redissentinel进行故障转移的方法基本一样,不同的是,在集群里面,故障转移是由集群中其他在线的主节 点负责进行的,所以群集不必另外使用redis sentinel。
三、Redis主从复制
节点名 IP地址
master 192. 168.22.186
slave1 192.168.22.196
slave2 192. 168.22.2061.安装Redis
三台服务器都需要安装
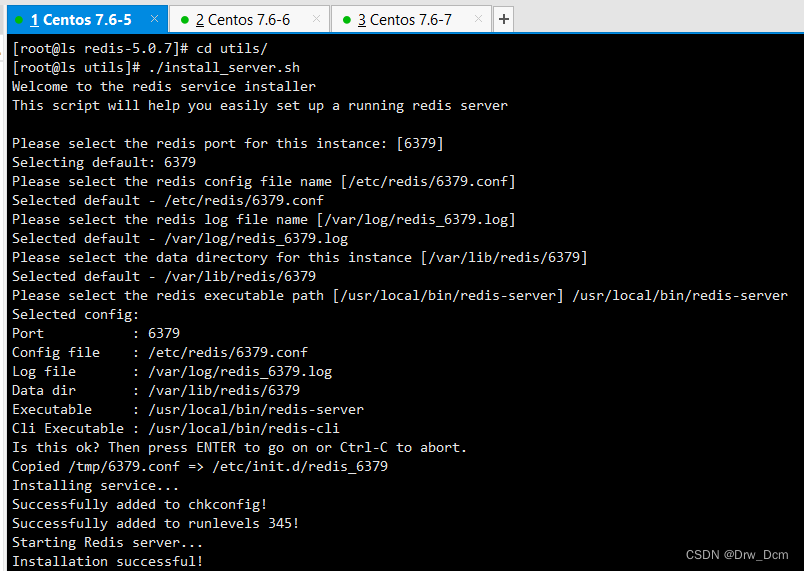
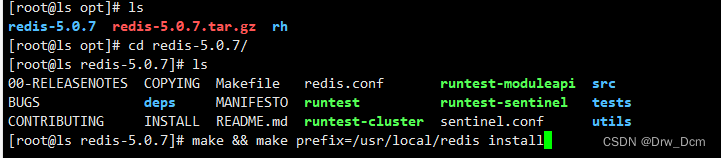
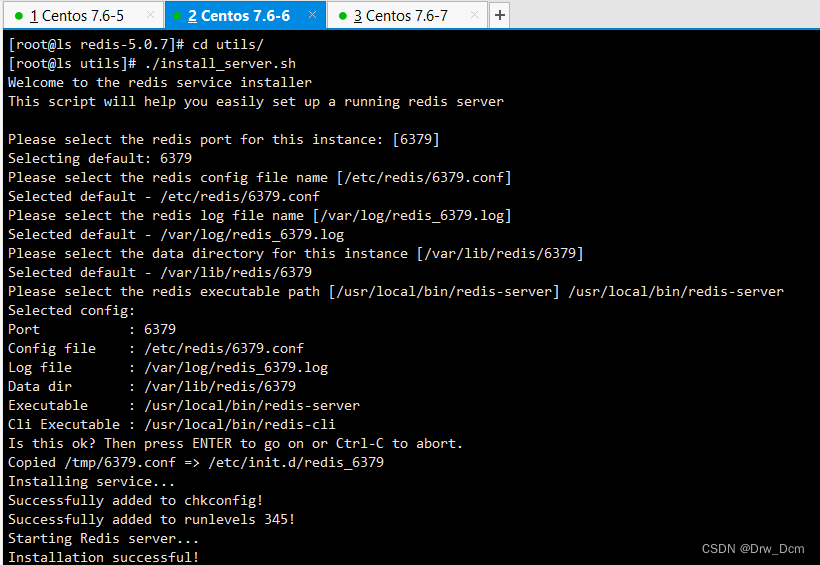
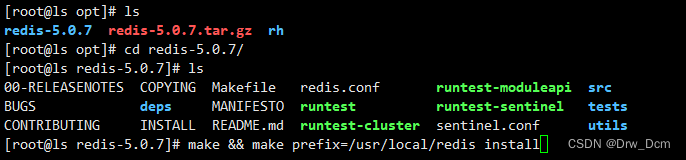
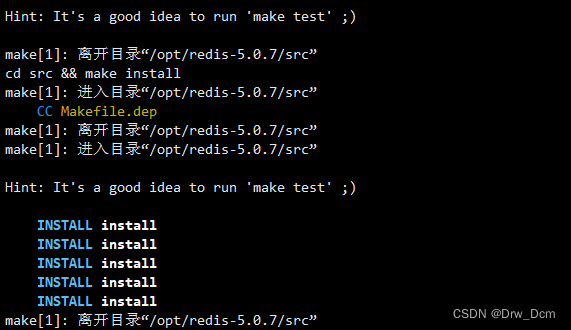
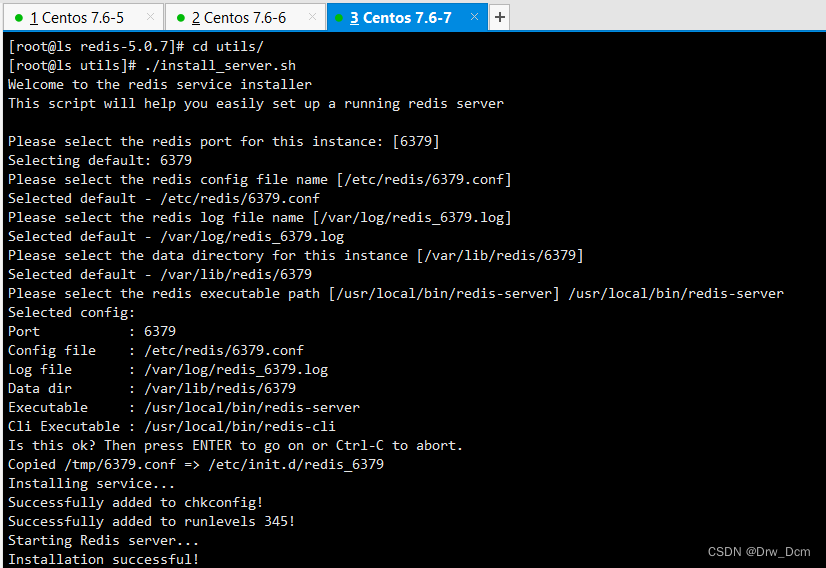
按需求关闭安全策略systemctl stop firewalld systemctl disable firewalld setenforce 0yum -y install gcc gcc-c++ make cd /opt wget -P /opt http://download,redis,io/releases/redis-5.0.7.tar.gz tar -zxvf redis-5.0.7.tar.gz cd redis-5.0.7 make && make PREFIX-/usr/local/redis install