







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文

文章目录
Flink运行时架构介绍
我们已经对 Flink 的主要特性和部署提交有了基本的了解,那它的内部又是怎样工作的,集群配置设置的一些参数又到底有什么含义呢?
接下来我们就将钻研 Flink 内部,探讨它的运行时架构,详细分析在不同部署环境中的作业提交流程,深入了解 Flink 设计架构中的主要概念和原理。
一、系统架构
对于数据处理系统的架构,最简单的实现方式当然就是单节点。当数据量增大、处理计算更加复杂时,我们可以考虑增加 CPU 数量、加大内存,也就是让这一台机器变得性能更强大,从而提高吞吐量——这就是所谓的 SMP(Symmetrical Multi-Processing,对称多处理)架构。但是这样做问题非常明显:所有 CPU 是完全平等、共享内存和总线资源的,这就势必造成资源竞争;而且随着 CPU 核心数量的增加,机器的成本会指数增长,所以 SMP 的可扩展性是比较差的,无法应对海量数据的处理场景。
于是人们提出了“不共享任何东西”(share-nothing)的分布式架构。从以 Greenplum 为代表的 MPP(Massively Parallel Processing,大规模并行处理)架构,到 Hadoop、Spark 为代表的批处理架构,再到 Storm、Flink 为代表的流处理架构,都是以分布式作为系统架构的基本形态的。
我们已经知道,Flink 就是一个分布式的并行流处理系统。简单来说,它会由多个进程构成,这些进程一般会分布运行在不同的机器上。
正如一个团队,人多了就会难以管理;对于一个分布式系统来说,也需要面对很多棘手的问题。其中的核心问题有:集群中资源的分配和管理、进程协调调度、持久化和高可用的数据存储,以及故障恢复。
对于这些分布式系统的经典问题,业内已有比较成熟的解决方案和服务。所以 Flink 并不会自己去处理所有的问题,而是利用了现有的集群架构和服务,这样它就可以把精力集中在核心工作——分布式数据流处理上了。Flink 可以配置为独立(Standalone)集群运行,也可以方便地跟一些集群资源管理工具集成使用,比如 YARN、Kubernetes。Flink 也不会自己去提供持久化的分布式存储,而是直接利用了已有的分布式文件系统(比如 HDFS)或者对象存储(比如 S3)。而对于高可用的配置,Flink 是依靠 Apache ZooKeeper 来完成的。
我们所要重点了解的,就是在 Flink 中有哪些组件、是怎样具体实现一个分布式流处理系统的。如果大家对 Spark 或者 Storm 比较熟悉,那么稍后就会发现,Flink 其实有类似的概念和架构。
二、整体构成
Flink 的运行时架构中,最重要的就是两大组件:作业管理器(JobManger)和任务管理器(TaskManager)。对于一个提交执行的作业,JobManager 是真正意义上的“管理者”(Master),
