







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
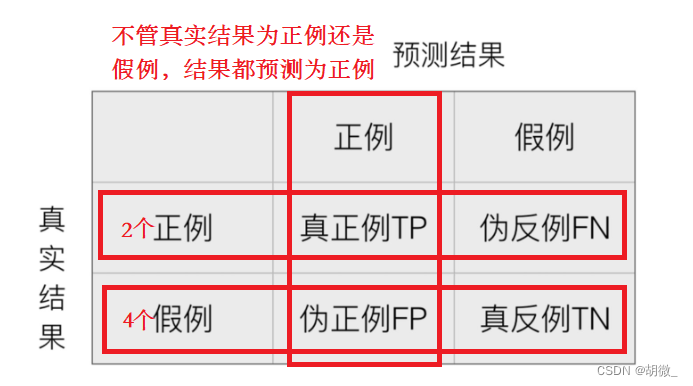
比如以这个癌症举例子!!!我们并不关注预测的准确率,而是关注在所有的样本当中,癌症患者有没有被全部预测(检测)出来。
4 分类评估方法
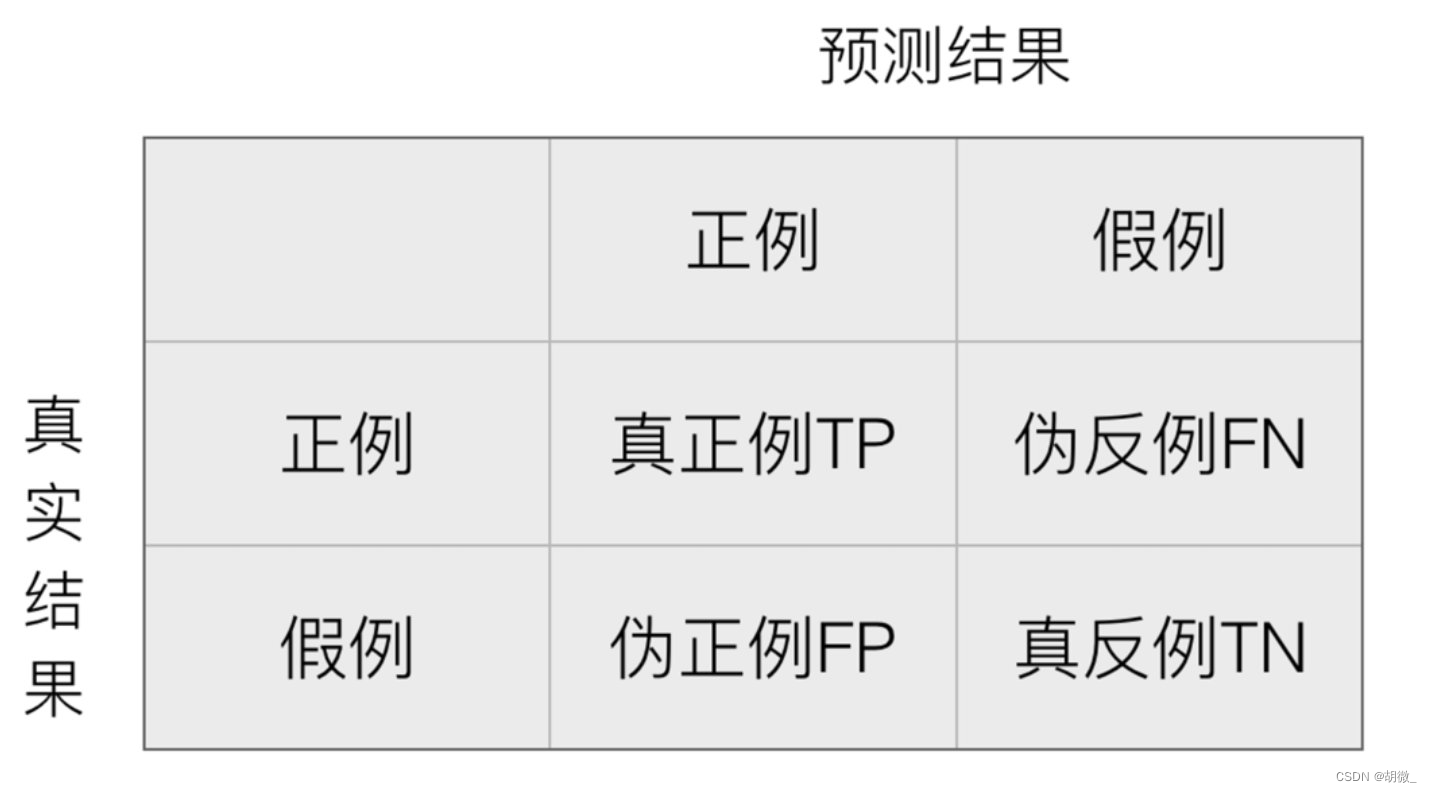
4.1 混淆矩阵
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)
-
准确率
- 预测正确的数占样本总数的比例
- (TP+TN) / (TP+FP+FN+TN)
-
精确率
- 预测结果为正例样本中真实为正例的比例
- TP/(TP+FP)

-
召回率
- 真实为正例的样本中预测结果为正例的比例(查得全,对正样本的区分能力)
- TP/(TP+FN)

-
F1-score:反映了模型的稳健型

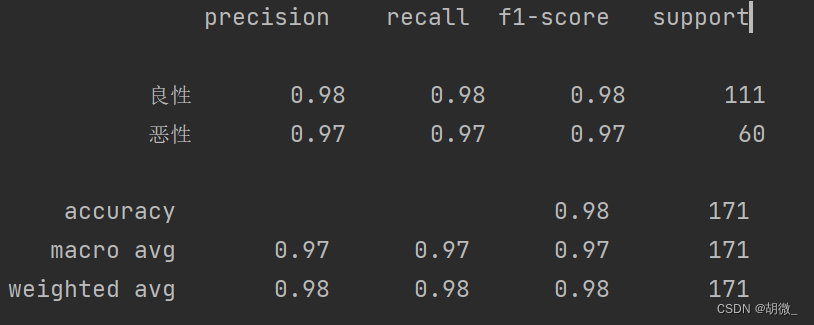
分类评估报告api
sklearn.metrics.classification_report(y_true, y_pred, labels=[], target_names=None )
- y_true:真实目标值
- y_pred:估计器预测目标值
- labels:指定类别对应的数字
- target_names:目标类别名称
- return:每个类别精确率与召回率
# ret = classification\_report(y\_test, y\_predict)
ret = classification_report(y_test, y_predict, labels=(2,4), target_names=("良性", "恶性")) # 索引2、4改成良性、恶性
print(ret)
假设这样一个情况,如果99个样本癌症,1个样本非癌症,不管怎样我全都预测正例(默认癌症为正例),准确率就为99%但是这样效果并不好,这就是样本不均衡下的评估问题
- 一般认为数据比例4比1则为不均衡
问题:如何衡量样本不均衡下的评估?
