







文章目录
面试题01、 请说下Hive和数据库的区别
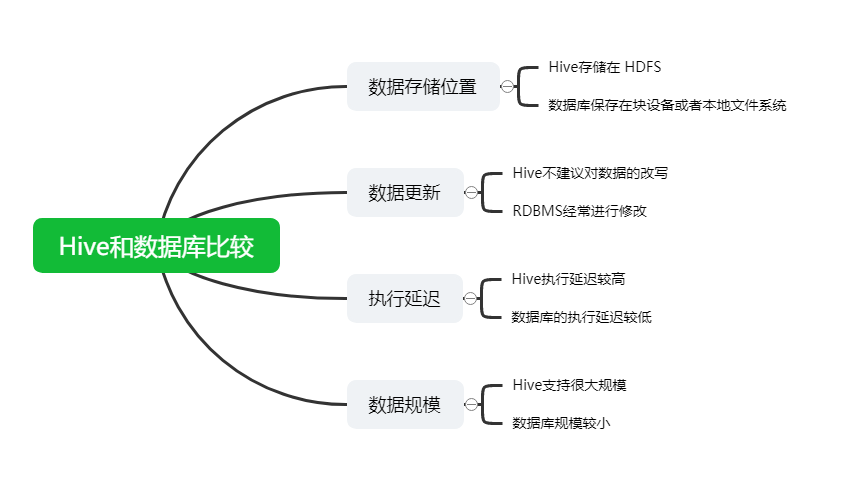
Hive 和数据库除了拥有类似的查询语言,再无类似之处。
1)数据存储位置
Hive 存储在 HDFS 。数据库将数据保存在块设备或者本地文件系统中。
2)数据更新
Hive中不建议对数据的改写。而数据库中的数据通常是需要经常进行修改的,
3)执行延迟
Hive 执行延迟较高。数据库的执行延迟较低。当然,这个是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
4)数据规模
Hive支持很大规模的数据计算;数据库可以支持的数据规模较小。
面试题02、 内部表和外部表
1)内部表又叫管理表:当我们删除一个管理表时,Hive也会删除这个表数据。管理表不适合和其他工具共享数据。
2)外部表:删除该表并不会删除掉原始数据,删除的是表的元数据
详答版:
未被 external 修饰的是内部表(managed table),被 external 修饰的为外部表 (external table)
区别:
内部表数据由 Hive 自身管理,外部表数据由 HDFS 管理;
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定(如果没有 LOCATION, Hive 将在HDFS上的/user/hive/warehouse 文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里);
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS 上的文件并不会被删除;

面试题03、Hive中order by,sort by,distribute by和cluster by的区别
Sort By:在同一个分区内排序
Order By:全局排序,只有一个Reducer;
Distrbute By:类似 MapReduce 中Partition,进行分区,一般结合sort by使用。
Cluster By:当 Distribute by 和 Sort by 字段相同时,可以使用Cluster by方式。
Cluster by 除了具有 Distribute by 的功能外还兼具 Sort by 的功能。但是只能升序排序,不能指定排序规则为ASC或者DESC。
面试题04、UDF、UDAF、UDTF的区别
当Hive自带的函数无法满足我们的业务处理需求时,hive允许我们自定义函数来满足需求。
根据自定义函数的类别分为以下三种:
UDF:User-Defined-Function,用户自定义函数,数据是一进一出,功能类似于大多数数学函数或者字符串处理函数;
UDAF:User-Defined Aggregation Function,用户自定义聚合函数,数据是多进一出,功能类似于 count/max/min;
UDTF:User-Defined Table-Generating Functions,用户自定义表生成函数,数据是一进多处,功能类似于lateral view explore();
面试题05、Rank排名函数
1.RANK() 排序相同时会重复,总数不会变;

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
大纲路线、讲解视频,并且后续会持续更新**















 314
314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