Redis源码包中 直接提供了makefile文件 直接执行make与make install命 令进行安装 cd /opt/redis-5.0.7/utils/ ./ install_server.sh 回车,直到出现以下选项,手动修改为“/usr/local/ redis/bin/ redis-server” ln -s /usr/local/redis/bin/* /usr/local/bin/ 检查服务状态 ss -natp | grep "redis"
2.修改Redis配置文件
(1)Master节点
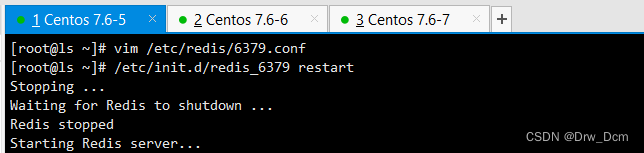
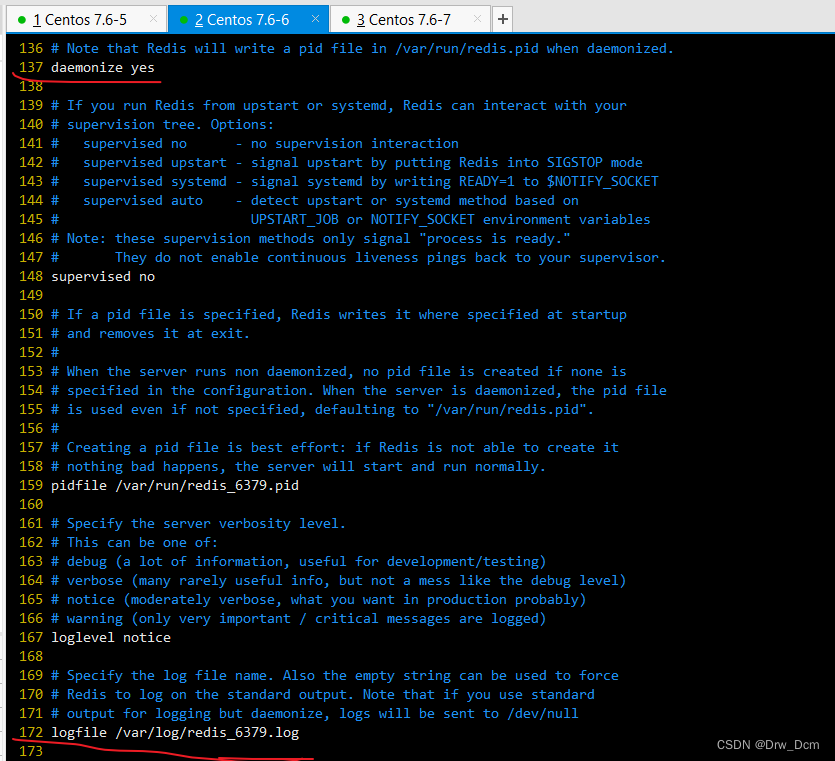
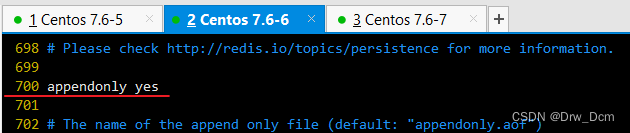
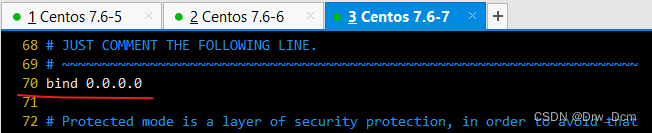
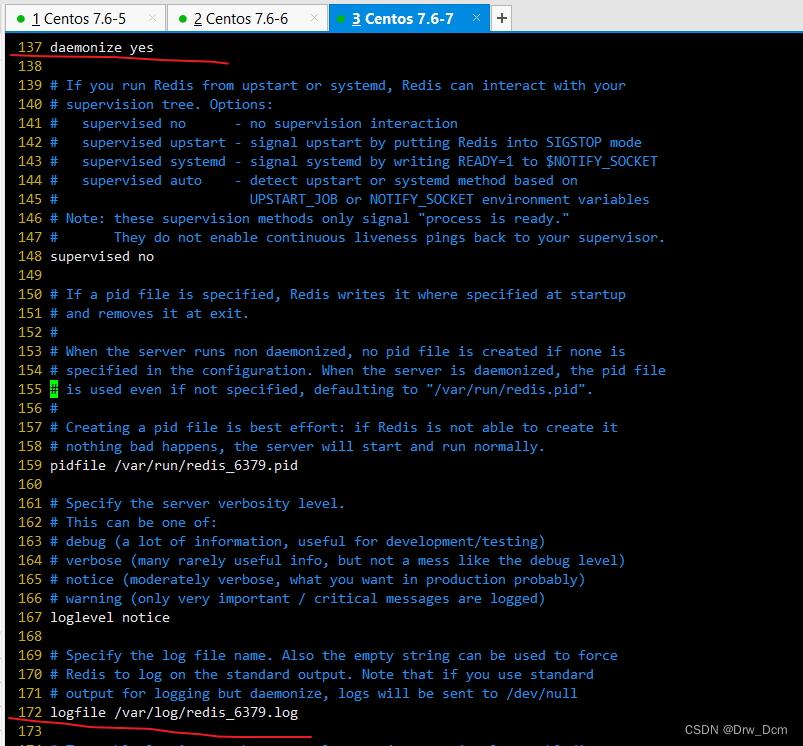
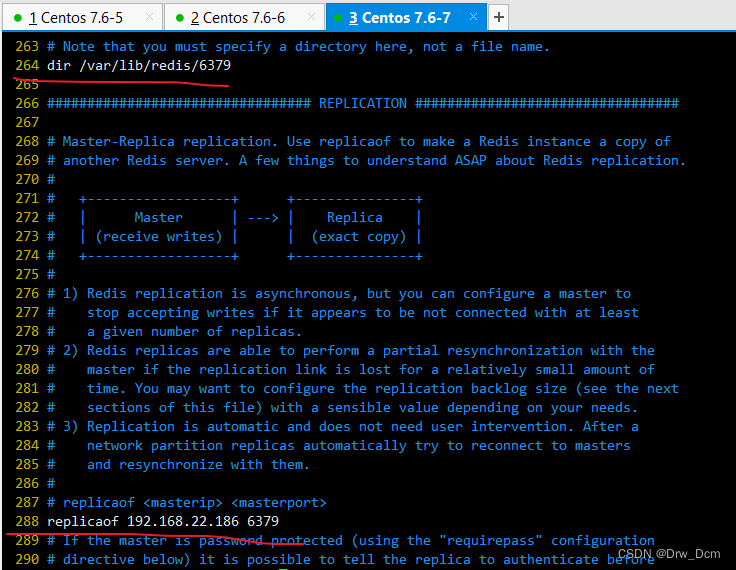
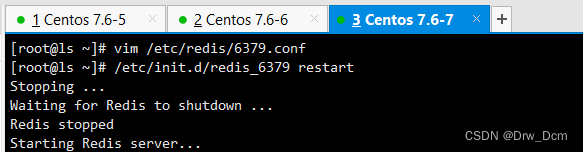
vim /etc/redis/6379.confbind 0.0.0.0 70行,修改监听地址为0.0.0.0 daemonize yes 137行, 开启守护进程 logfile /var/1og/redis_6379.1og 172行,指定日志文件目录 dir /var/lib/redis/6379 264行,指定工作目录 appendonly yes 700行,开启AOF持久化功能 /etc/init.d/redis_6379 restart 重启服务使配置生效
