








网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
怎么做这个任务?
找到包含物体的区域,用一个多分类器进行物体分类
怎么知道哪些区域包含物体?
找到很多候选区域,用一个二分类器进行区域分。
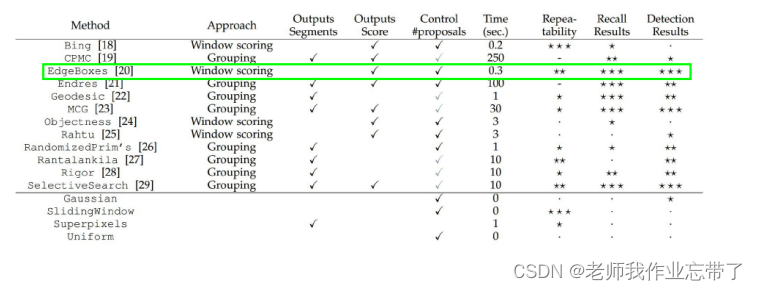
2.1 候选区域(Region Proposals)
指可能包含物体的区域、感兴趣区域 (Region of interest, ROI)。
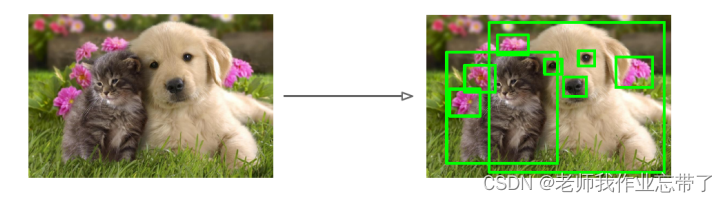
挑选候选区域的多种选择
2.1.1 (C+1)-类的分类
上面提到简单检测物体的思路:
- 找到很多候选区域,用一个二分类器进行区域分类。
- 找到包含物体的区域,用一个多分类器(Softmax、SVM等)进行物体分类。
另外一种方法:
- 设有C个类别,加一个“背景”类
- 对每个区域用一个多分类器进行(C+1)-类的分类
- 对每个区域用(C+1)个二分类器进行分类
2.1.2 R-CNN
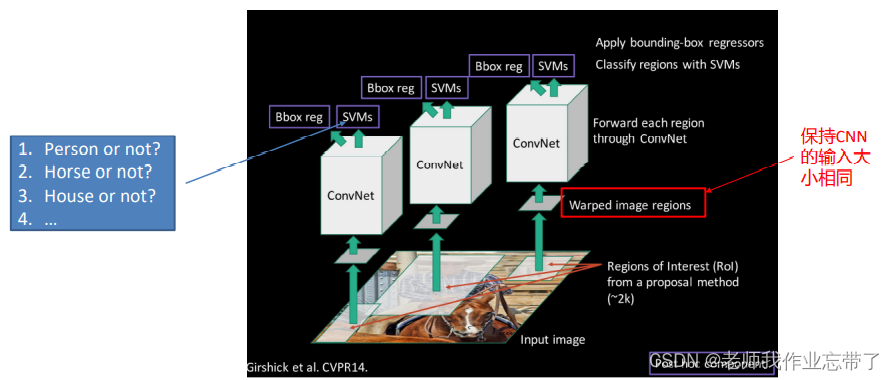
把每个候选框的图片剪贴出来,变成相同尺寸,经过一个同样的CNN进行一个二分类。这里用的上面提到的C+1类方法。SVM解决二分类问题。至于Bbox reg 用于解决回归问题,坐标定位。
步骤:
- 训练(或下载)ImageNet分类模型(如AlexNet)
- 针对检测微调(fine-tune)
- 提取特征
- 每个类别训练一个二分类SVM来为候选区域的特征进行分类
- 对每个类别,训练一个线性回归模型,将特征映射到一组偏移量,用以校正那些稍微有些误 差的候选区域

R-CNN有什么问题吗?
测试慢
- 需要对每个ROI跑一个完整的CNN前向过程。
非“端到端”过程
- 找候选区域, SVM和回归器基于CNN的特征进行处理。
- SVM和回归器不能更新CNN的特征。
更好的想法?
