








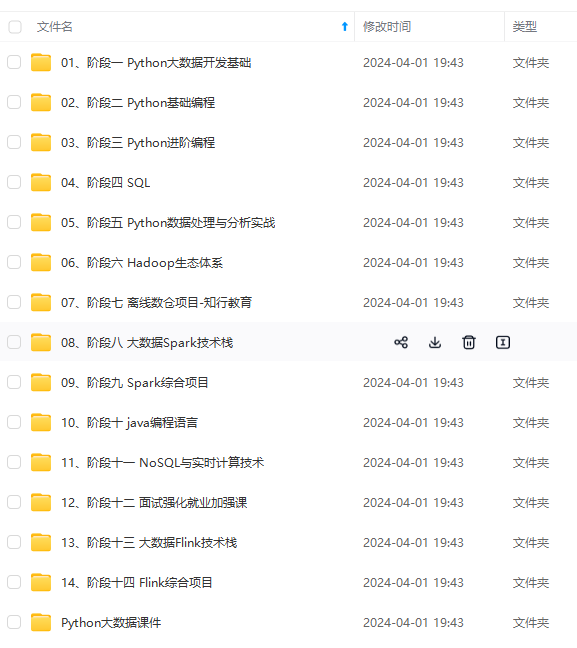
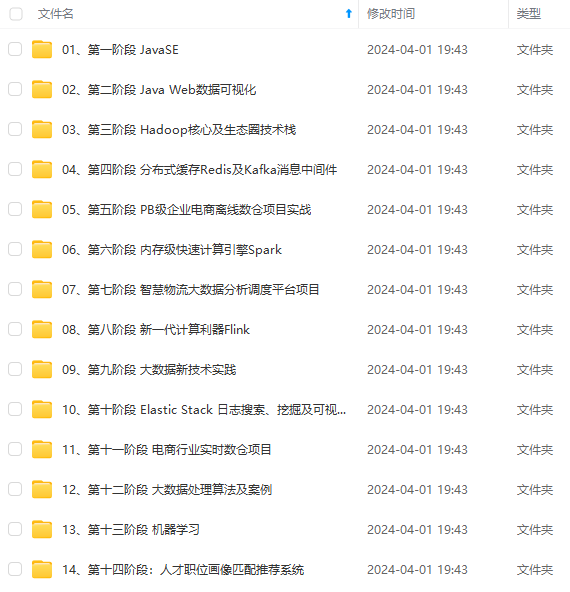
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
✍个人博客:https://blog.csdn.net/Newin2020?spm=1011.2415.3001.5343
📣专栏定位:为学习吴恩达机器学习视频的同学提供的随堂笔记。
📚专栏简介:在这个专栏,我将整理吴恩达机器学习视频的所有内容的笔记,方便大家参考学习。
💡专栏地址:https://blog.csdn.net/Newin2020/article/details/128125806
📝视频地址:吴恩达机器学习系列课程
❤️如果有收获的话,欢迎点赞👍收藏📁,您的支持就是我创作的最大动力💪
十六、应用实例:图片文字识别
1. 问题描述和流程图
我们希望可以通过扫描图片从提取关键字,这样当我们输入关键字时机器就能帮我们正确找到对应的照片,而不用我们煞费心思去找一些图片,接下来我们就来讲讲**照片OCR流水线(pipeline)**的处理。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1hkKbHLD-1670546701701)(吴恩达机器学习.assets/image-20211121185321954.png)]](https://img-blog.csdnimg.cn/a2e535bf30e743c08a3ddd5780b07b5e.png)
我们首先会对图片中含有文字的地方进行检测并提取出来,然后自动将其分割成不同字符并进行分类,正如下面流程图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YHAryDEP-1670546701705)(吴恩达机器学习.assets/image-20211121185841971.png)]](https://img-blog.csdnimg.cn/dbd530cefc0e42b99e585c3cd9645bc2.png)
2. 滑动窗口
在讲字符检测的具体方法之前,我们先看看是如何对行人进行检测的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-F60Cl9OQ-1670546701706)(吴恩达机器学习.assets/image-20211121190302565.png)]](https://img-blog.csdnimg.cn/d5d26b6e58a440a1a474ec509f930120.png)
比如我们会从数据集中收集一些82×36的照片即正负样本,其中有包含行人的即y=1,其中有不包括行人的即y=0,然后给机器学习,接下来我们就可以利用滑动窗口对图片进行检测了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OCf9GBDm-1670546701708)(吴恩达机器学习.assets/image-20211121190801196.png)]](https://img-blog.csdnimg.cn/d506dc712af1479d9c50190beb5f45eb.png)
我们会用一个82×36的窗口在图片上滑动,每次滑动的距离就是步长,每次会将窗口中的信息传递给分类器去判断是1还是0,对整张图片检测完后,会换一个更大的窗口再进行滑动检测。这里要注意的是,使用更大的窗口时,要将窗口中的图片转化成82×36的再传入分类器,这样就能找出所有行人了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pDqsrlrZ-1670546701710)(吴恩达机器学习.assets/image-20211121191113504.png)]](https://img-blog.csdnimg.cn/e07c47c5858b4d69b984f8279befcdd3.png)
所以,我们就可以用检测行人的方法,去检测字符。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HAnAunIM-1670546701711)(吴恩达机器学习.assets/image-20211121191236194.png)]](https://img-blog.csdnimg.cn/90a8d65e9afb49bbad3ff66f0d65e2f2.png)
我们同样从数据集中找一些正负样本,然后让机器进行学习。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vc9kJ17Q-1670546701716)(吴恩达机器学习.assets/image-20211121191659832.png)]](https://img-blog.csdnimg.cn/e7555f6a70a04f388693e100f1efa7eb.png)
我们在检测文字时同样也用到滑动窗口对图片进行扫描,然后得到上面黑白的图像,区域越白说明这个地方有字符的概率越大。最后在此基础上,使用放大算子,将有白色的地方周围一部分也变为白色,然后舍弃那些白色区域长宽比例与文字不配的地方,将没舍弃的地方框起来即可。接下来,我们再进行字符的分割。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SqsTlFvI-1670546701720)(吴恩达机器学习.assets/image-20211121192323391.png)]](https://img-blog.csdnimg.cn/35cf16df90634f52b0cef273faa5d199.png)
还是同样的方法,从数据集中收集正负样本让机器学习,然后在我们上面框出来的字符中再次进行扫描,将字符分割出来。要注意的是,这里的滑动窗口是一维的。
3. 获取大量数据和人工数据
我们前面知道,一个最可靠去得到高性能机器学习系统的方法是使用一个低偏差高方差的机器学习算法,并且使用庞大的数据集去训练它,但是我们要从哪得到这么多的数据呢,这就要引入人工数据合成概念了。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lBUWqWHS-1670546701721)(吴恩达机器学习.assets/image-20211121193228271-16374943488611.png)]](https://img-blog.csdnimg.cn/cb8cb63c002048448d5b4c448289b795.png)
其中一种方法是,网上有庞大的各种各样的字体库,然后可以从这些字体中剪切一小块字体出来,粘贴到不同的背景上,最终得到一个人工合成的数据集。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tgCZPZnG-1670546701723)(吴恩达机器学习.assets/image-20211121193620134.png)]](https://img-blog.csdnimg.cn/1f600ac40dc940e9b1d6eb515d93ff8d.png)