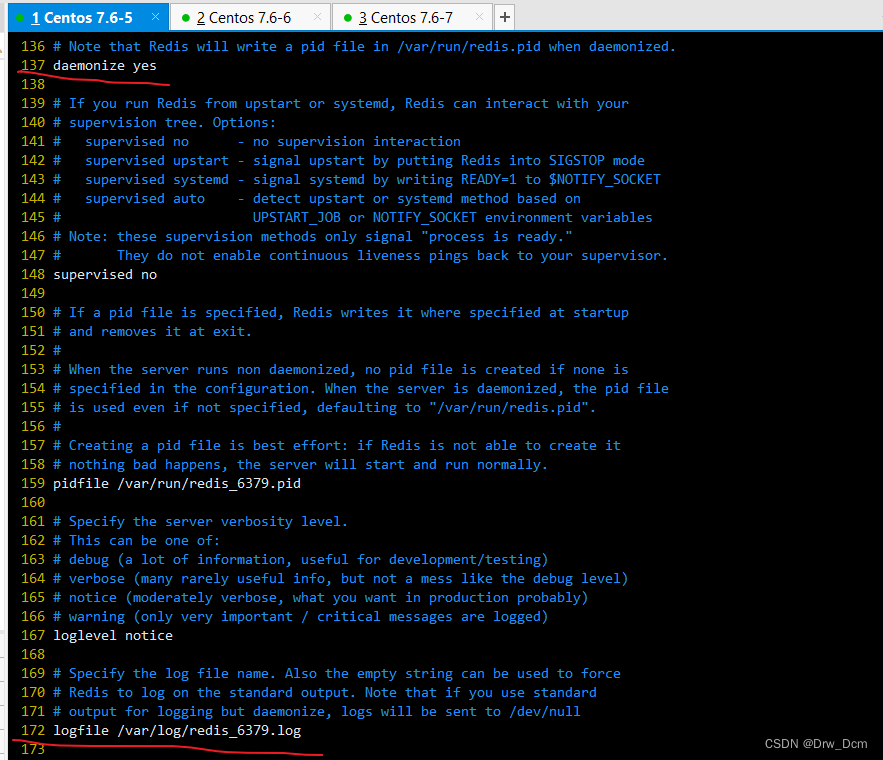

(2)Slave1/2节点
vim /etc/redis/6379.conf bind 0.0.0.0 70行, 修改监听地址为0.0.0.0 daemonize yes 137行,开启守护进程 logfile /var/log/redis_6379.log 172行,指定日志文件目录 dir /var/lib/redis/6379 264行,指定工作目录 replicaof 192.168.22.186 6379 288行,指定要同步的Master节点IP和端口 appendonly yes 700行,开启AOF持久化功能 /etc/init.d/redis_6379 restart 重启服务使配置生效
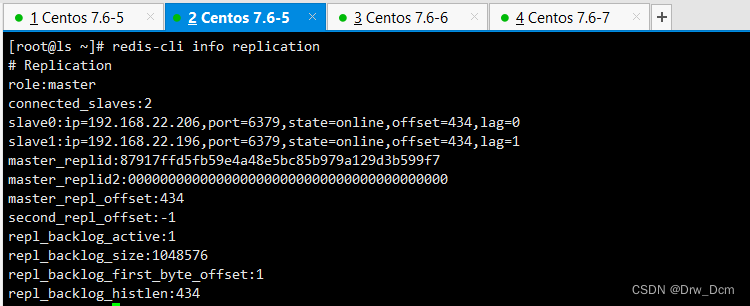
(3)验证主从效果
主节点输入
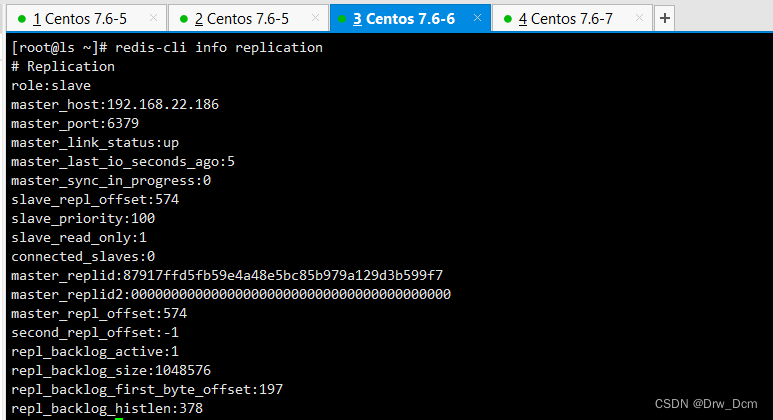
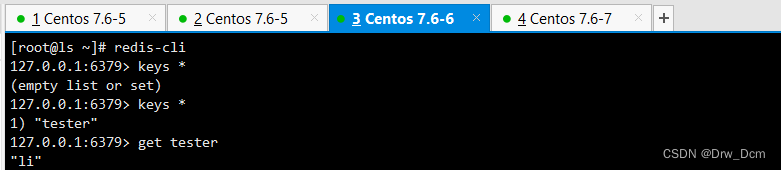
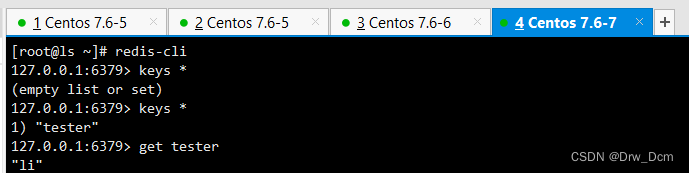
tail -f /var/log/redis_6379.1ogredis-cli info replication master启动时生成的40位16进制的随机字符串,用来标识master节点 切换主从的时候master节点标识会有更改 复制流中的一个偏移量,master处理完写入命令后,会把命令的字节长度做累加记录,统计在该字段。