先在整张图上跑一个CNN的前向过程,然后将每个ROI映射到特征图上。
2.1.3 Fast R-CNN
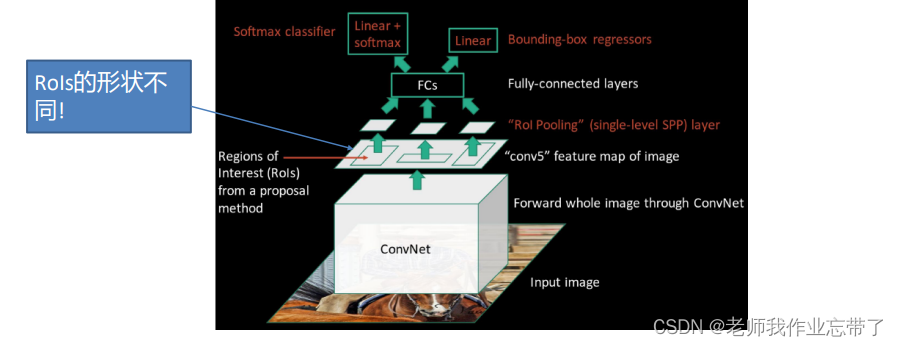
即先把整张图做一个神经网络,先把特征取好,想要什么特征就取什么特征。
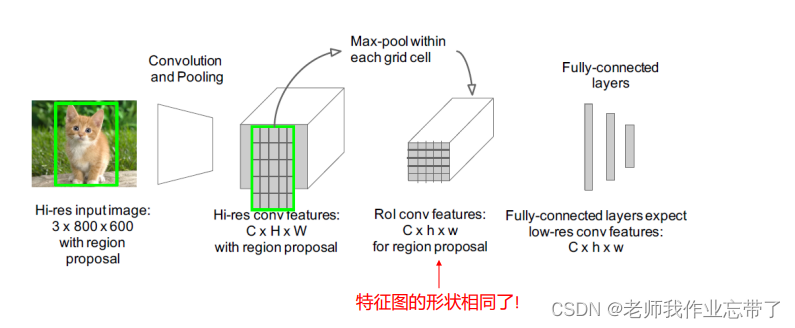
感兴趣区域池化(RoI Pooling)
可见上面提取的图片大小是不同的,这里做一下池化。
结果:
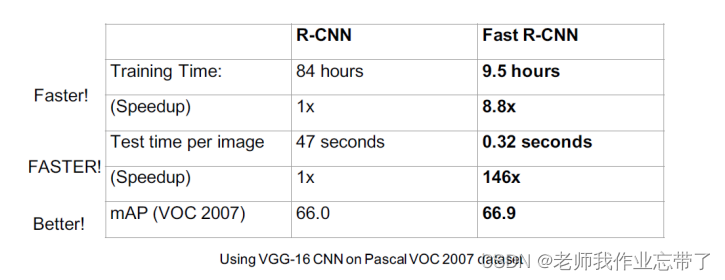
Fast R-CNN问题:
R-CNN和Fast R-CNN它们的那些“框”来自于计算机视觉上的一些方法,万一不准怎么办?
2.1.4 Faster R-CNN
在最后一个卷积层后插入候选区域网络(Region Proposal Network ,RPN)
RPN用来直接产生候选区域; 不需要额外的候选框。
RPN之后, 使用RoI Pooling以及分类 器、回归器,类似Fast R-CNN。
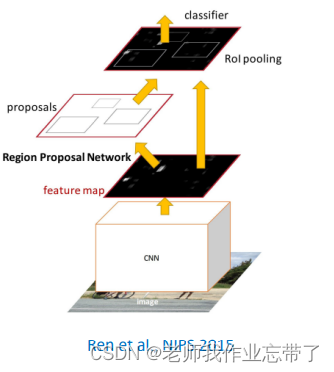
通过Fast R-CNN的一个神经网络得到feature map,在最后一个卷积层后插入了RPN,会输出一些ROI。用神经网络的特征预测哪些区域有误。前面的方法用其它方法预测候选区域不一定准,而且是在Deep Learing兴起之前的一些方法。
候选区域网络 (RPN)
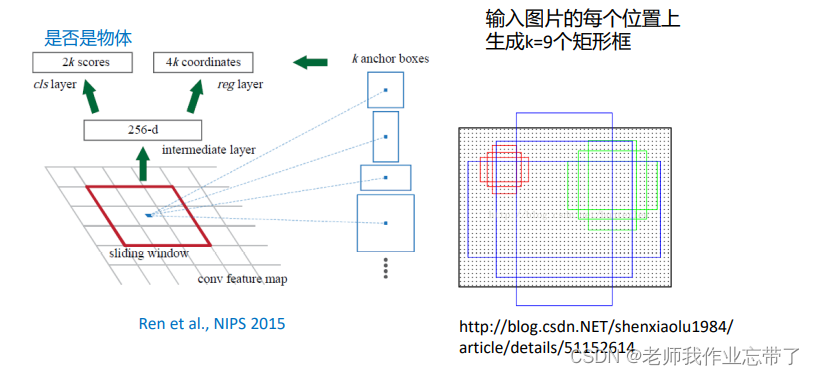
在feature map每个点上做两个预测,在每个点提出k个框(不同大小形状,k常设置为9,3种不同的形状*3种不同的大小如上右图),把这些框经过一个全连接层得到一个256维的向量去做两个任务1.识别物体(2分类,2k个) 2. 定位(4k个)。
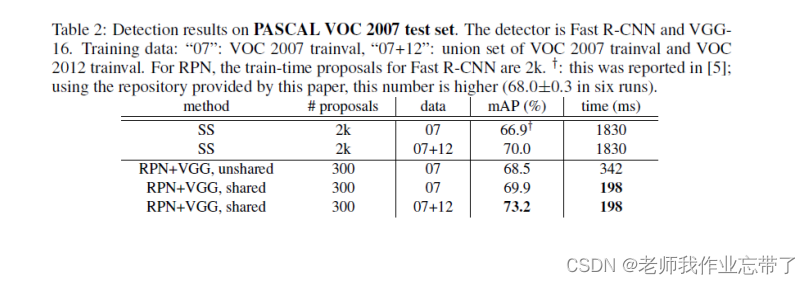
Faster R-CNN 结果
2.1.5 两阶段与单阶段

上面介绍的三个模型有一个共同点,需要一些候选框,再对每个候选框进行处理。我们把这一类的方法称之为:两阶段方法。
两阶段方法较慢,现在人们已经在研发更快的方法:单阶段模型,它不再去预测哪个框是更合适的,所以更快,但精度会有些问题。
单阶段如何实现呢?
