







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
么它很可能反映了这篇文章的特性,正是我们所需要的关键词
- 反文档频率 -IDF
• 在词频的基础上,赋予每一个词的权重,进一步体现该词的重要性,
• 最常见的词(“的”、“是”、“在”)给予最小的权重
• 较常见的词(“国内”、“中国”、“报道”)给予较小的权重
• 较少见的词(“养殖”、“维基”、“涨停”)较大权重
4.TF·IDF值越大 该词的越重要
反文档频率(IDF)= log( 语料库文档数/包含这个关键词的文档数+1)
应用:
- 相似文章
• 使用TF-IDF算法,找出两篇文章的关键词;
• 每篇文章各取出若干个关键词,合并成一个集合,计算每篇文章对于这个集合
中的词的词频;
• 生成两篇文章各自的词频向量;
• 计算两个向量的余弦相似度,值越大就表示越相似。
- 文章摘要

5.L C S 定 义
• 最长公共子序列(Longest Common Subsequence)
• 一个序列S任意删除若干个字符得到的新序列T,则T叫做S的子序列
• 两个序列X和Y的公共子序列中,长度最长的那个,定义为X和Y的最长公共子序
列
– 字符串12455与245576的最长公共子序列为2455
– 字符串acdfg与adfc的最长公共子序列为adf
• 注意区别最长公共子串(Longest Common Substring)
– 最长公共子串要求连接
L C S 作 用
• 求两个序列中最长的公共子序列算法
– 生物学家常利用该算法进行基因序列比对,以推测序列的结构、功能和演化过程。
• 描述两段文字之间的“相似度”
– 辨别抄袭,对一段文字进行修改之后,计算改动前后文字的最长公共子序列,将除此子序列
外的部分提取出来,该方法判断修改的部分
求 解 — — 暴力穷举法
• 假定字符串X,Y的长度分别为m,n;
• X的一个子序列即下标序列{1,2,……,m}严格递增子序列,因此,X共有2
m个
不同子序列;同理,Y有2
n个不同子序列;
• 穷举搜索法时间复杂度O(2
m ∗ 2
n
);
• 对X的每一个子序列,检查它是否也是Y的子序列,从而确定它是否为X和Y的公
共子序列,并且在检查过程中选出最长的公共子序列;

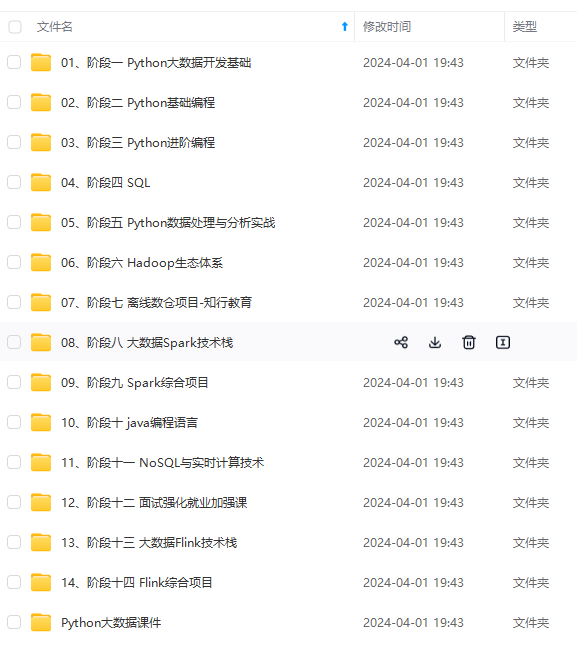
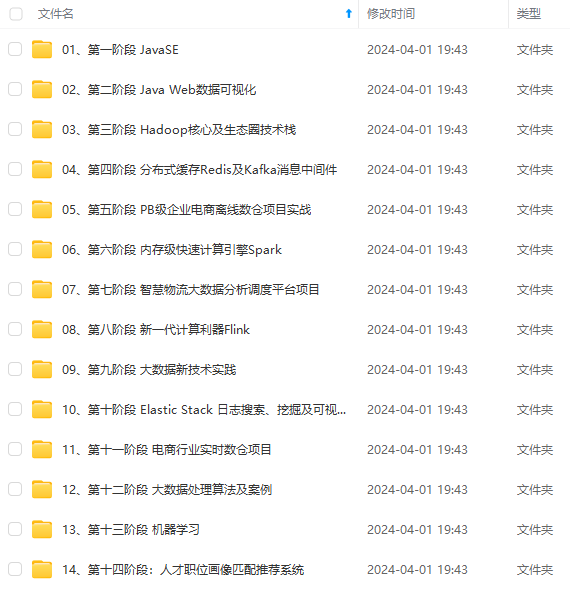
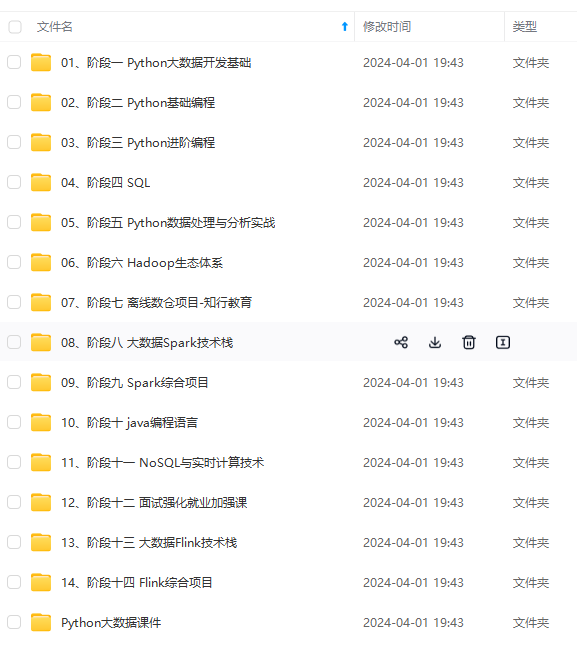
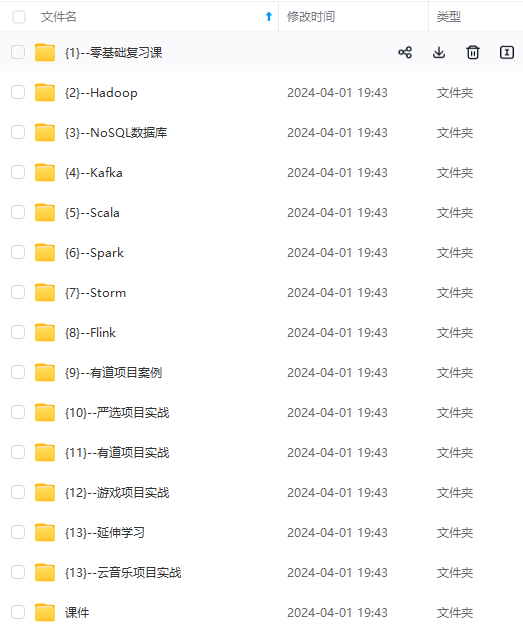
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新**















 5862
5862

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