解答:AUC指标主要用于评估样本不均衡的二分类问题
4.2 ROC曲线与AUC指标
- TPR = TP / (TP + FN)
- 召回率
- 所有真实类别为1的样本中,预测类别为1的比例
- FPR = FP / (FP + TN)
- 所有真实类别为0的样本中,预测类别为1的比例
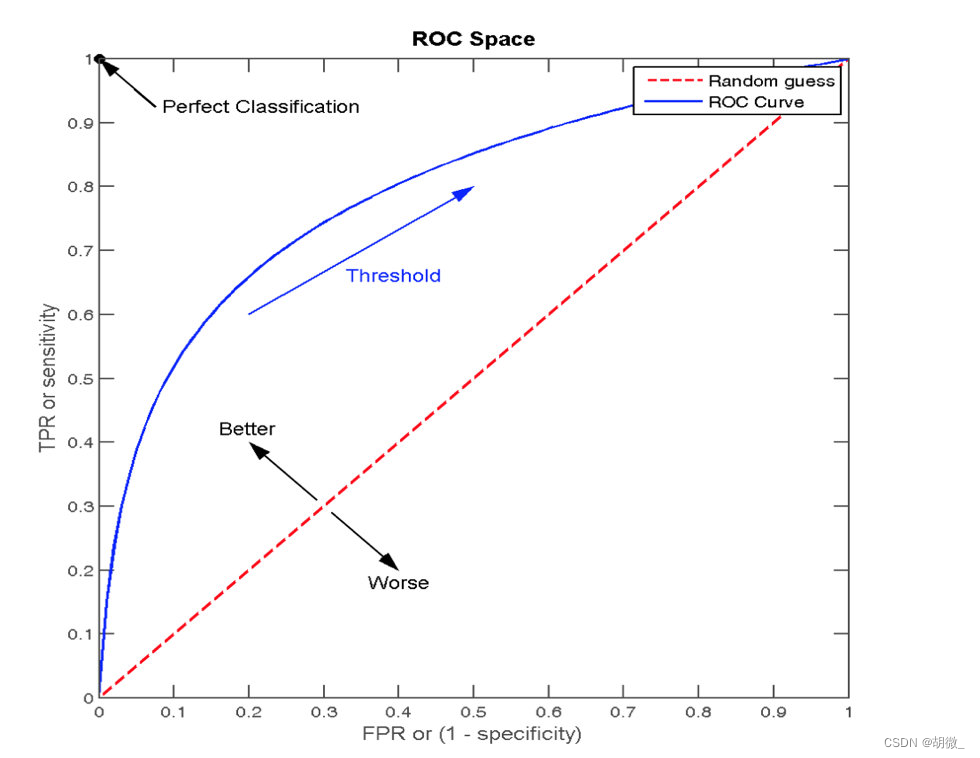
(1)ROC曲线
ROC曲线的横轴就是FPRate,纵轴就是TPRate,当二者相等时,表示的意义则是:对于不论真实类别是1还是0的样本,分类器预测为1的概率是相等的,此时AUC为0.5
(2)AUC指标
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。
- AUC的概率意义是随机取一对正负样本,正样本得分大于负样本得分的概率
- AUC的范围在 [0, 1] 之间,并且越接近1越好,越接近0.5属于乱猜
- AUC=1,完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5<AUC<1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC计算API
from sklearn.metrics import roc_auc_score
sklearn.metrics.roc_auc_score(y_true, y_predict)
- 计算ROC曲线面积,即AUC值
- y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
- y_predict:预测得分,可以是正类的估计概率、置信值或者分类器方法的返回值
# 0.5~1之间,越接近于1约好
y_test = np.where(y_test > 2.5, 1, 0) # 2是良性4是恶性,将目标值大于2.5的改为1,小于2.5的改为0
print("AUC指标:", roc_auc_score(y_test, y_predict) # 传入真实值、预测值
注意:
- AUC只能用来评价二分类
- AUC非常适合评价样本不平衡中的分类器性能
