







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
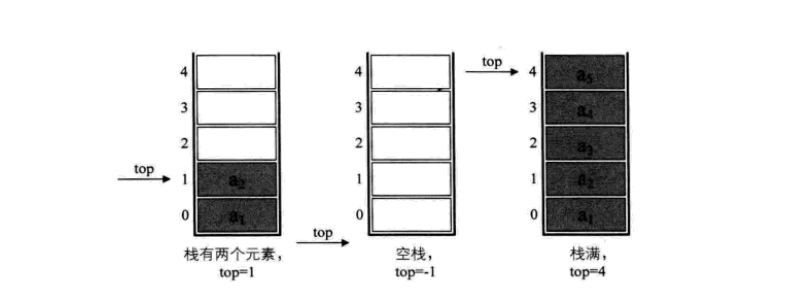
若现在有一个栈,StackSize 是5,则栈普通情况、空栈和栈满的情况示意图
对于栈的插入,即进栈操作,其实就是做了下面的处理
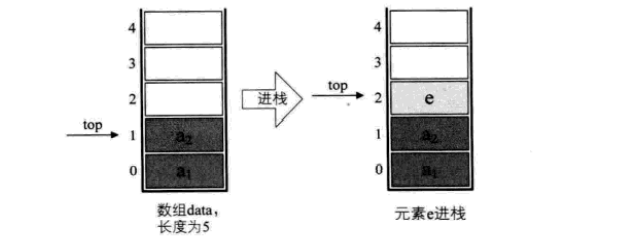
/插入元素e为新的栈顶元素/
Status Push ( SqStack *S, SElemType e)
{
if (S->top == MAXSIZE -1) //栈满
{
return ERROR;
}
s->top++; /*栈顶指针增加一/
S->data[S->top]=e; /将新插入元素赋值给栈顶空间,将To/
return OK;
}
/插入元素e为新的栈顶元素/
Status Push ( SqStack *S, SElemType e)
{
if (S->top – MAXSIZE -1) //栈满
{
return ERROR;
}
*e = s->data[s->top] /将要删除的栈顶元素赋值给e/
s->top–; /*栈顶指针减一/
return OK;
}
两者没有涉及到任何循环语句,因此时间复杂度均是o(1)
=========================================================================
其实栈的顺序存储还是很方便的,因为它只准栈顶进出元素,所以不存在线性表
插入和删除时需要移动元素的问题。不过它有一个很大的缺陷,就是必须事先确定数组存储空间大小,万一不够用了,就需要编程手段来扩展数组的容量,非常麻烦。对于一个栈,我们也只能尽量考虑周全,设计出合适大小的数组来处理,但对于两个相同类型的栈,我们却可以做到最大限度地利用其事先开辟的存储空间来进行操作。
做法如图,数组有两个端点,两个栈有两个栈底,让一个栈的栈底为数组的始端,即下标为0处,另一个栈为栈的末端,即下标为数组长度n-1处。这样,两个栈如果增加元素,就是两端点向中间延伸。
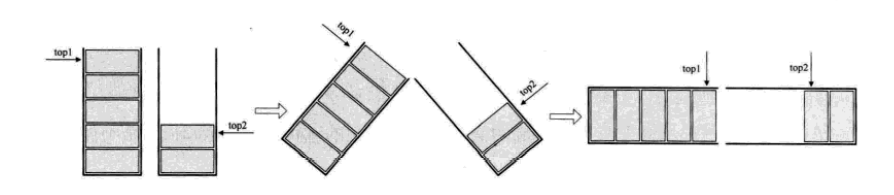
其实关键思路是:它们是在数组的两端,向中间靠拢。top1 和top2是栈1和栈2的栈顶指针,可以想象,只要它们俩不见面,两个栈就可以一直使用。
从这里也就可以分析出来,栈1为空时,就是top1等于-1时;而当top2等于n时,即是栈2为空时,那什么时候栈满呢?
