







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)

正文
1.2Lastmodified模式增量导入
使用incremental的方式进行增量的导入:
bin/sqoop import
–connect jdbc:mysql://node-1:3306/userdb
–username root
–password hadoop
–table customertest
–target-dir /lastmodifiedresult
–check-column last_mod
–incremental lastmodified
–last-value “2019-05-28 18:42:06”
–m 1
–append
注意: 此处已经会导入我们最后插入的一条记录,但是我们却发现此处插入了2条数据,这是为什么呢?这是因为采用lastmodified模式去处理增量时,会将大于等于last-value值的数据当做增量插入。
1.3Lastmodified模式:append、merge-key
使用lastmodified模式进行增量处理要指定增量数据是以append模式(附加)还是merge-key(合并)模式添加. 下面演示使用merge-by的模式进行增量更新,我们去更新 id为1的name字段。
update customertest set name = ‘Neil’ where id = 1;
更新之后,这条数据的时间戳会更新为更新数据时的系统时间.
执行如下指令,把id字段作为merge-key:
bin/sqoop import
–connect jdbc:mysql://node-1:3306/userdb
–username root
–password hadoop
–table customertest
–target-dir /lastmodifiedresult
–check-column last_mod
–incremental lastmodified
–last-value “2019-05-28 18:42:06”
–m 1
–merge-key id
由于merge-key模式是进行了一次完整的mapreduce操作,
因此最终我们在lastmodifiedresult文件夹下可以看到生成的为part-r-00000这样的文件,会发现id=1的name已经得到修改,同时新增了id=6的数据。
### 4. 但双引号以及转义
#### A. 双引号
–query 后双引号特殊符号需要转义,
- $condition是==> “xxx $conditions”;
- SQL 关键字 result 需要转义 ==> `result`
- <>号不用转义
#### B. 单引号
–query 后 单 引号特殊符号可以不转义