4.3 ROC曲线绘制
关于ROC曲线的绘制过程,通过以下举例进行说明
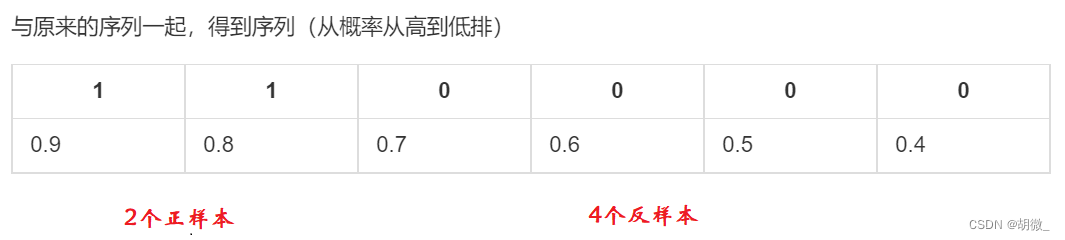
假设有6次展示记录,有两次被点击了,得到一个展示序列(1:1,2:0,3:1,4:0,5:0,6:0),前面的表示序号,后面的表示点击(1)或没有点击(0)。
然后在这6次展示的时候都通过model算出了点击的概率序列。
下面看三种情况。
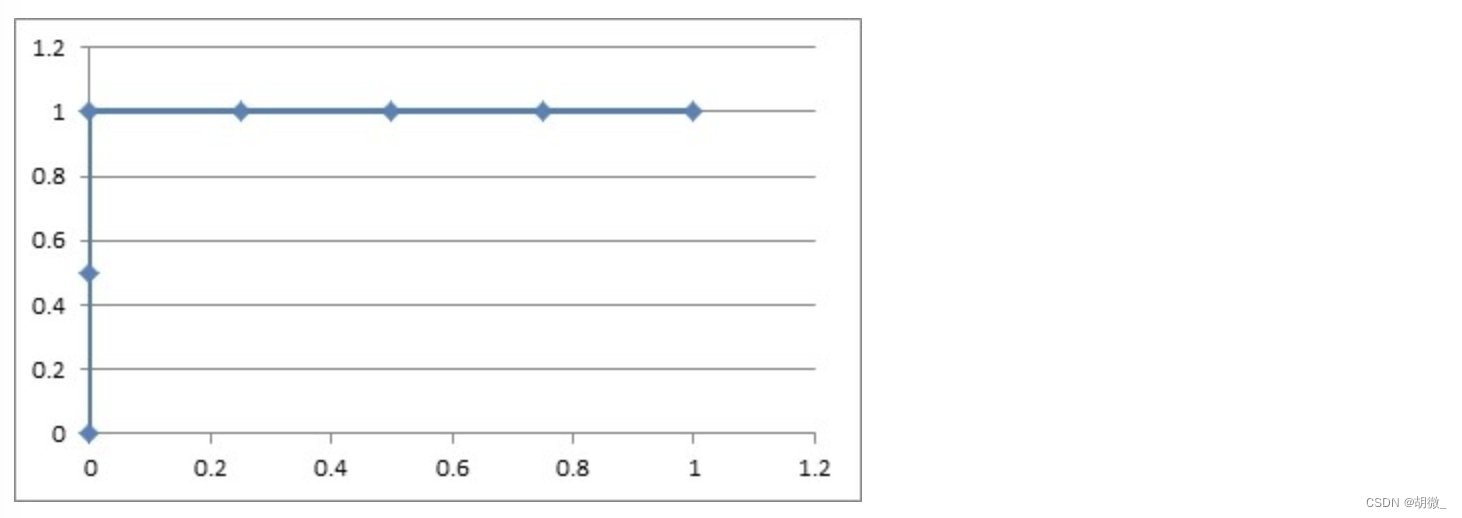
(1)如果概率的序列是(1:0.9,2:0.7,3:0.8,4:0.6,5:0.5,6:0.4)
TPR = TP/(TP+FN)
FPR = FP/(TN+FP)
绘制的步骤是:
- 把概率序列从高到低排序,得到顺序(1:0.9,3:0.8,2:0.7,4:0.6,5:0.5,6:0.4);
- 从概率最大开始取一个点作为正类,取到点1,计算得到TPR=0.5,FPR=0.0;
- 从概率最大开始,再取一个点作为正类,取到点3,计算得到TPR=1.0,FPR=0.0;
- 再从最大开始取一个点作为正类,取到点2,计算得到TPR=1.0,FPR=0.25;
- 以此类推,得到6对TPR和FPR。
然后把这6对数据组成6个点(0,0.5),(0,1.0),(0.25,1),(0.5,1),(0.75,1),(1.0,1.0)。
这6个点在二维坐标系中能绘出来。
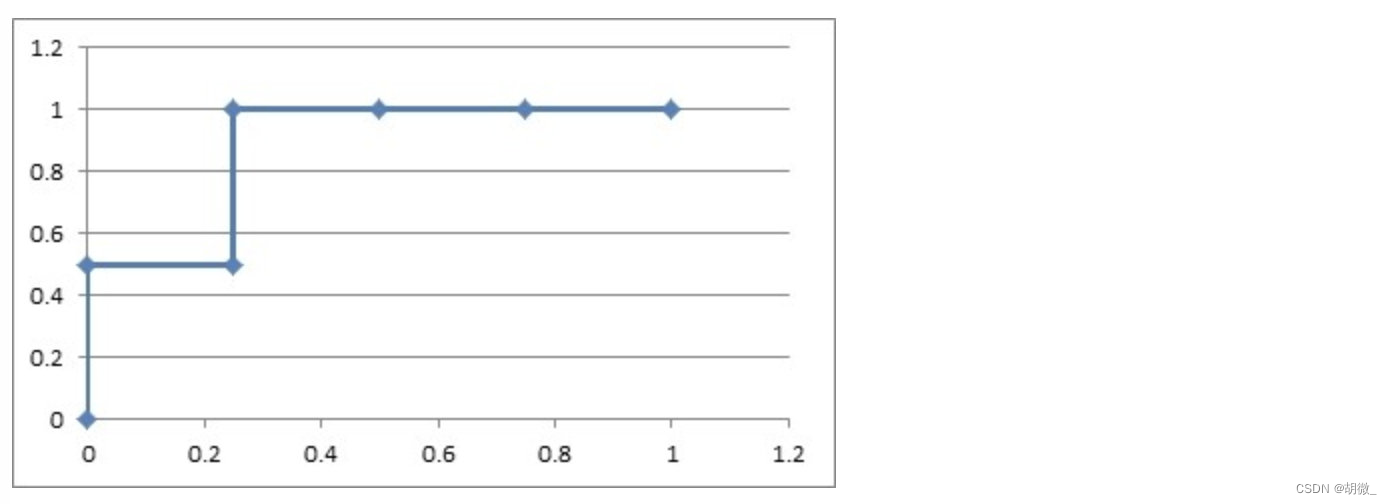
(2)如果概率的序列是(1:0.9,2:0.8,3:0.7,4:0.6,5:0.5,6:0.4)

绘制的步骤是:
- 把概率序列从高到低排序,得到顺序(1:0.9,2:0.8,3:0.7,4:0.6,5:0.5,6:0.4);
- 从概率最大开始取一个点作为正类,取到点1,计算得到TPR=0.5,FPR=0.0;
- 从概率最大开始,再取一个点作为正类,取到点2,计算得到TPR=0.5,FPR=0.25;
- 再从最大开始取一个点作为正类,取到点3,计算得到TPR=1.0,FPR=0.25;
- 以此类推,得到6对TPR和FPR。