该字段也是实现部分复制的关键字段。 无论主从,都表示自己上次主实例repid1和复制偏移量:用于兄弟实例或级联复制,主库故障切换psyncredis-cli keys * set get
(4)报错排查
WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/ somaxconn is set to the lower value of 128 当前每一个端口最大的监听队列的长度不满足这个高负载环境,需要调整 解决办法 echo 2048 > /proc/sys/net/core/somaxconn WARNING overcommit_ memory is set to 0! Background save may fail under low memory condition 内存超额警告, 当前内存设置为0会导致后台保存失败 解决办法 echo "vm.overcommit_memory=1" > /etc/sysctl.conf 刷新配置文件保其生效 memory usage issues with Redis 内核中启用了透明大页面(THP)支持会将导致Redis的延迟和内存使用问题 解决: echo never > /sys/kerne1/mm/transparent_hugepage/enabled Error condition on.socket.for SYNC: Connection reset by peer 连接被拒绝,因为主服务器可能绑定了自身IP地址 解决办法, 主节点配置文件 bind 0.0.0.0

















四、哨兵模式
在主从复制的基础上起到主节点自动故障转移的作用
1.作用及原理
(1)哨兵模式的作用
1)监控
2)哨兵会不断地检查主节点和从节点是否运作正常
3)自动故障转移.
4)当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点
5)通知
6)哨兵可以将故障转移的结果发送给客户端(2)哨兵模式的原理
一个分布式系统,用于对主从结构中的每台服务器进行监控,当出现故障时通过投票机制选择新的Master 并将所有slave连接到新的Master。
整个运行哨兵的集群的数量不得少于3个节点。2.结构
哨兵结构由两部分组成,哨兵节点和数据节点。
(1)哨兵节点
哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的redis节点,不存储数据。
(2)数据节点
主节点和从节点都是数据节点。
3.工作过程
哨兵的启动依赖于主从模式,所以须把主从模式安装好的情况下再去做哨兵模式,所以节点上都需要部署哨兵模式,哨兵模式会监控所有的Redis工作节点是否正常。
当Master出现问题的时候,因为其他节点与主节点失去联系,因此会投票,投票过半就认为这个Master的确出现问题,然后会通知哨兵间会推选出一个哨兵来进行故障转移:工作(由该哨兵米指定哪个slave来做新的master),然后从Slaves 中选取一个作为新的Master。
筛选方式是哨兵互相发送消息,并且参与投票,票多者当选
