








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

python是目前非常火爆的语言,其在人工智能、数据分析领域都占有一席之地,无论是学习还是工作,都会给你带来相当大的帮助。我在这给大家
推荐一个快速提升自己的网站👉👉
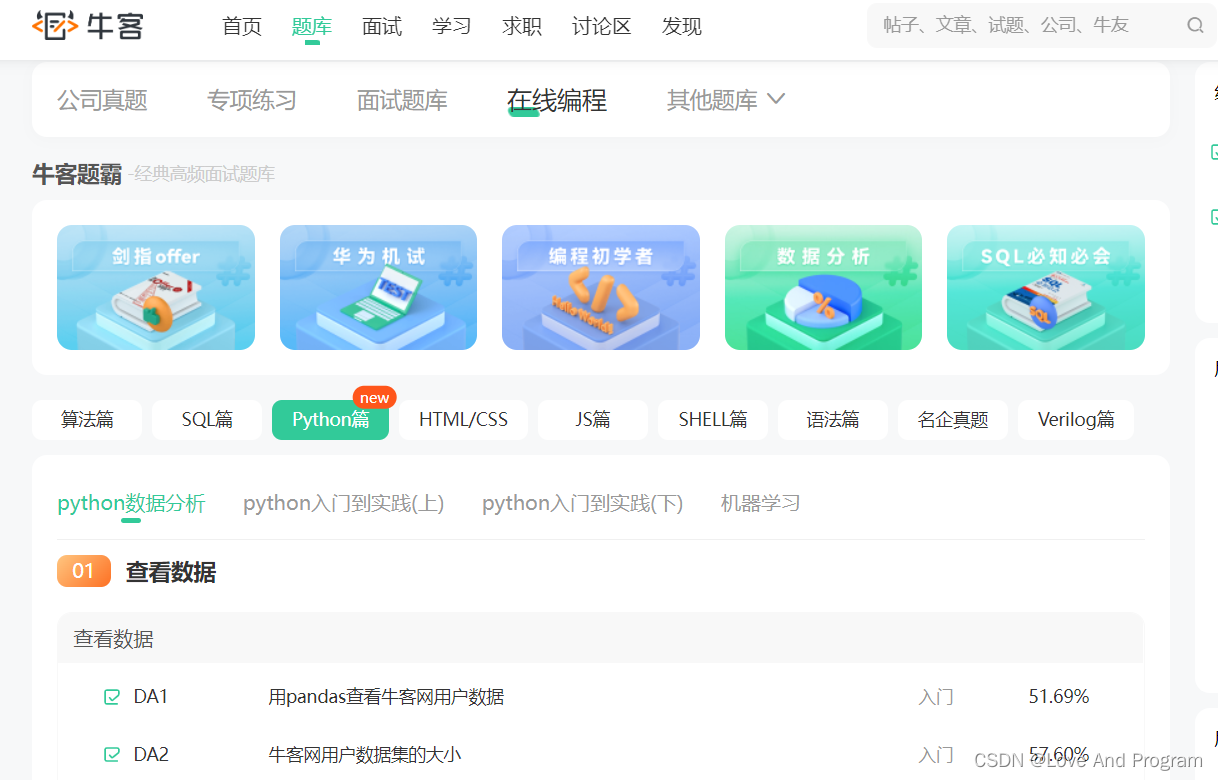
牛客网,他们现在的IT题库内容很丰富,属于国内做的很好的了,可以在下图中看见里面试题应有尽有,最最最重要的里面的资源全部免费!!!(亲测全免费,写题解还可以得小礼物)
欢迎大家订阅本专栏进行自助练习🥰🥰
系列专栏链接:
前言
逻辑运算 部分已经完结,相信大家对于csv、excel文件基本的查找操作已经熟练掌握了,接下来我们要学习的是 中级函数 部分,得,又需要记新的函数了,但是你要知道,Python作为你最值得信赖的工具,它是不会为难你的,总结起来就是好记,很好记,非常t喵d好记。
不同语言使用人数
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
刚刚发现牛客网想要学习编程的小白,不知道优先学习什么语言,刷什么题单,你能帮助他从这个csv文件中找到牛客网各种语言使用的用户分别有多少吗?

