








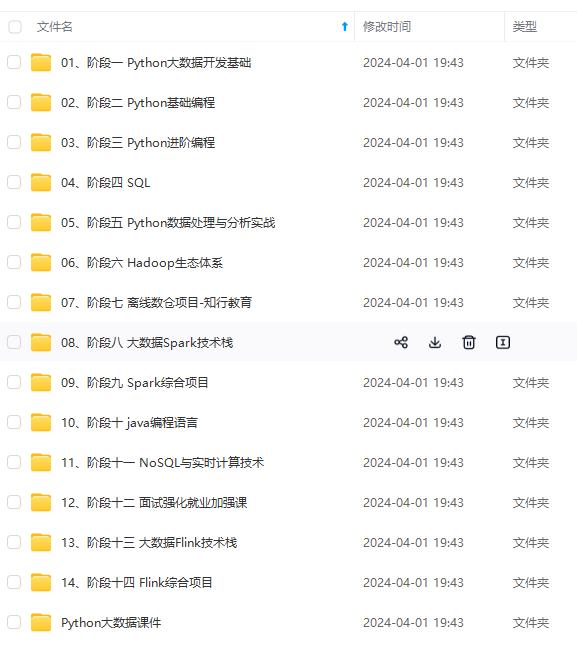
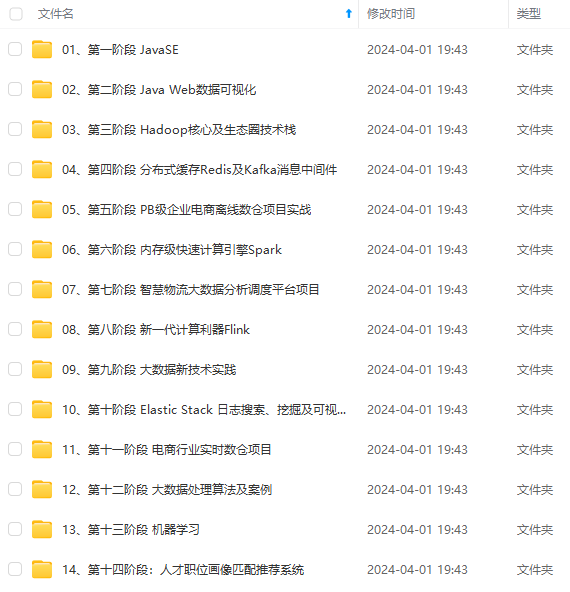
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
定义:通过观察某一数据周围的值来光滑有序数据的值,按照取值的不同划分可分为按箱平均值平滑、按箱中值平滑、以及按箱边界值平滑
4.2.回归
定义:利用某一拟合函数(如回归函数)来光滑数据
4.3.聚类
通过聚类分析检测出离群点。将类似的值组织成群或簇,落在簇之外的点就是离群点
5.数据集成要考虑的问题有哪些?
数据集成要考虑的问题有四个,分别是模式集成和对象匹配问题、冗余问题、元组重复问题、数据值冲突的检测与处理问题
6.数据变换主要涉及哪些内容?
数据变换主要涉及的内容包括有光滑。聚集、数据泛化、规范化、属性构造
三.数据挖掘
======
1.数据挖掘的概念
数据挖掘(DM)是从大量的、有噪声的、不完全的、模糊和随机的数据中,提取出隐含在其中的具有潜在价值的信息的过程。知识发现(KDD)包含数据挖掘(DM)
2.数据挖掘常用算法
数据挖掘常用方法有分类、聚类、关联规则、时间序列预测等
-
分类:分类是在给定数据基础上构建分类函数或分类模型,目的是将未知类别规类为给定类别种的某一类
-
聚类:聚类是将抽象对象的集合分为相似对象组成的多个类的过程,聚类过程生成的簇称为一组对象的集合,
-
关联规则:关联规则是信任度与支持度分别满足用户给定阈值的规则
-
时间序列预测:时间序列是将统计指标的数值按时间顺序排列所形成的数列。时间序列预测是将时间数列所反映的事件发展过程进行引申外推,预测发展趋势的一种方法。
3.分类
分类过程为学习和分类。第一步是建立模型,第二部根据模型进行分类。
3.1K最近邻算法
K最近邻算法的思想是:如果一个样本在特征空间的k个最相似样本中的大多数属于某一类别,则该样本属于该类别

3.2决策树
略
3.3贝叶斯分类
- 贝叶斯定理:P(A|B)=P(A) * P(B|A) / P(B)

根据贝叶斯定理


- 朴素贝叶斯定理:P(A1A2…An|C)*P©=P(A1|C)*P(A2|C)…*P(An|C)*P©, 朴素贝叶斯分类器是假设所有特征都彼此独立


3.4SVM(支持向量机算法)
超平面、超曲面、、、略
4.聚类
4.1聚类与分类的区别
分类:分类模型中存在的数据的是已经分类好的,分类的目的是从训练样本集中提取出分类的规则,用于对未知类别的数据进行归类
聚类:预先不知道目标数据有关类的信息,需要以某种度量为标准,将所有数据划分到各个簇中,因此聚类称为无监督学习
4.2聚类过程
数据准备——>特征选择——>特征提取——>聚类
4.3层次聚类算法
层次聚类算法的思想是对给定待聚类数据集合进行层次划分解,典型算法有BIRCH算法.
BIRCH算法:


4.4划分聚类算法
划分聚类思想是将给定的数据集分裂为k个簇,然后反复迭代到每个簇不再改变即得出聚类结果
4.4.1K-means****算法(K均值算法)