然后把这6对数据组成6个点(0,0.5),(0.25,0.5),(0.25,1),(0.5,1),(0.75,1),(1.0,1.0)。
这6个点在二维坐标系中能绘出来。
(3)如果概率的序列是(1:0.4,2:0.6,3:0.5,4:0.7,5:0.8,6:0.9)

绘制的步骤是:
- 把概率序列从高到低排序,得到顺序(6:0.9,5:0.8,4:0.7,2:0.6,3:0.5,1:0.4);
- 从概率最大开始取一个点作为正类,取到点6,计算得到TPR=0.0,FPR=0.25;
- 从概率最大开始,再取一个点作为正类,取到点5,计算得到TPR=0.0,FPR=0.5;
- 再从最大开始取一个点作为正类,取到点4,计算得到TPR=0.0,FPR=0.75;
- 以此类推,得到6对TPR和FPR。
然后把这6对数据组成6个点(0.25,0.0),(0.5,0.0),(0.75,0.0),(1.0,0.0),(1.0,0.5),(1.0,1.0)。
这6个点在二维坐标系中能绘出来。
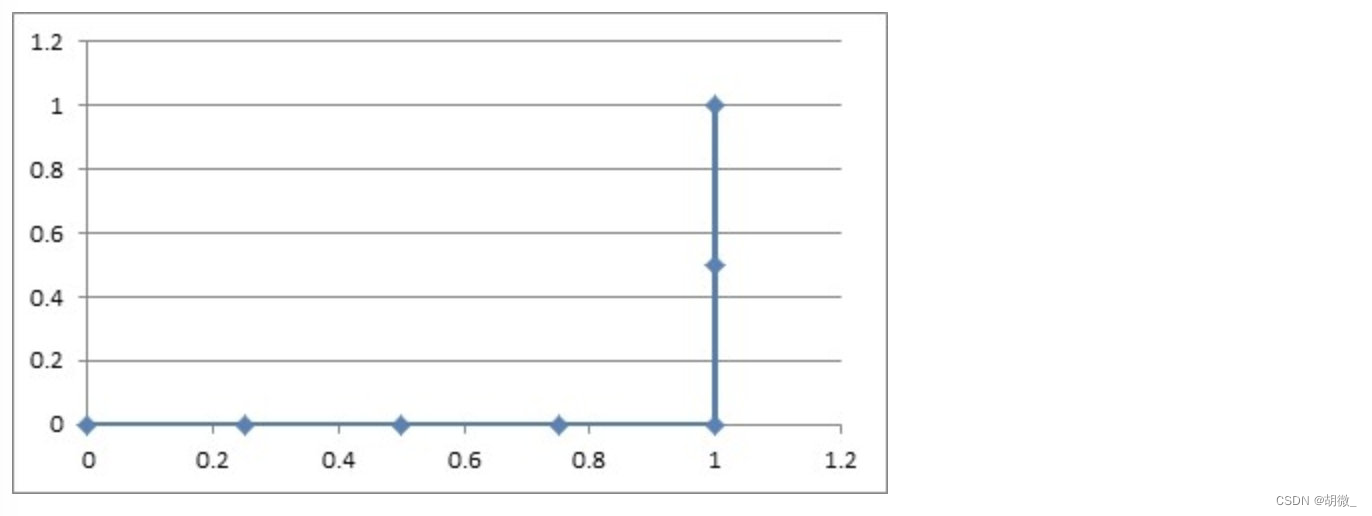
如上图的例子,总共6个点,2个正样本,4个负样本,取一个正样本和一个负样本的情况总共有8种。
- 上面的第一种情况,从上往下取,无论怎么取,正样本的概率总在负样本之上,所以分对的概率为1,AUC=1。再看那个ROC曲线,它的积分是什么?也是1,ROC曲线的积分与AUC相等。
- 上面第二种情况,如果取到了样本2和3,那就分错了,其他情况都分对了;所以分对的概率是0.875,AUC=0.875。再看那个ROC曲线,它的积分也是0.875,ROC曲线的积分与AUC相等。
- 上面的第三种情况,无论怎么取,都是分错的,所以分对的概率是0,AUC=0.0。再看ROC曲线,它的积分也是0.0,ROC曲线的积分与AUC相等。
其实AUC的意思是——Area Under roc Curve,就是ROC曲线的积分,也是ROC曲线下面的面积。
绘制ROC曲线的意义很明显,不断地把可能分错的情况扣除掉,从概率最高往下取的点,每有一个是负样本,就会导致分错排在它下面的所有正样本,所以要把它下面的正样本数扣除掉(1-TPR,剩下的正样本的比例)。总的ROC曲线绘制出来了,AUC就定了,分对的概率也能求出来了。