### 3. sqoop export
#### A. 参数
– 没有推出全量覆盖,所以我们才有 sqoop eval 先删除对方MySQL、oracle 数据
– hive-overwrite 是sqoop import的参数
##### A1.探索测试
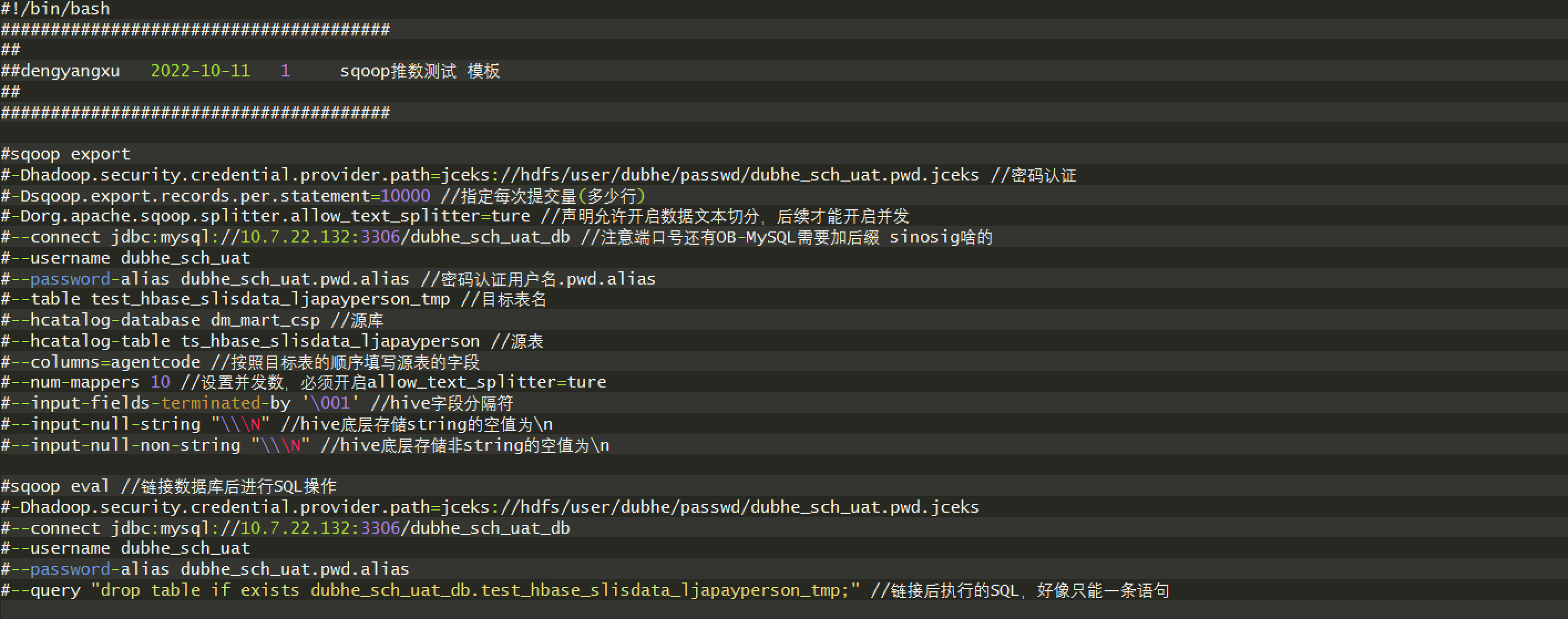
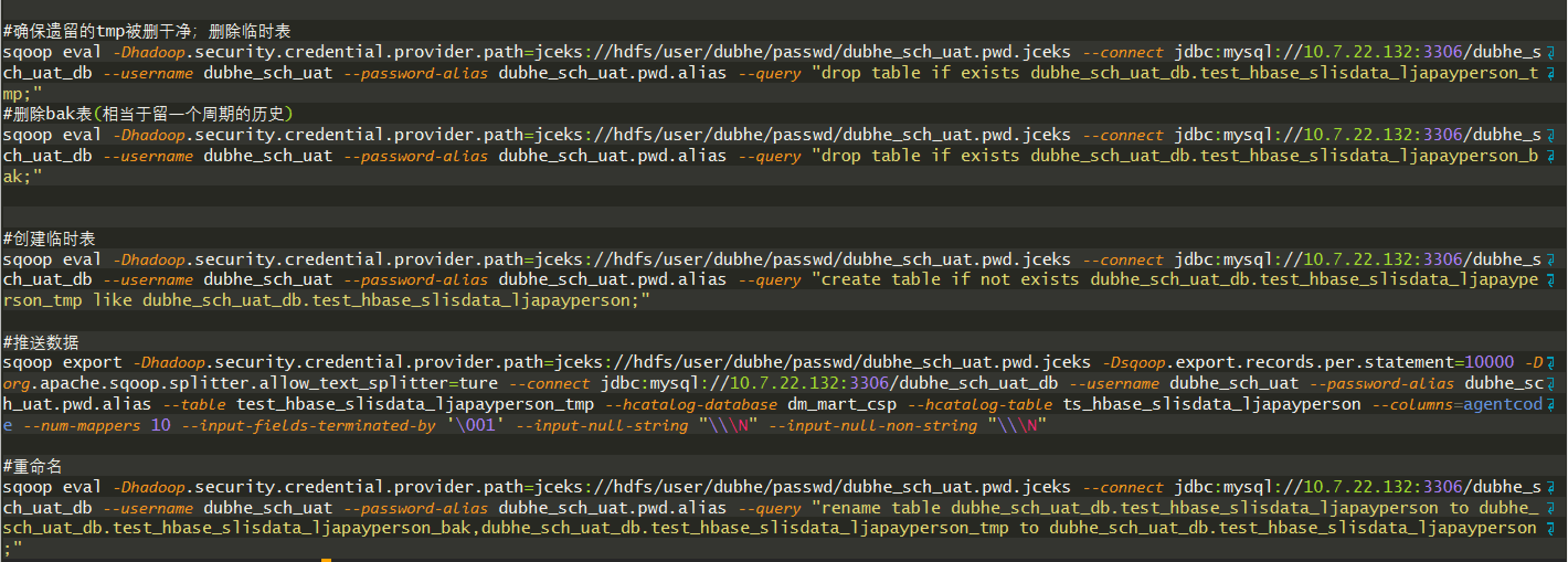
#### B. 案例
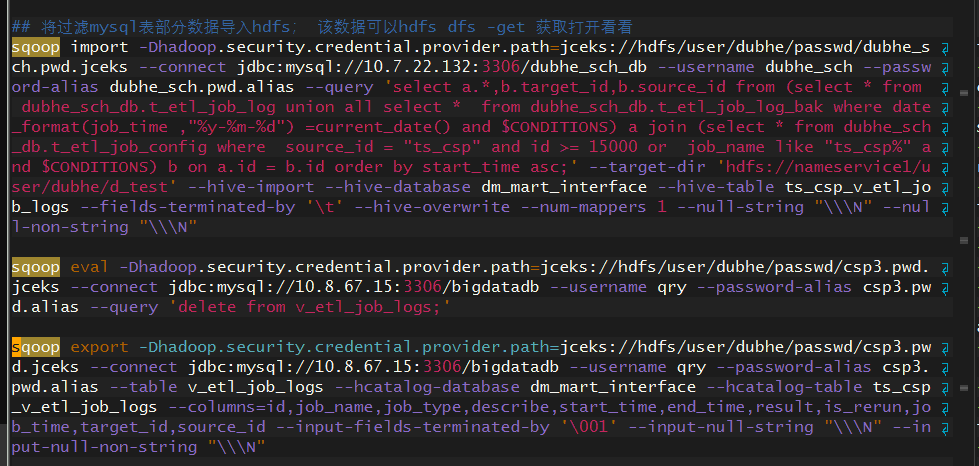
#!/bin/bash
将过滤mysql表部分数据导入hdfs; 该数据可以hdfs dfs -get 获取打开看看
sqoop import -Dhadoop.security.credential.provider.path=jceks://hdfs/user/dubhe/passwd/dubhe_sch.pwd.jceks --connect jdbc:mysql://10.7.22.132:3306/dubhe_sch_db --username dubhe_sch --password-alias dubhe_sch.pwd.alias --query ‘select a.*,b.target_id,b.source_id from (select * from dubhe_sch_db.t_etl_job_log union all select * from dubhe_sch_db.t_etl_job_log_bak where date_format(job_time ,“%y-%m-%d”) =current_date() and $CONDITIONS) a join (select * from dubhe_sch_db.t_etl_job_config where source_id = “ts_csp” and id >= 15000 or job_name like “ts_csp%” and $CONDITIONS) b on a.id = b.id order by start_time asc;’ --target-dir ‘hdfs://nameservice1/user/dubhe/d_test’ --hive-import --hive-database dm_mart_interface --hive-table ts_csp_v_etl_job_logs --fields-terminated-by ‘\t’ --hive-overwrite --num-mappers 1 --null-string “\\N” --null-non-string “\\N”
