








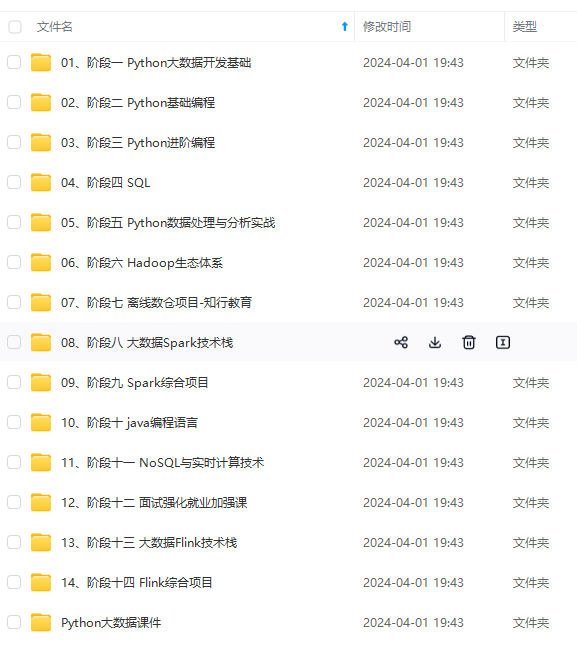
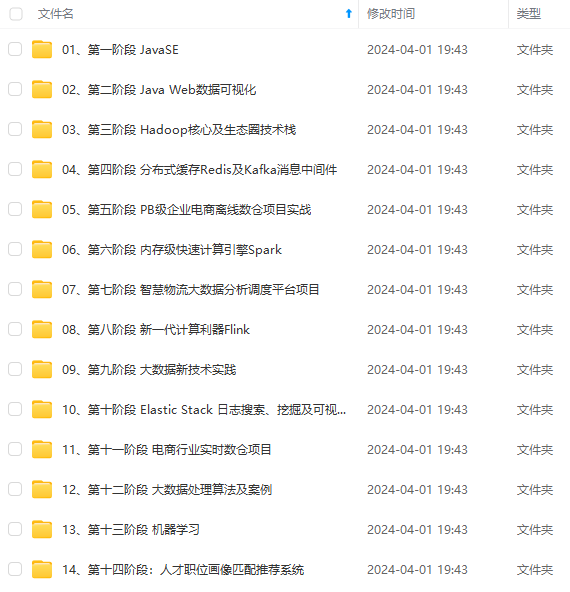
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
select max (consecutive_day)
from (select count(\*) (consecutive_day
from (select sum(rise_mark) over(order by trade_date) days_no_gain
from (select trade_date,
case when closing_price>lag(closing_price) over(order by trade_date)
then 0 else 1 END rise_mark
from stock_price ) )
group by days_no_gain)
这个语句的工作原理就不解释了,反正有点绕,同学们可以自己尝试一下。
这是润乾公司的招聘考题,通过率不足20%;因为太难,后来被改成另一种方式:把SQL语句写出来让应聘者解释它在算什么,通过率依然不高。
这说明什么?说明情况稍有复杂,SQL就变得即难懂又难写!
再看跑得快的问题,还是一个经常拿出来的简单例子:1亿条数据中取前10名。这个任务用SQL写出来并不复杂:
SELECT TOP 10 x FROM T ORDER BY x DESC
但是,这个语句对应的执行逻辑是先对所有数据进行大排序,然后再取出前10个,后面的不要了。大家知道,排序是一个很慢的动作,会多次遍历数据,如果数据量大到内存装不下,那还需要外存做缓
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1898
1898











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