5 分类中类别不平衡问题
当遇到数据类别不平衡的时候,我们该如何处理。在Python中,有Imblearn包,它就是为处理数据比例失衡而生的。
安装Imblearn包
pip install imbalanced-learn
from sklearn.datasets import make_classification
# make\_classification生成符合条件的数据集
import matplotlib.pyplot as plt
from collections import Counter
# 使用make\_classification生成不平衡的样本数据
X, y = make_classification(n_samples=5000,
n_features=2, # 特征个数= n\_informative() + n\_redundant + n\_repeated
n_informative=2, # 多信息特征的个数
n_redundant=0, # 冗余信息,informative特征的随机线性组合
n_repeated=0, # 重复信息,随机提取n\_informative和n\_redundant 特征
n_classes=3, # 分类类别
n_clusters_per_class=1, # 某一个类别是由几个cluster构成的
weights=[0.01, 0.05, 0.94], # 列表类型,权重比
random_state=0)
print(Counter(y)) # Counter({2: 4674, 1: 262, 0: 64})
# 数据集可视化
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
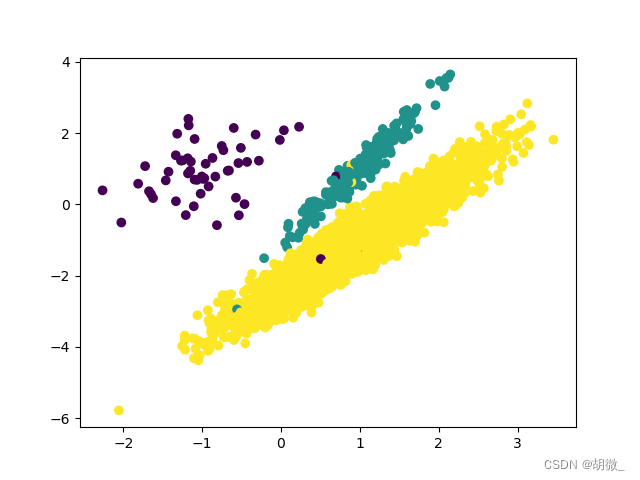
关于类别不平衡的问题,主要有两种处理方式:
- 过采样方法
- 增加数量较少那一类样本的数量,使得正负样本比例均衡。
- 欠采样方法
- 减少数量较多那一类样本的数量,使得正负样本比例均衡。