sqoop eval -Dhadoop.security.credential.provider.path=jceks://hdfs/user/dubhe/passwd/csp3.pwd.jceks --connect jdbc:mysql://10.8.67.15:3306/bigdatadb --username qry --password-alias csp3.pwd.alias --query ‘delete from v_etl_job_logs;’
sqoop export -Dhadoop.security.credential.provider.path=jceks://hdfs/user/dubhe/passwd/csp3.pwd.jceks --connect jdbc:mysql://10.8.67.15:3306/bigdatadb --username qry --password-alias csp3.pwd.alias --table v_etl_job_logs --hcatalog-database dm_mart_interface --hcatalog-table ts_csp_v_etl_job_logs --columns=id,job_name,job_type,describe,start_time,end_time,result,is_rerun,job_time,target_id,source_id --input-fields-terminated-by ‘\001’ --input-null-string “\\N” --input-null-non-string “\\N”
##### B2. sqoop2oracle
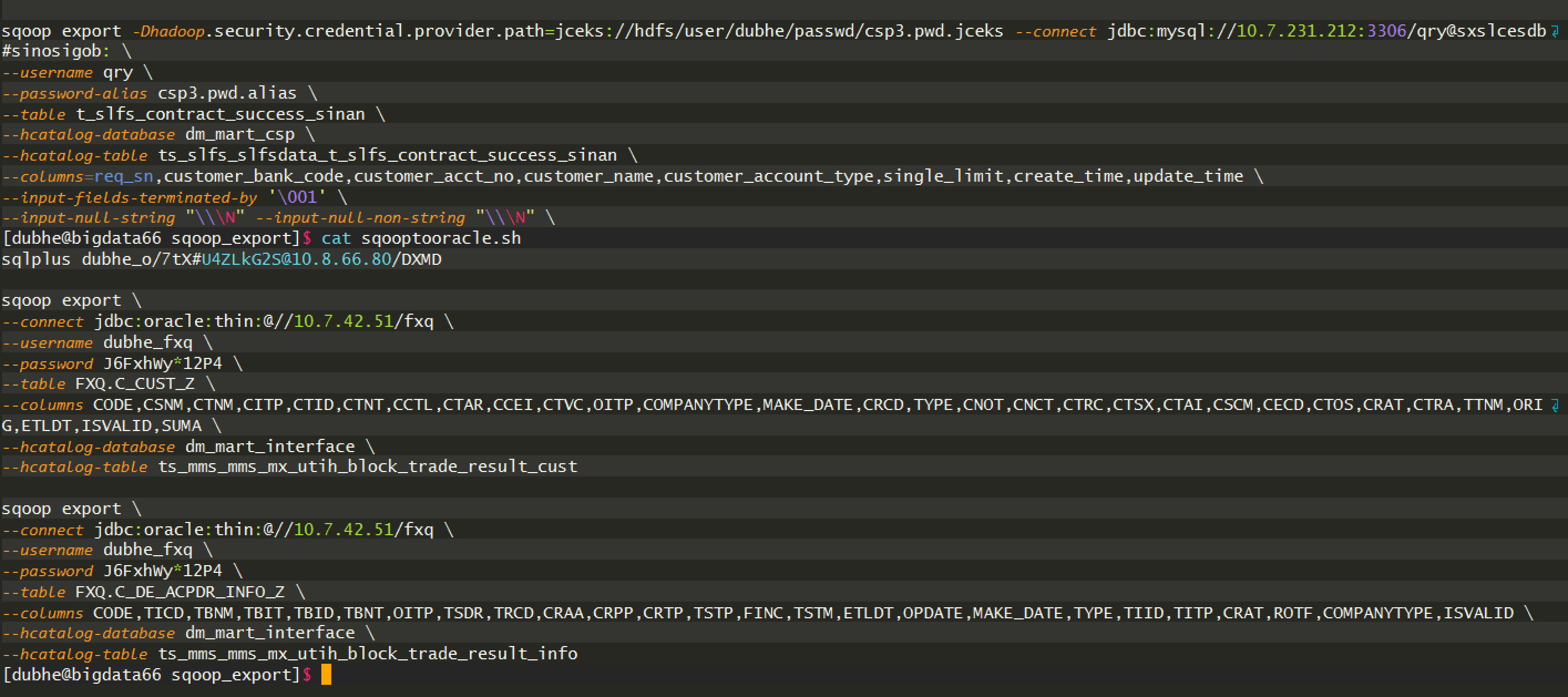
### 2.SQOOP密码管理
#### A. SQOOP-HADOOP
1. hadoop credential create ${db_config表sys_id}.pwd.alias -provider jceks://hdfs/user/dubhe/passwd/${db_config表sys_id}.pwd.jceks
### 1. mysql2hive
#### A. Mysql2Hive
* 目标表不存在
* 目标表已存在
##### A1. 目标表不存在
>
> 目标表不存在
>
>
>
1. --create-hive-table 建表,如果表已经存在,该操作会报错!
2. 自动建立的表是 TextFile 格式的
3. 将数据临时放到执行sqoop的用户目录下/user/dubhe/xxxTableName(执行成功后数据会自动删除)
4. 将数据load到 新建立的TextFile 目标表
>
> 目标表不存在 mysql2hive code
>
>
>
– 推送时新建目标表
