








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
🤵♂️ 个人主页:@Lingxw_w的个人主页
✍🏻作者简介:计算机科学与技术研究生在读
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
一、方差和偏差
在统计学习中我们通常会使用方差和偏差来衡量一个模型,
- 偏差:训练到的模型与真实模型之间的区别(图中蓝点与加号之间的距离);
- 方差:每次学习的模型之间差别有多大;

图中【中间的加号指的是我们要学的真实模型的地方,圆圈是可容忍的区域,蓝色的圆指的是训练的模型得出的结果,蓝色的点的个数代表了所训练模型的个数】
- 如果所有训练的模型都在大圆内 且 与加号离得很近的话,我们可以认为模型有低偏差和低方差;
- 如果所有训练的模型没有在大圆内,那么可以说它的偏差很大;但是每一个蓝点之间差别没有那么大,就表示说方差是比较小的;
- 虽然每个蓝点基本都落到了大圆中,但是每个蓝点的距离比较大;这样偏差比较低,但是方差很大;
- 最差的一个情况是:每个蓝点既不落在大圆内且每次训练的不一样(之间的距离很大);即方差和偏差都是很大的
我们需要的是低偏差和低方差,这样会是比较好的模型,若出现其他三种情况的话,要考虑用其他方法使得方差和偏差都降低。
数学定义
假设每次采样都是从有噪声ε的函数f(x)中采样数据用于学习f_hat
通过学习使得f_hat与 真实的f 尽可能的相近(这是个回归问题可以用最小MSE(均方误差)来实现)
我们学习到之后需要通过 泛化误差 来衡量它;在统计学习中,我们想通过学习来使得模型能泛化到没有学习过的样本,所以我们需要优先优化 [y-f(x)_hat]^2 的期望值 = 偏差^2 + 方差 +噪声^2

对公式的解释

- 刚开始模型过于简单可能学不到真实数据所要表达的内容,这时的偏差的平方会很大,随着模型的逐渐复杂,模型可能可以学到所想表达的信息,所以偏差的平方逐渐变小;
- 随着模型变得越来越复杂,能够拟合的东西就越大,这样模型可能会过多的关注于噪音(数据还是那些数据 数据复杂度低),所以方差会变得越来越大;
- 泛化误差 = 数据本身的噪音,但是数据本身没有变化,应该是个常数;但是加上了偏差和方差,最后就会导致最后的泛化误差曲线就会跟图中的蓝线一样
- 跟之前讲过的下图有关。
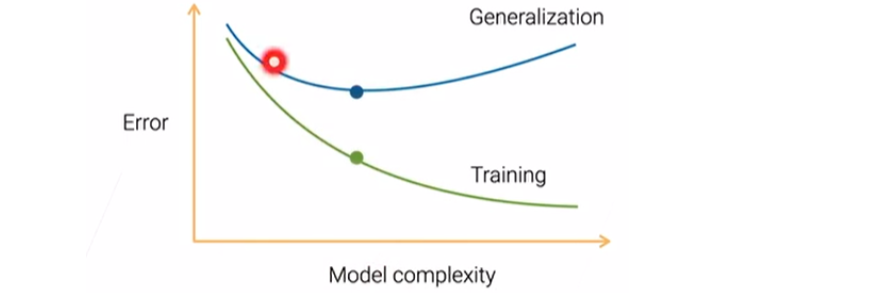
训练误差往往会跟偏差相关(偏差越小,模型就越容易拟合到数据上);图上两条线的差距可以说是方差在起作用。
减小偏差、方差、噪声
- 任务是减小泛化误差,那我们需要减小偏差、方差、噪声
- 减小偏差:偏差很大,说明模型复杂度可能不够,可以使用一个模型复杂度高一点的模型(在神经网络中可以 增加层数 增加隐藏层单元个数(宽度));也可使用【Boosting;Stacking】
- 减小方差:方差太大可能代表你的模型过于复杂,我们可以是用一个简单点的模型,或者是使用正则化(使用L2,L1正则项,限制住每个模型能够学习的范围);也可使用【Bagging;Stacking】
- 降低噪声:在统计学习中,这个是不可以降低的误差,但是在真实的场景,这是来自于数据采集,可以通过更精确的数据采集,更干净的数据来使得噪声降低
- 集成学习:使用多个模型来提升性能【上面提到的Boosting;Stacking;Bagging; 后面的小节会说】
总结
- 在统计学习中,我们可以把泛化误差分解为 偏差、误差和噪声三项;
- 集成学习能够将多个模型组合起来来降低偏差和。
二、Bagging
做bagging的时候,每次训练n个模型(base learners),但是每个模型都是独立并行训练的,在得到n个模型之后,
- 如果是回归问题,会把每一个模型的输出做平均就得到了bagging出来的效果
- 如果是做分类的话,这样每一个模型都会输出一个类别,然后会用这些输出做投票选最多的(这个叫Majority voting)
每个模型的训练是通过bootstrap采样得到的训练集上训练的
- 什么是bootstrap采样?假设训练集有m个样本,每一次训练base learner的时候,随机采样m个样本,每次采样我们会将这个样本放回去,可能有些样本会重复,如果有n个模型要这样训练,就重复n次
- 大概是有1-1/e ≈63%的概率会被采样到,就是说可能有37%的样本是没有采样出来的,可以用这个来做验证集,这个也叫做 out of bag。
代码实现
随机森林使用决策树来做base learner;
使用随机森林时的常用技术,在bootstrap样本时还会每次随机采样一些特征出来,但在这个地方就不会去采样重复的类出来,因为重复的类没有太大的意义;这样做主要的好处是随机采样之后可以避免一定的过拟合,而且能够增加每一棵决策树之间的差异性;
在右边的曲线图中,我们可以知道,随着learner的数量增加,模型的误差是逐渐减小的。但是泛化误差的曲线不会往上升,这是因为我们降低了方差但没使得偏差更大,这也就改善了泛化误差中三项其中的一项,但没增加另外两项。
class Bagging:
def __init__(self, base_learner, n_learners):
self.learners = [clone(base_learner) for _ in range(n_learners)]
def fit(self, X, y):
for learner in self.learners:
examples = np.random.choice(
np.arange(len(X)), int(len(X)), replace=True)
learner.fit(X.iloc[examples, :], y.iloc[examples])
def predict(self, X):
preds = [learner.predict(X) for learner in self.learners]
return np.array(preds).mean(axis=0)
bagging什么时候会变好
bagging主要下降的是方差,在统计上采样1次和采样n次取平均,它的均值是不会发生变化的就bias是不会发生变化的,唯一下降的是方差,采样的越多,方差相对来说变得越小。
方差什么时候下降的比较快,方差比较大的时候下降的相关比较好。
那什么时候方差大呢,方差比较大的模型我们叫做unstable的模型;以回归来举例子,真实的是f ,base learner是h,bagging之后 对每个学到的base learner的预测值取个均值 就会得到预测值f_hat;因为期望的平方会小于方差,所以h(x)与f(x)差别很大的时候,bagging的效果比较好。
也就是说,在base learner没那么稳定的时候,它对于下降方差的效果会好。
不稳定的learner
决策树不是一个稳定的learner,因为数据一旦发生变化,选取的特征然后选取特征的哪个值都会不一样,分支会不一样,故其不稳定;
线性回归比较稳定,数据的较小的变化,对模型不会有太大的影响 。
总结
bagging就是训练多个模型,每个模型就是通过在训练数据中通过bootstrap采样训练而来;

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
444359286)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 2034
2034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