负责管理调度,所以在不考虑高可用的情况下只能有一个;而 TaskManager 是“工作者”(Worker、Slave),负责执行任务处理数据,所以可以有一个或多个。Flink 的作业提交和任务
处理时的系统如图所示。
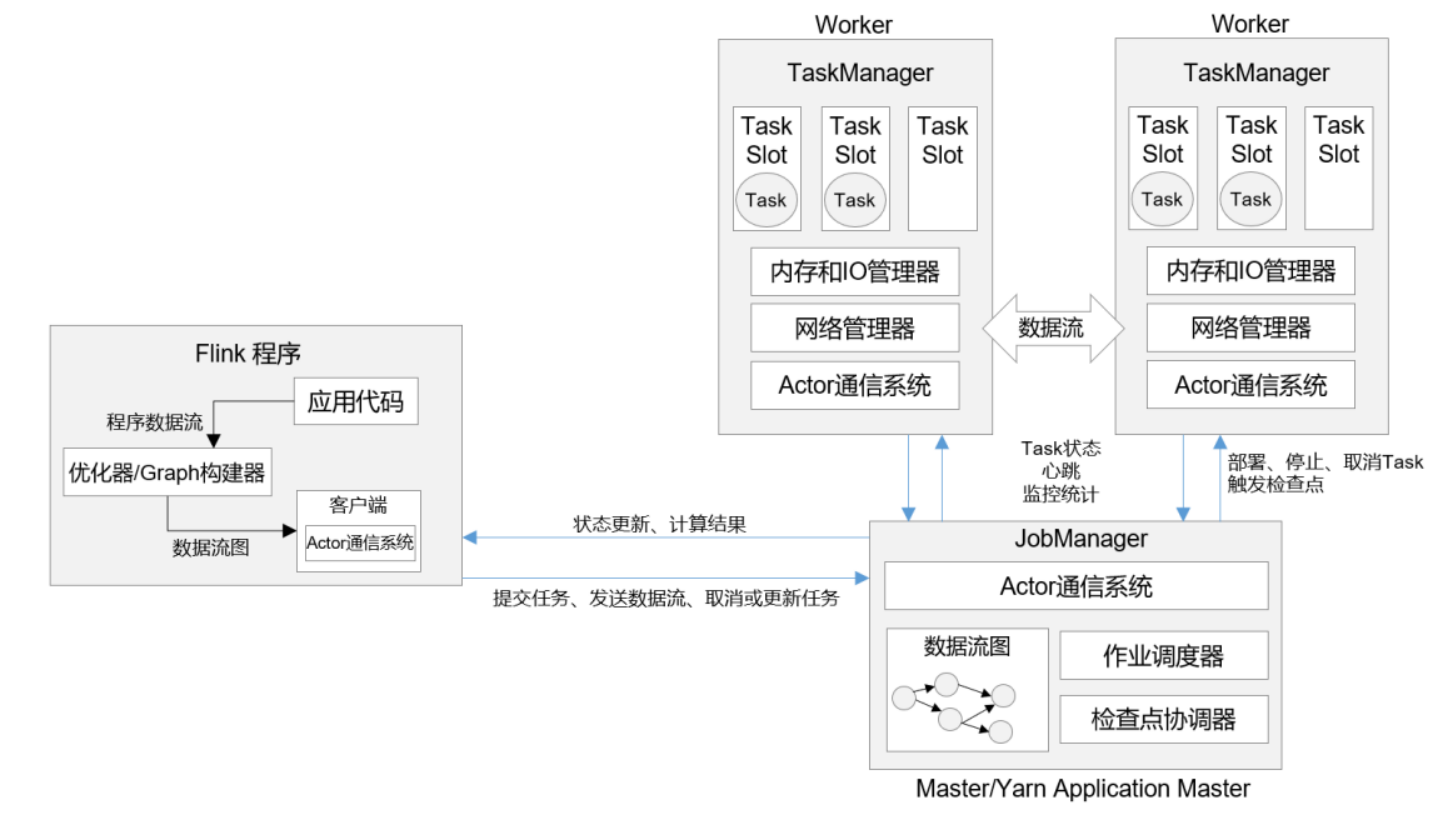
这里首先要说明一下“客户端”。其实客户端并不是处理系统的一部分,它只负责作业的提交。具体来说,就是调用程序的 main 方法,将代码转换成“数据流图”(Dataflow Graph),
并最终生成作业图(JobGraph),一并发送给 JobManager。提交之后,任务的执行其实就跟客户端没有关系了;我们可以在客户端选择断开与 JobManager 的连接, 也可以继续保持连接。
之前我们在命令提交作业时,加上的-d 参数,就是表示分离模式(detached mode),也就是断开连接。
当然,客户端可以随时连接到 JobManager,获取当前作业的状态和执行结果,也可以发送请求取消作业。我们在上一章中不论通过 Web UI 还是命令行执行“flink run”的相关操作,都是通过客户端实现的。
JobManager 和 TaskManagers 可以以不同的方式启动:
- 作为独立(Standalone)集群的进程,直接在机器上启动
- 在容器中启动
- 由资源管理平台调度启动,比如 YARN、K8S
这其实就对应着不同的部署方式。
TaskManager 启动之后,JobManager 会与它建立连接,并将作业图(JobGraph)转换成可执行的“执行图”(ExecutionGraph)分发给可用的 TaskManager,然后就由 TaskManager 具体执行任务。接下来,我们就具体介绍一下 JobManger 和 TaskManager 在整个过程中扮演的角色。
三、作业管理器(JobManager)
JobManager 是一个 Flink 集群中任务管理和调度的核心,是控制应用执行的主进程。也就是说,每个应用都应该被唯一的 JobManager 所控制执行。当然,在高可用(HA)的场景下,可能会出现多个 JobManager;这时只有一个是正在运行的领导节点(leader),其他都是备用节点(standby)。
JobManger 又包含 3 个不同的组件,下面我们一一讲解。
- JobMaster
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
片转存中…(img-ZjuU1d8g-1713389318223)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 1458
1458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