sqoop import -Dhadoop.security.credential.provider.path=jceks://hdfs/user/dubhe/passwd/fw4.pwd.jceks -Dsqoop.export.records.per.statement=10000 -Dorg.apache.sqoop.splitter.allow_text_splitter=ture --connect jdbc:mysql://10.8.66.95:3306/dpdb --username qry --password-alias fw4.pwd.alias --table fw_autoclaim_medical_cq --hive-import --hive-database dm_mart_sn --hive-table fw_autoclaim_medical_cq_temp --create-hive-table --fields-terminated-by ‘\t’ --hive-overwrite --num-mappers 1 --null-string “\\N” --null-non-string “\\N”
##### A2. 目标表已存在
1. 会先链接mysql跑一个map,将数据publishing hive/Hcat import job data to Listeners for table xxxx;
2. 将数据上传到HDFS的路径:/user/dubhe/xxxTableName(即使任务失败了后续不会自动删除)
3. 也会创建一个目标表名的textfile的格式的表;
4. connected to hiveMetaStore; Semantic Analysis;
5. compiling command(queryId);
6. lock;
7. connect to zookeeper to execute creat table;
8. load data inpath 'hafs://nameservice1/user/dubhe/fwxxx\_cp' overwrite into table database.targetTable;
9. SemanticException: Unable to load data to destination table, Error: the file that you are trying to load does not match the file format of the destination table;
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
到真正的技术提升。**
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)
[外链图片转存中…(img-Z7KOetzb-1713327098627)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









