








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
kafka-server-start.sh /opt/soft/kafka211/config/server.properties
二、创建 Topic 消息队列
kafka-topics.sh --create --zookeeper 192.168.56.137:2181 --topic demo12 --replication-factor 1 --partitions 1
三、查询 kafka 消息队列
kafka-topics.sh --zookeeper 192.168.56.137:2181 --list
做完前三步,我们可以看下结果大致如下:

四、启动 consumer 监控窗口
kafka-console-consumer.sh --bootstrap-server 192.168.56.137:9092 --topic demo3 --from-beginning
五、写 Flume 自定义配置文件
这里的路径是:/opt/soft/flumconf
a7.sources=r7
a7.sinks=k7
a7.channels=c7
a7.sources.r7.type=spooldir
a7.sources.r7.spoolDir=/opt/soft/data/user_friends
a7.sources.r7.deserializer.maxLineLength=150000
a7.sources.r7.interceptors=f1
a7.sources.r7.interceptors.f1.type=regex_filter
a7.sources.r7.interceptors.f1.regex=^(\\s\*user\\s\*,\\s\*friends\\s\*)$
a7.sources.r7.interceptors.f1.excludeEvents=true
a7.sinks.k7.type=org.apache.flume.sink.kafka.KafkaSink
a7.sinks.k7.topic=demo13
a7.sinks.k7.kafka.bootstrap.servers=192.168.56.137:9092
a7.sinks.k7.serializer.class=kafka.serializer.StringEncoder
a7.channels.c7.type=memory
a7.channels.c7.capacity=1000
a7.channels.c7.transactionCapacity=100
a7.sources.r7.channels=c7
a7.sinks.k7.channel=c7
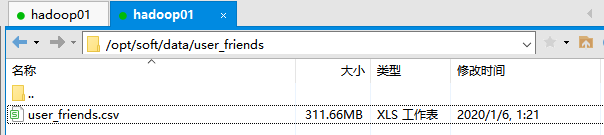
这是 CSV 数据源的路径,如下:
六、开启 Flume
flume-ng agent -n a6 -c conf -f /opt/soft/flumeconf/demo5.properties

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 1834
1834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









