








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果数据库已经分库,那么需要从多个库查询数据聚合,这就无法使用数据库的排序和分页功能,此时也只能采用重读轻写的思路,把关联数据提前计算好,存在一个地方,读的时候直接查询聚合好的数据。也可以用ES类的搜索引擎来实现,把多表关联的结果做成一个个文档,放在搜索引擎里面,也可以做到灵活排序和分页查询。
我们也可以称这种方式为“数据异构”。分库分表中有一个最为常见的场景,为了提升数据库的查询能力,我们都会对数据库做分库分表操作。比如订单库,开始的时候我们是按照订单ID维度去分库分表,那么后来的业务需求想按照商家维度去查询,此时查询某一个商家下的所有订单就非常麻烦,这个时候我们通过数据异构把存储一张商家维度的订单表就可解决这一问题。
总结:读写分离
不论时加缓存、动静分离,还是重读轻写(数据异构),其本质都是读写分离,也就是微服务架构经常提到的CQRS(Comman Query Responsibitlity Separation)
下图总结了读写分离架构的典型模型,该模型有几个典型特征:
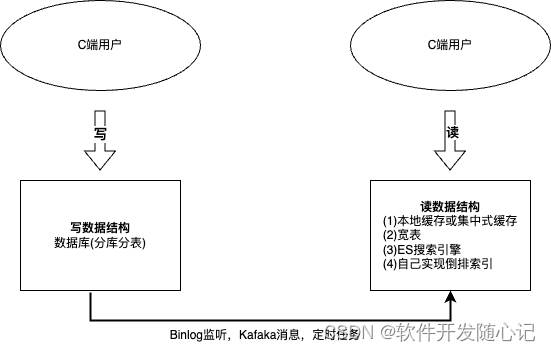
(1)分别为读写设计不同的数据结构。把系统分为读和写两个不同的视角来设计,各自设计高并发读和高并发写的数据结构或数据模型。可以看到,缓存其实是读写分离的一个简化,或者说是一个特例,左边写(DB)和右边读(缓存)其实用的基本一样的数据结构。
(2)写的这一端,通常也是在线业务DB,通过分库分表抵抗压力。读的这一端,为了扛住高并发压力,针对不通的业务场景,可能是缓存,也可能是提前join好的宽表,或者是ES搜索引擎,如果ES的性能不足,则可以自己建立倒排索引和搜索引擎。
(3)读和写的串联。定时任务把业务数据库中的数据转换为适合高并发读的数据结构,或者是写的一端把数据变更完成后发送消息给读的一端消费消息,或者读的一端直接监听数据库中的binlog,监听数据变化来更新读的一端的数据。
(4)读比写有延迟。因为左边写的数据是实时变化的,然后读的一端消费消息,读取端肯定会有所延迟,但和写之间是最终一致性,而不是强一致性,在绝大部分场景下应该是不影响业务的。
二、高并发写
**策略一:**数据分片
数据分片就是对要处理的数据或请求分成多份并行处理。
案例1: 数据库的分库分表。
分表后,虽然数据请求还是在一台机器上,但是可以更加充分利用机器的CPU,内存等资源。分库后,可以利用多台机器的资源。
案例2: JDK ConcurrentHashMap的实现
ConcurrentHashMap在内部分成了若干了槽,也就是若干个HashMap,这些槽可以并发的读写,槽与槽之间是独立的,不会发生数据互斥。
案例3: Kafka的partition
在Kafaka中,一个topic表示一个逻辑上的消息队列,但物理上会分散到多个partition上存储,partition之间也是相互独立的,也就提高了topic的并发量。
案例4: ES的分布式索引
在搜索引擎里有一个基本的策略就是分布式索引。当为一个比较的数据集建立索引时,索引本身也会很大,无法并发查询,可以把数据集分成n份,建成n个小索引,一个请求过来之后,可以并行的在n个索引上查询,再把结果集进行合并。
**策略二:**任务分片
数据分片是对要处理的数据或者请求进行分片,而任务分片是对处理程序本身进行分片。现实生活中工厂的流水线作业就是任务分片的例子。
案例1:CPU指令流水线
一致CPU指令可以拆成“取指”,“译码”,“执行”,“回写”四个阶段,四个阶段可以并行执行。
案例2: Map/Reduce
把任务拆解同时运行,归并排序算法也是这种思想,在时间复杂度上明显降低。
案例3: 1+N+M的网络模型

在服务端的网络编程中,不论时Tomcat,Netty, 还是Linux的epoll,都是基于这个1+N+M的网络模型。把一个请求的处理分成了三个工序:监听、I/O,业务逻辑处理。1个监听线程负责监听客户端socket请求;N个I/O线程负责对Socket进行读写,N约等于CPU的核数,M个线程负责对请求进行逻辑处理。进一步讲,Work线程还可以拆分成解码,业务逻辑处理,编码等环节。进一步提升并发度。
**策略三:**异步化
异步化常用接口表和队列术两种方式,接口表就是服务端收到请求后,把请求体写到接口表中,通过定时任务异步处理接口表中的请求数据。队列术就是把请求放到消息队列中,通过异步消息消费任务异步处理。此外,消息队列在系统解耦,数据同步,流量削峰等场景中也有广泛的使用。
场景1: 短信验证码注册或登录
通常注册或者登录APP或小程序时,采用的方式为短信验证码,短信的发送需要依赖第三方的短信发送平台。而公网的调用可能耗时较长,如果是同步调用,则应用服务器会被阻塞,当请求达到一定量级之后,应用就会卡死。

