







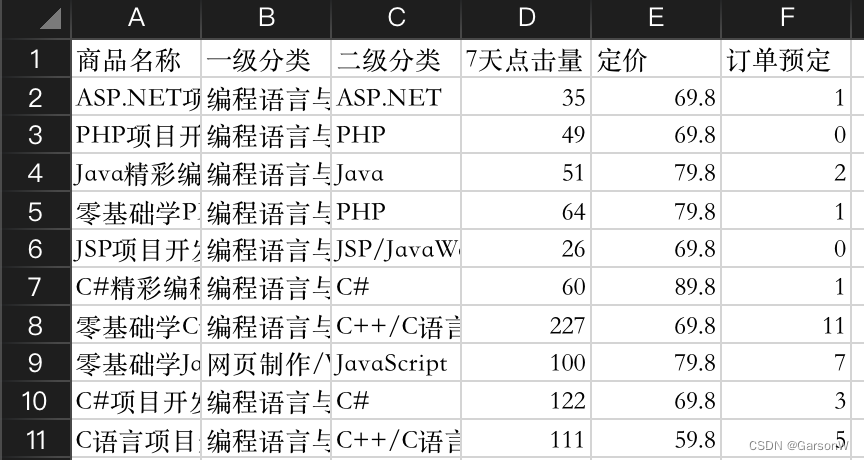
import pandas as pd #导入pandas模块
df=pd.read_csv('JD.csv',encoding='gbk')
#抽取数据
df1=df[['一级分类','7天点击量','订单预定']]
df1=df1.groupby('一级分类').sum() #分组统计求和
示例2:
按照图书“一级分类”和“二级分类”对订单数据进行分组统计求和
import pandas as pd #导入pandas模块
df=pd.read_csv('JD.csv',encoding='gbk')
#抽取数据
df1=df[['一级分类','二级分类','7天点击量','订单预定']]
df2=df1.groupby(['一级分类','二级分类']).sum() #分组统计求和
示例3:
求各二级分类的七天点击量。首先按“二级分类”分类,而后进行分组统计求和。
df1 = df1.groupby('二级分类')['七天点击量'].sum()
2.对分组数据进行迭代
示例1:
按照“一级分类”分组,并且输出每一分类中的订单数据
# 抽取数据
df1 = df[['一级分类',‘七天点击量’,‘订单预定’]]
for name, group in df.groupby('一级分类')
print(name)
print(group)
其中name是‘一级分类’, group是其他数据。因此使用groupby()函数对多列进行分组,那么需要在for循环中指定多列。
3.对分组的某列或多列使用聚合函数
Python也可以实现像SQL中的分组聚合运算操作,主要通过groupby()函数与agg()函数实现。
以下代码实现:
1. 以’一级分类’分组,求分组后的平均值与和
2.以’一级分类’分组,求分组后’七天点击量’的平均值与和,求’订单预定’的和
df1.groupby('一级分类').agg(['mean','sum'])
df1.groupby('一级分类').agg({'七天点击量':['mean','sum'],'订单预定':['sum']})
我们可以通过自定义函数实现数组分组统计。书本p110
以下代码实现:
1.统计一月份销售数据中,购买次数最多的产品,及其人均购买数,人均花费,总购买数,总花费。
df = pd.read_excel('1月.xlsx')
max1 = lambda x: x.value_counts(dropna=false).index[0]
df1 = df.agg({'宝贝标题':[max1],
'数量':['sum','mean'],
'卖家实际支付金额':['sum','mean']})
print(df1)
4.通过字典和Series对象进行分组统计
1.通过字典进行分组统计
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数大数据工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上大数据开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注大数据获取)

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
eTqB-1712984963606)]
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 3535
3535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