需要特别注意的是,客观下线是主节点才有的概念,即如果从节点和哨兵节点发生故障,被哨兵主观下线后,将不会再有后续的客观下线和故障转移操作( 及哨兵模式只负责Master的方面,而不管Slaves)。
当某个哨兵发现主服务器挂掉了,会将master中的SentinelRedistance 中的master
改为SRI_S_DOWN (主观下线),并通知其他哨兵,告诉他们发现master挂掉了。
其他哨兵在接收到该哨兵发送的信息后,也会尝试去连接master,如果超过半数(配置文件中设置的)确认master挂掉后,会将master中的SentinelRedistance中的master改为SRI_O_DOWN (客观下线)。
五、应用哨兵模式
节点名IP地址
master 192.168.22.186
slave1 192. 168.22.196
slave2 192. 168.22.206修改哨兵配置文件[所有节点皆需]
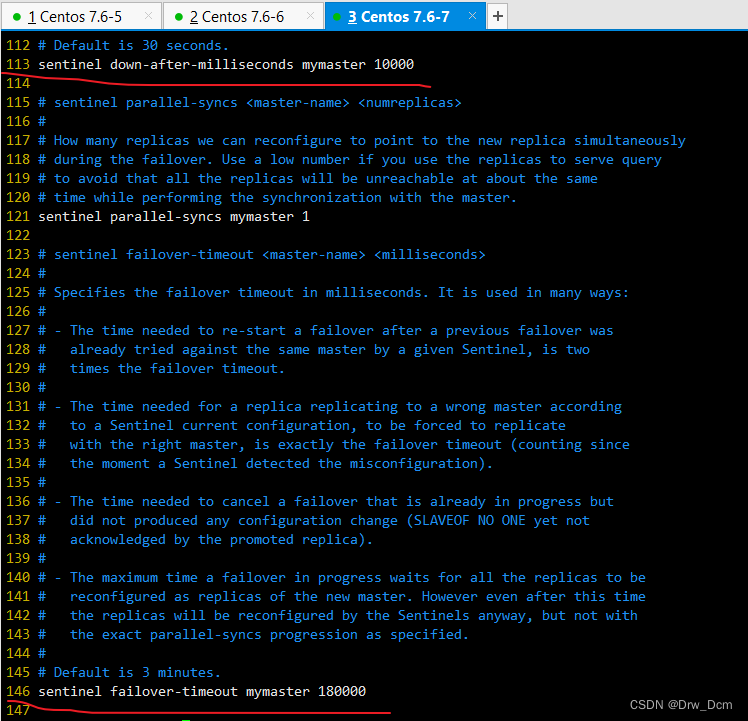
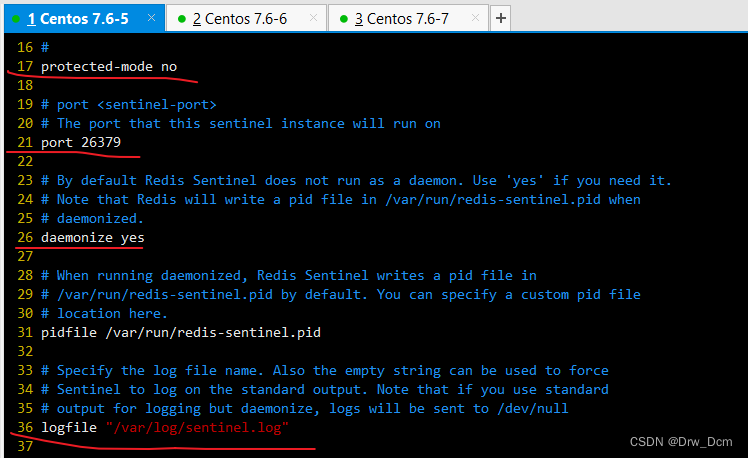
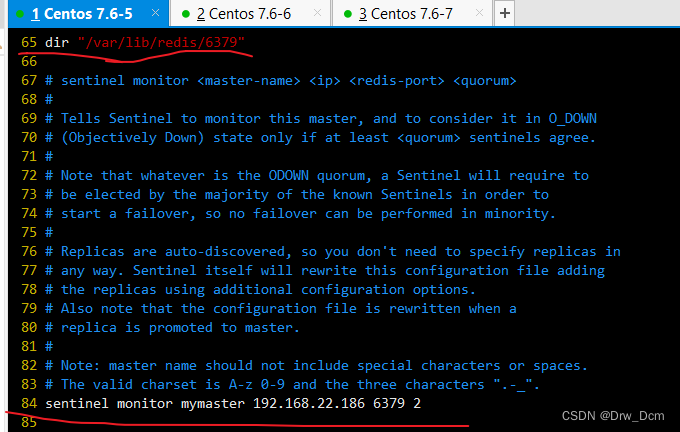
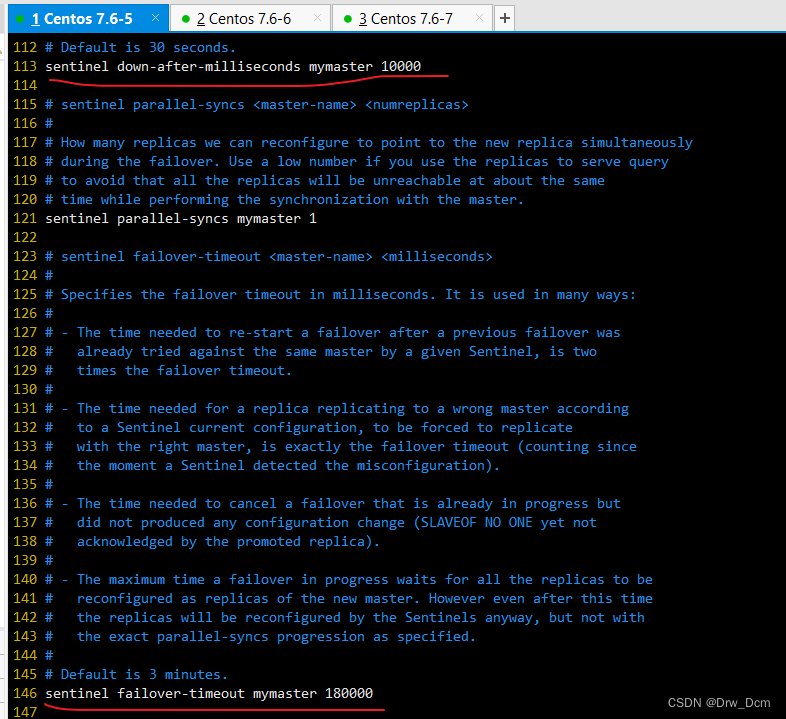
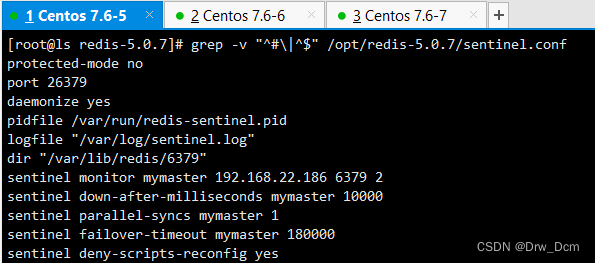
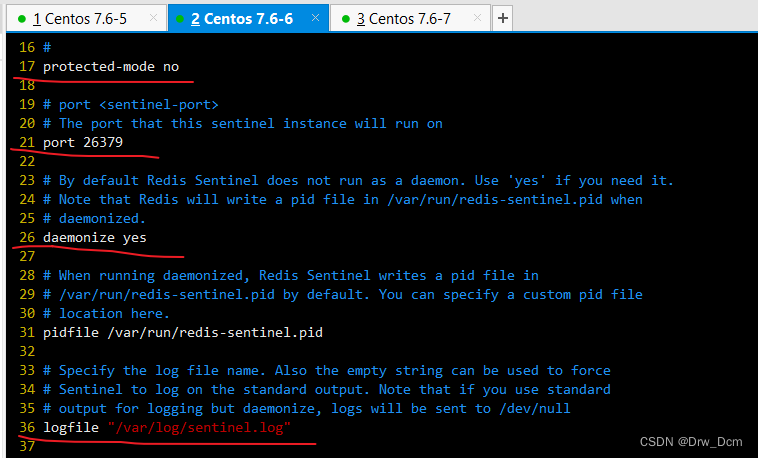
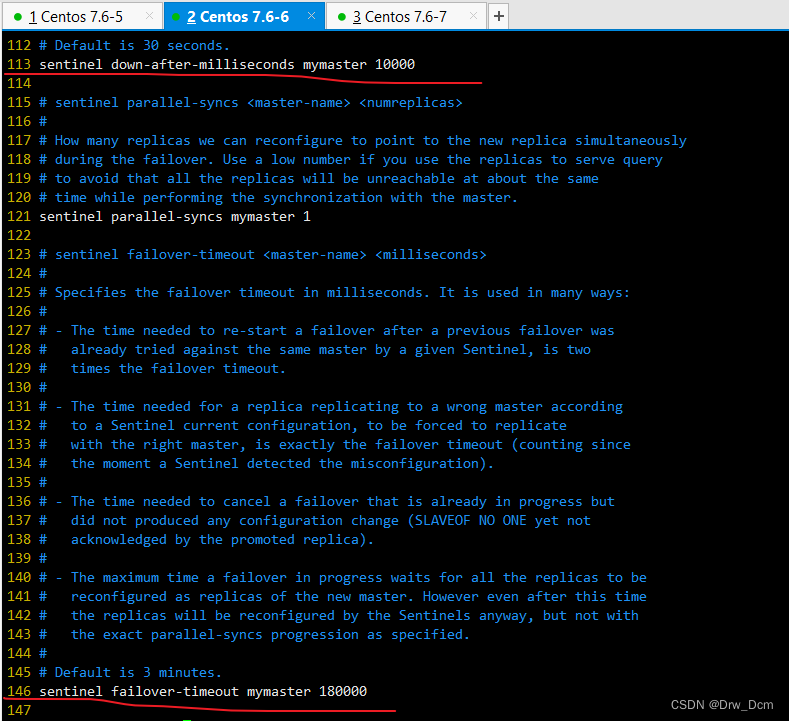
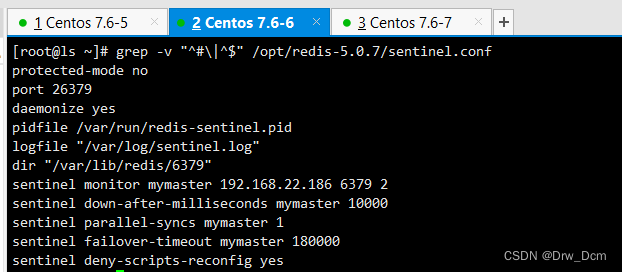