5.1 过采样方法
对训练集里的少数类进行“过采样”(oversampling),即增加一些少数类样本使得正、反例数目接近,然后再进行学习。
(1)随机过采样方法

# 使用imblearn进行随机过采样
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=0)
X_resampled, y_resampled = ros.fit_resample(X, y)
#查看结果
print(Counter(y_resampled))
#过采样后样本结果
# Counter({2: 4674, 1: 4674, 0: 4674})
# 数据集可视化
plt.scatter(X_resampled[:, 0], X_resampled[:, 1], c=y_resampled)
plt.show()
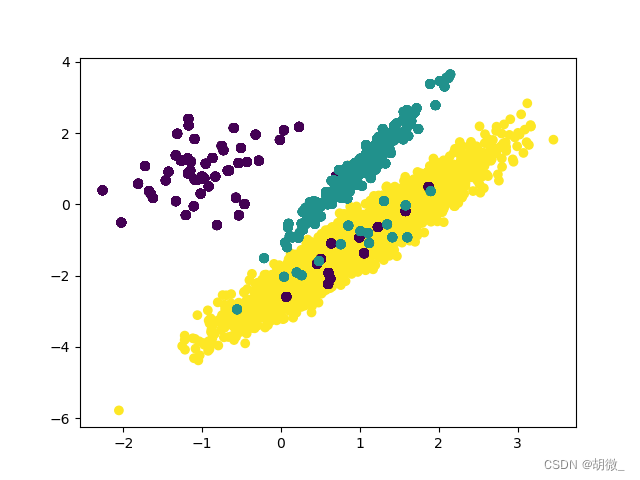
缺点:
- 对于随机过采样,由于需要对少数类样本进行复制来扩大数据集,造成模型训练复杂度加大。
- 另一方面也容易造成模型的过拟合问题,因为随机过采样是简单的对初始样本进行复制采样,这就使得学习器学得的规则过于具体化,不利于学习器的泛化性能,造成过拟合问题。
为了解决随机过采样中造成模型过拟合问题,又能保证实现数据集均衡的目的,出现了过采样法代表性的算法SMOTE算法。
(2) 过采样代表性算法-SMOTE

- 先随机选定一个少数类样本 [公式] 。
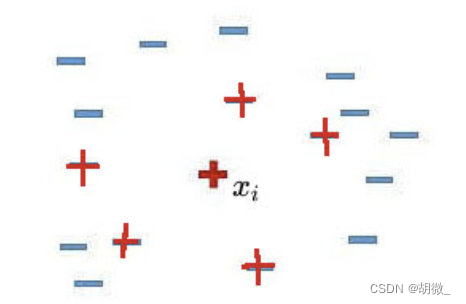
- 找出这个少数类样本 [公式] 的K个近邻(假设K=5),5个近邻已经被圈出。
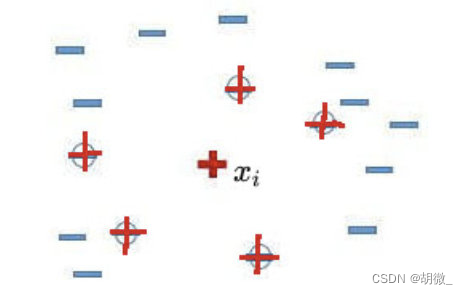
- 随机从这K个近邻中选出一个样本 [公式] (用绿色圈出来了)。

4)在少数类样本 [公式] 和被选中的这个近邻样本 [公式] 之间的连线上,随机找一点。这个点就是人工合成的新的样本点(绿色正号标出)。
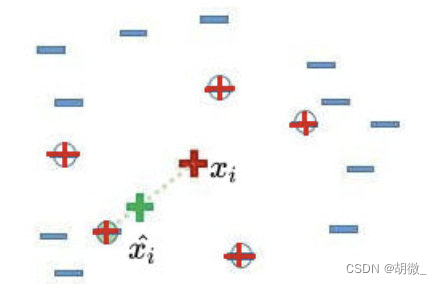