输出该数据集中满足筛选条件的全部信息,包括列号。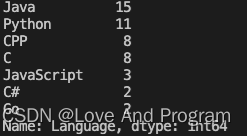
- 读题找出重点:找出语言种类
- 接下来我们学习三个将要用到的函数,分别是:
value_counts()、size()、count()
value_counts():The returned Series will have a MultiIndex with one level per input column. By default, rows that contain any NA values are omitted from the result. By default, the resulting Series will be in descending
order so that the first element is the most frequently-occurring row.
翻译过来是:返回的序列将具有一个多索引,每个输入列有一个级别。默认情况下,包含任何 NA 值的行将从结果中省略。默认情况下,生成的序列将降序排列顺序,因此第一个元素是最常出现的行。
总结一下:计算每列重复值个数,但是这个列取决于你用的数据,选取多列按一列计算,代码如下:
import numpy as np
import pandas as pd
data= pd.DataFrame({
"Nowcoder\_ID":[178372,989717,783650,723570,456568],
"Level":[7,1,2,6,7],
"Achievement\_value":[8711,13,130,5666,11234],
"Num\_of\_exercise":[500,3,32,433,899],
"Graduate\_year":[2017,2016,2010,2019,2017],
"Language":['CPP','Java','C','C','Python'],
})
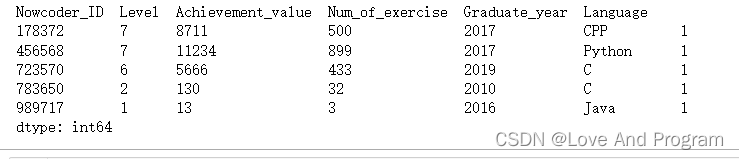
data.value_counts()
很明显,除非是两行数据一模一样,否则最右边统计个数只有一个,但是他也很人性化,若是遇见存在相同的数据会显示为空并放在一起,读者可以自行尝试
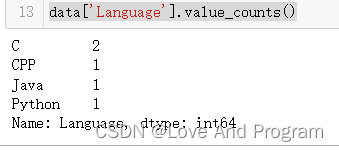
既然如此根据题目要求,我们选取特定一列即可完成任务:
data['Language'].value_counts()
count() : For each column/row the number of non-NA/null entries.
翻译:对于每列/行,非 NA/空条目的数量。
总结一下:直接用的话计算的是数量,单纯的数量!但是我们有一个分组函数groupby(),他们可以结合使用,于是答案就出来了。
在此之前,我先给大家稍微说一下什么是groupby()函数,一个小demo可以轻松理解:
import numpy as np
import pandas as pd
data= pd.DataFrame({
"Num\_of\_exercise":[500,3,32,433,899],
"Graduate\_year":[2017,2016,2010,2019,2017],
"Language":['CPP','Java','C','C','Python'],
})
data['Language'].value_counts()
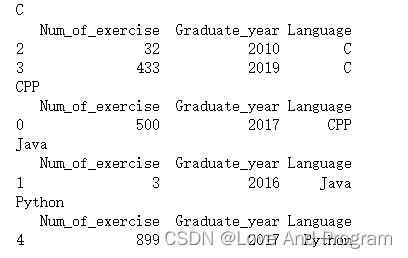
data1 = data.groupby('Language')
for name,group in data1:
print (name)
print (group)
以不通语言为一组,这就是分组后的内容,注意:groupby函数不能够直接显示具体内容,其代指<pandas.core.groupby.generic.DataFrameGroupBy object at 0x0000028EA26A2B20>,所以需要循环输出。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
csdn.net/forums/4f45ff00ff254613a03fab5e56a57acb)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1052
1052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