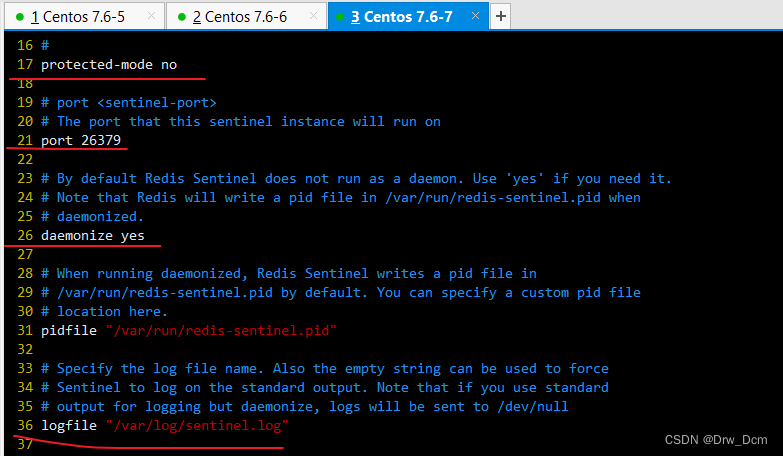
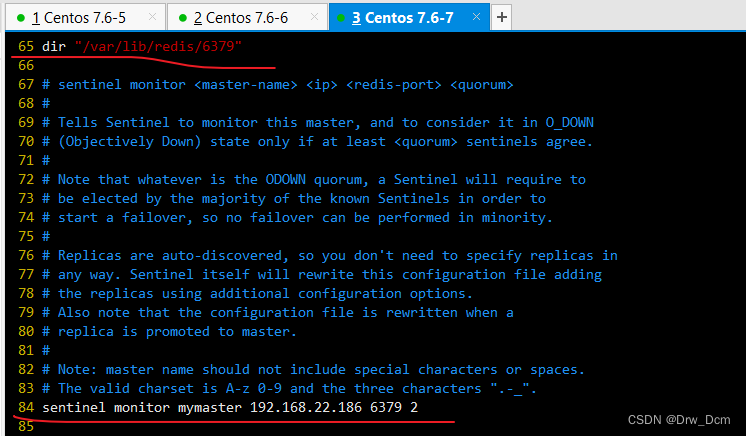
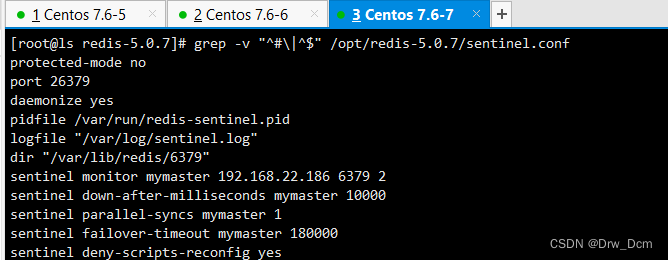
vim /opt/redis-5.0.7/sentinel.conf 17行, 关闭保护模式 protected-mode no 21行,Redis哨兵默认的监听端口 port 26379 26行开启守护进程 daemonize yes 36行,指定日志存放路径 logfile "/var/log/sentinel.log" 65行,指定数据库存放路径 dir "/var/lib/redis/6379" 84行,指定哨兵节点 2表示,至少需要2个哨兵节点同意,才能判定主节点故障并进行故障转移 sentinel monitor mymaster 192.168.22.186 6379 2 113行, 判定服务器down掉的时间周期,默认30000毫秒(30秒 ) sentinel down-after-mill iseconds mymaster 3000 146行, 故障节点的最大超时时间为180000 (180秒) sentinel failover-t imeout mymaster 180000
启动哨兵模式
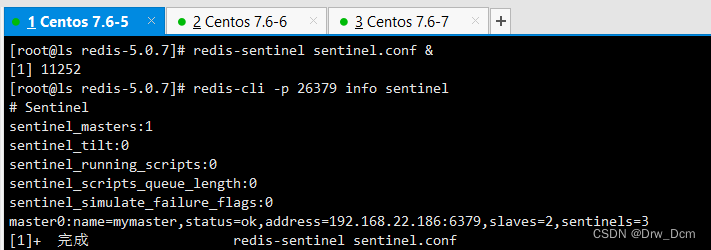
先启动主节点在启动从节点cd /opt/redis-5.0.7/ redis-sentinel sentinel.conf &
查看哨兵信息