改成异步调用就能避免这一问题。应用服务器收到客户端请求后,放到消息队列并立即返回成功,然后有一个后台任务,从消息队列中读取消息,取调用第三方短信平台发送验证码。即使客户端请求的并发量很大,最多是消息堆积在消息队列里面,同时消息消费如果调用第三方平台超时,也很容易发起重试。
场景2: LSM树(写内存 + Write-Ahead日志)
LSM用到的一个核心思想就是“异步写”。LSM树支持的KV存储,当插入的时候,K是无序的,但是磁盘上又需要按照K的大小顺序存储(方便检索),也就是在磁盘上要实现一个SortedHashMap,但不可能在插入的同时对磁盘上的数据进行排序,因为需要保证数据存储顺序,需要做随机写,并且可能做大规模的数据移动,该操作必然非常耗时。
那LSM是怎么解决这个问题呢?
既然写磁盘慢,那就先不写磁盘,在内存中维护一个SortedHashMap,这样写就性能非常高了,但是数据只存储在内存,系统只要宕机就会丢失数据,所以另外再写一条日志,也就是Write-Head日志。日志有一个关键的有点就是顺序写入,即只会在日志尾部追加,而不用随机写入,所以写日志的耗时时非常短的。
有了日志的顺序写入,再加上内存的SortedHashMap,再有一个后台任务定期把内存中的SortedHashMap合并刷到磁盘文件中即可,通过异步落盘,大幅度的提高了写入的性能。这里发现这个思路和Mysql InnoDB存储引擎的redo log有异曲同工之妙。
写内存+Write-Ahead日志的这种思路不仅在数据库和KV存储领域使用,在上层业务领域中同样可以使用。比如高并发扣减电商系统中的库存,如果直接在数据库中扣,数据库会扛不住,则可以在redis中扣,同时写一条日志。当Redis宕机,把所有日志重放完毕,再用数据库中的初始化数据Redis中的数据。
场景3: Kafka的PipLine
Kafka为了保证其高可用性,会为每个Partition准备多个副本,假设一个Partition有3个副本,一个被选为Leader,另外两个时Follower。对于同步发送,客户端每发送一条消息,Leader需要把这条消息同步到两个Follower之后,才会对客户端返回成功。要实现这一点,最朴素的想法就是当客户端给Leader发送一个msg,Leader把msg同步给Follower1和Follower2,然后给客户端返回成功,这种想法很直接,但是显然效率不够。对于该问题,Kafka采用了一个典型的策略来解决,那就时PipLine,也是异步化的一种。
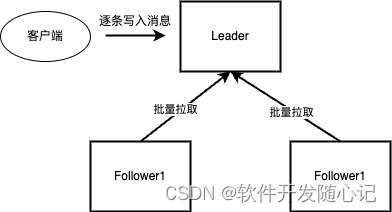
如图,Leader并不会主动给两个Follower同步数据,而是等Follower主动过来拉取,并且是批量拉取。当Leader收到客户端的消息msg并且保存到本地后,就去做其他事情了,比如接受下一条消息,此时客户端还处于阻塞状态,等待msg返回。只要等两个Follower都把消息同步过去之后,Leader才会给客户端返回接受成功。
那这种方式为什么叫PipLine呢?因为Leader并不是一个一个的处理消息,而是一批一批的处理,Leader和两个Follower像是组成一个管道,消息像水一样流过管道。
PipLine是异步化的一个例子,同时它也是策略二所讲的任务分片的典型例子,对于Leader来说,他把任务做了拆分,一个接受并存储客户端的消息任务,一个是同步消息到Follower的任务,两个任务是并行的。
**策略四:**批量
“批量”的含义通俗易懂,既然一条一条写入慢,那就多条合并,一次写入。
场景1:Kafka的百万QPS写入
Kafka的客户端在内存中为每一个Partition准备了一个队列,称为RecordAccumulator. Producer线程一条条的发送消息,这些消息都进入都内存队列,然后通过Sender线程从这些队列中批量地提取消息发送给到Kafka集群。
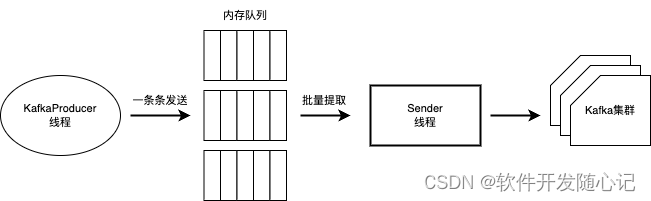
对于具体的批量策略,Kafka提供了几种参数进行配置,可以按Batch的大小或等待时间来批量操作。
场景2: Mysql小事务合并机制
比如扣减库存,对同一个SKU,本来是扣10次,每次扣1,就会产生10个事务,在Mysql内核里面合并成1个扣10个,也就是10个事务合并成了一个。
在多机房的数据库多活(跨数据中心的数据库复制)场景中,事务合并也是加速数据库复制的一个重要策略。
以上就是我在架构学习当中总结的一些提升软件性能的应对策略,很多思想都是可以具体的业务场景中套用的。先从架构层面看软件设计,然后再深入细节,或许会对一些优秀的开源软件设计理解得更加深入。
作者:西门吹雪

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