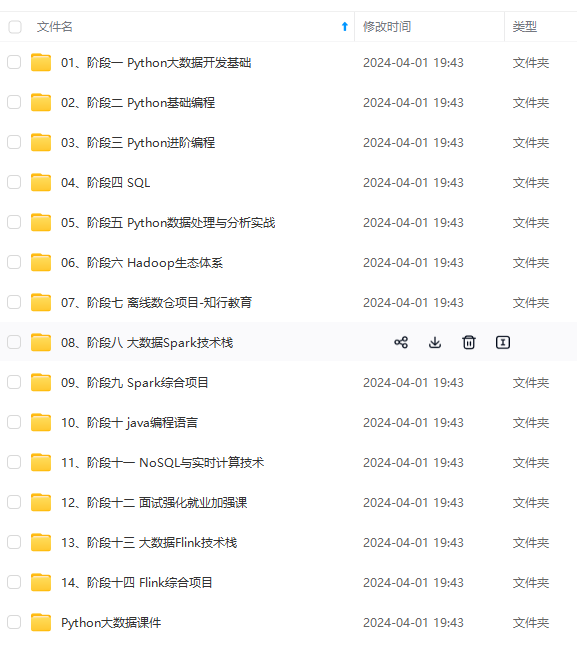
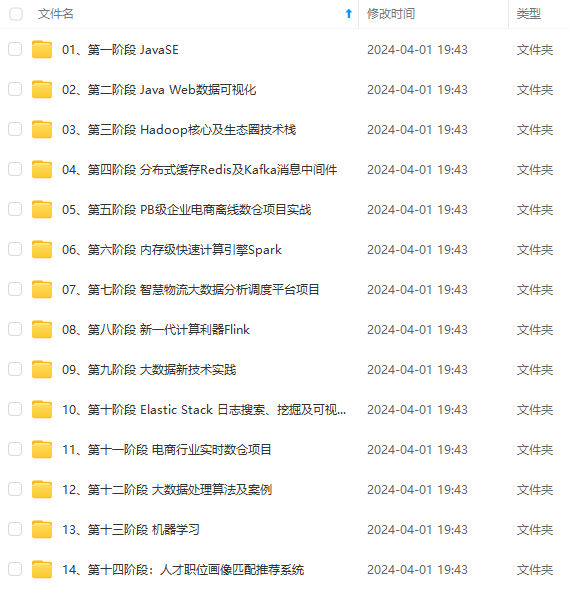
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
解视频,并且后续会持续更新**















 262
262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