4.5****基于密度的聚类算法
层次聚类和划分聚类都以距离为基础,而密度聚类算法思想是只要邻近区域的数据点数目超过某个阈值就把它加到与之相近的聚类中
4.5.1DBSCAN****算法
名词概念:
邻域(Eps):以给定对象为圆心,半径内的区域为该对象的邻域
核心对象:对象的邻域内至少有MinPts(设定的阈值)个对象,则该对象为核心对象
边界对象:对象的领域小于MinPts个对象,但是在某个核心对象的邻近域中
离群点(噪声):对象的领域小于MinPts个对象,且不在某个核心对象的邻域中
直接密度可达:如果a是核心对象,b在a的邻域内,则a到b是直接密度可达
密度可达:a到b是直接密度可达,b到c是直接密度可达,则a到c是密度可达
密度相连:a到b是密度可达,a到c也是密度可达,则b到c是密度相连的
算法步骤:
1.输入两个参数:邻域半径(Eps),邻域密度阈值(MinPts)
2.找一个未访问的点
3.如果该点是核心点,访问所有从该点密度可达的点,形成一个簇
4.如果该点是边界点,跳出循环,寻找下一个点
详细讲解和例题可以看我另外一篇文章
聚类算法——基于密度的聚类算法DBSCAN_转行卖煎饼的博客-CSDN博客
5.关联规则
5.1 关联规则概念
关联规则挖掘指从数据集中识别出频繁出现的属性值集(频繁项集),然后利用频繁项集创建描述关联关系的规则的过程
5.2关联规则的名词解释
项集:数据库中的数据项构成的非空集合
事务:一个事务包含了一个或多个项集
支持度:包含项集x的事务数量与全部事务数量的百分比
置信度:同时包含数据项x和数据项y的事务数量与事务x(或事务y)出现的次数之比
最小支持度与最小置信度:关联规则必须满足的最低要求,由用户设定
频繁项集:大于等于最小支持度的项集称为频繁项集
最大频繁项集:不被其它频繁项集包含的频繁项集称为最大频繁项集
强关联规则:大于等于最小支持度和最小置信度称为强关联规则(频繁项集的基础上大于等于最小置信度)
5.3Apriori算法
Apriori是基于广度优先的关联规则算法,即从频繁1项集开始,采用频繁_k_项集搜索频繁_k_+1项集,直到不能找到包含更多项的频繁项集为止。
详细讲解和例题可以看我另外一篇文章
关联规则算法——Apriori算法_转行卖煎饼的博客-CSDN博客
5.4FP-Growth算法
FP-Growth不会产生候选项集,它采用分而治之的基本思想,将数据库中的频繁项集压缩到一棵频繁模式树中,同时保持项集之间的关联关系。然后将这棵压缩后的频繁模式树分成一些条件子树,每个条件子树对应一个频繁项,从而获得频繁项集,最后进行关联规则挖掘
详细讲解和例题可以看我另外一篇文章
关联规则算法——FP-Growth算法_转行卖煎饼的博客-CSDN博客
6.时间序列预测

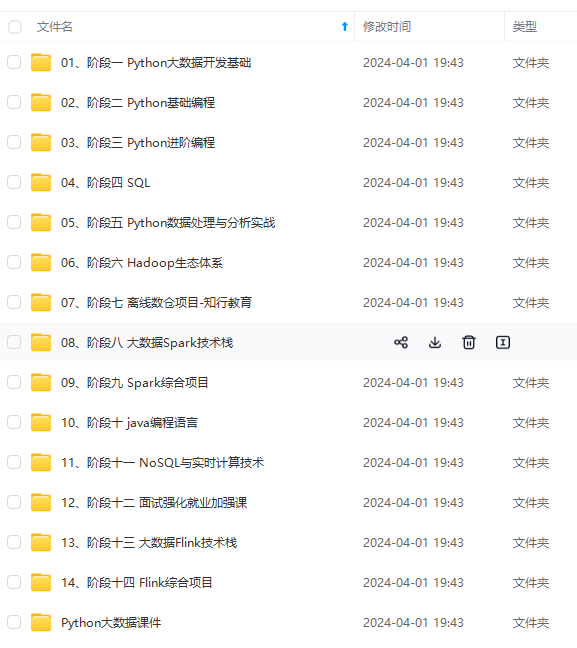
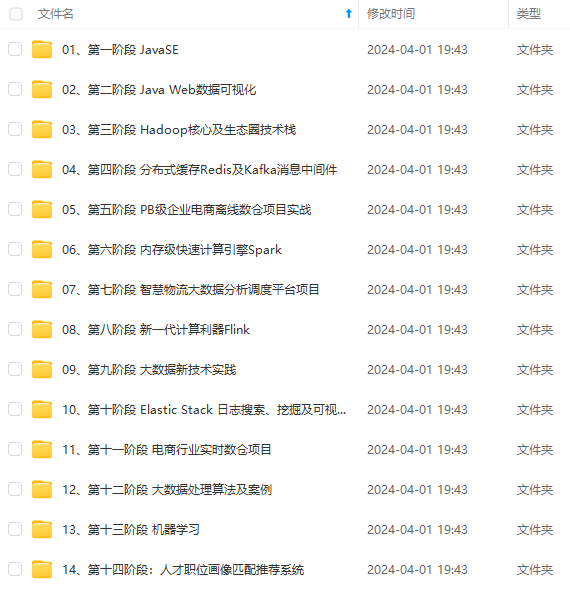
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
)
6.时间序列预测
[外链图片转存中…(img-IOwGZ0w7-1714917975872)]
[外链图片转存中…(img-cnCLB5EB-1714917975872)]
[外链图片转存中…(img-Z0w5RSrL-1714917975873)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1978
1978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