SMOTE算法摒弃了随机过采样复制样本的做法,可以防止随机过采样中容易过拟合的问题,实践证明此方法可以提高分类器的性能。
# 使用imblearn进行随机过采样
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=0)
X_resampled, y_resampled = ros.fit_resample(X, y)
#查看结果
print(Counter(y_resampled))
#过采样后样本结果
# Counter({2: 4674, 1: 4674, 0: 4674})
# 数据集可视化
plt.scatter(X_resampled[:, 0], X_resampled[:, 1], c=y_resampled)
plt.show()
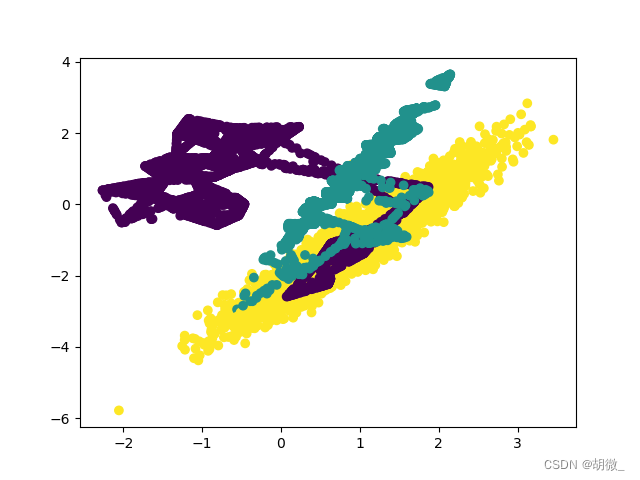
# SMOTE过采样
from imblearn.over_sampling import SMOTE
X_resampled, y_resampled = SMOTE().fit_resample(X, y)
print(Counter(y_resampled))
# 采样后样本结果
# [(0, 4674), (1, 4674), (2, 4674)]
# 数据集可视化
plt.scatter(X_resampled[:, 0], X_resampled[:, 1], c=y_resampled)
plt.show()

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
😕/img-blog.csdnimg.cn/4f8453ec520b4ed98f8ff2d2ab9b2f57.png)
[外链图片转存中…(img-nVHGG2eO-1715806845353)]
[外链图片转存中…(img-WnDdYiaS-1715806845353)]
[外链图片转存中…(img-TmcG9t0H-1715806845354)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