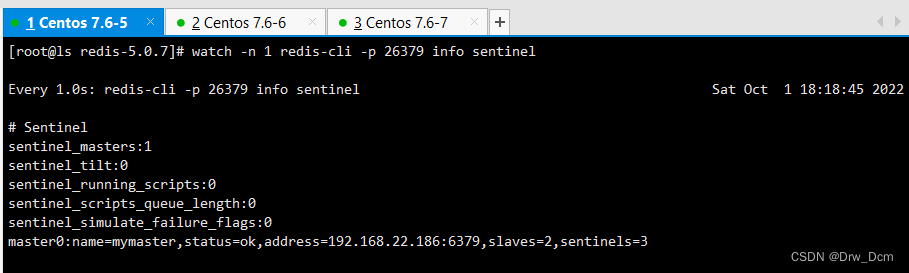
redis-cli -p 26379 info sentinel
模拟故障(rm -rf /var/run/redis_6379.pid)
ps -ef | grep "redis" 查看redis-server 的进程号 kill -9 杀死Master节点上的redis-server的进程号查看哨兵信息
redis-cli -p 26379 info sentinel status-odown: o即objectively,客观查看master哨兵日志
验证结果






网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
查看哨兵信息
redis-cli -p 26379 info sentinel
模拟故障(rm -rf /var/run/redis_6379.pid)
ps -ef | grep "redis" 查看redis-server 的进程号 kill -9 杀死Master节点上的redis-server的进程号查看哨兵信息
redis-cli -p 26379 info sentinel status-odown: o即objectively,客观查看master哨兵日志
验证结果
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-hGWfwKdv-1713322566548)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