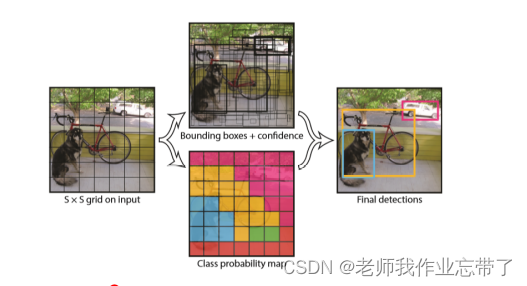
2.1.6 YOLO: You only look at once
将图像划分为S×S个网格;
每个网格预测B个矩形框, 每个框的置信度(与任意一个Ground truth框的IOU), 以及C个类别的概率。
这些预测结果可整合为大小为 S ×S ×(B ∗5 + C) 的张量
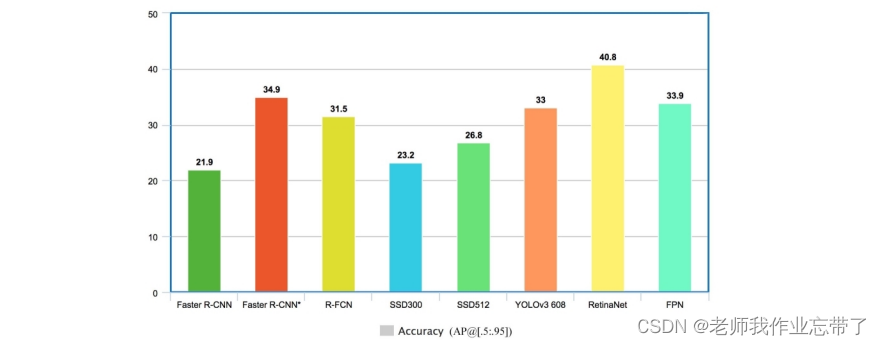
效果对比
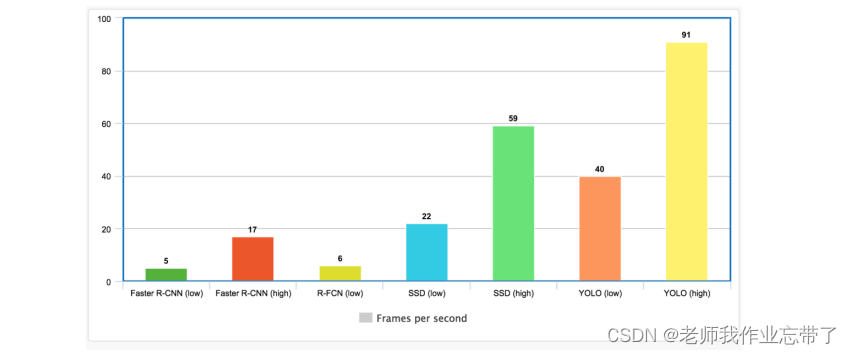
在日常生活中,特定的物体检测应用更加广泛一些

三、图像分割
给定一张图片,对每个像素进行分类。
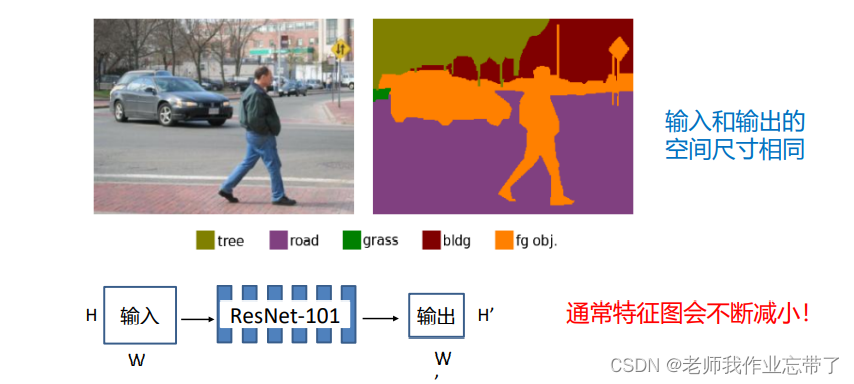
通常的一些卷积方法会使输出变小,所以我们就需要一些方法来增他特征图。
如何增大特征图?
- 上采样 (采样和插值)
- 对于一张输入图片,将其放大到指定尺寸,并用插值方法计算每个像素的值,例如双线性插值。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
67144386)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