想想极端的情况,若栈2是空栈,栈1的top1等于n-1时,就是栈1满了。反之,当栈1为空栈时,top2 等于0时,为栈2满。但更多的情况,其实就是刚才说的,两个栈见面之时,也就是两个指针之间相差1时,即top1 + 1 == top2 为栈
代码实现如下:
typedef struct StackNode
{
SElemType data;
struct StackNode *next;
}StackNode, *LinkStackPtr;
typedef struct LinkStack
{
LinkStackPtr top;
int count;
} LinkStack;
对于两栈共享空间的push方法,我们除了要插入元素值参数外,还需要有一个判断是栈1还是栈2的栈号参数stackNumber。插入元素的代码如下:
/插入元素e为新的栈顶元素/
Status Push ( SqDoubleStack *S, SElemType e,int stackNumber )
{
if(s->top1+1==s->top2) /栈已满,不能再push新元素了/
return ERROR;
if ( stackNumber==1 ) /栈1有元素进栈/
S->data[++S->top1]=e; /若栈1则先top1+1后给数组元素赋值/
else if ( stackNumber==2) /栈2有元素进栈/
S->data[–s->top2]=e;/若栈2则先top2-1后给数组元素赋值/
return OK;
}
因为在开始已经判断了是否有栈满的情况,所以后面的top1+1或top2-1是不担
心溢出问题的。
对于两栈共享空间的pop方法,参数就只是判断栈1栈2的参数stackNumber,
/*若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR */
Status Pop ( SqDoubleStack *S, SElemType *e, int stackNumber )
{
if( stackNumber==1 )
{
if (s->top1==-1)
return ERROR; /说明栈1已经是空栈,溢出/
*e=S->data[s->top1–]; /将栈1的栈顶元素出栈/
}
else↓if( stackNumber==2 )
{
if(s->top2==MAXSIZE )
return ERROR; /说明栈2已经是空栈,溢出/
e=S->data[s->top2++]; / 将栈2的栈顶元素出栈*/
}
return OK;
}
=============================================================================
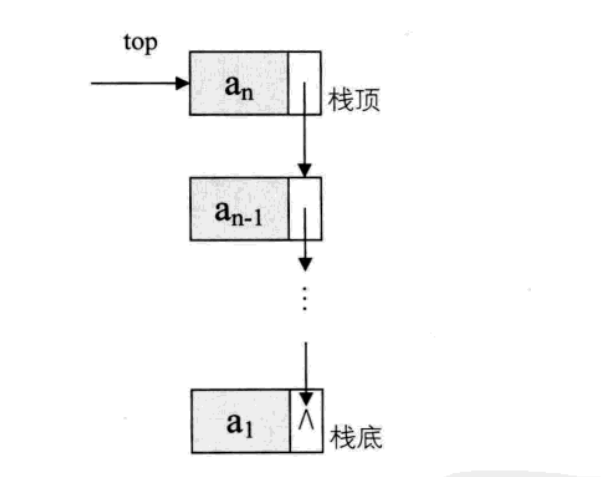
栈的链式存储结构,简称为链栈
栈只是栈顶来左插入和删除操作,栈顶放在链表的头部还是尾部?由于单链表有头指针,而栈顶指针也是必须的,可以把他们合二为一,所以最好的办法是把栈顶放在单链表的头部,所以对于链栈来说,是不需要头结点的
对于链栈来说,基本不存在栈满的情况,除非内存已经没有可以使用的空间,如果真的发生,那此时的计算机操作系统已经面临死机崩溃的情况,而不是这个链栈是否溢出的问题。
代码实现
typedef struct StackNode
{
SElemType data;
struct用StackNode *next;
} StackNode,*LinkStackPtr;
typedef struct LinkStack
{
LinkStackPtr top;
int count;
} Linkstack;
链栈的操作绝大部分都和单链表类似,只是在插入和删除上,特殊一些。
对于链栈的进栈push操作,假设元素值为e的新结点是s,top为栈顶指针
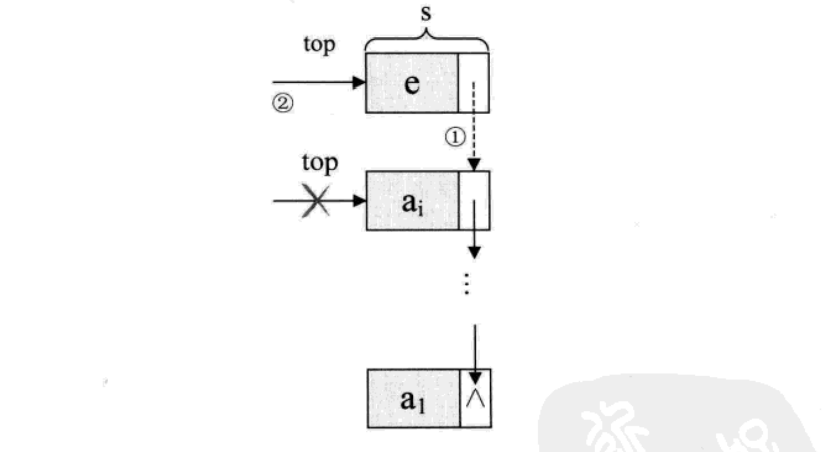
/插入元素e为新的栈顶元素/Status Push ( Linkstack *S, SElemType e){ LinkStackPtr s= ( LinkStackPtr ) malloc (sizeof ( StackNode) ) ; s->data=e; s->next = s->top //把当前的栈顶元素赋值给新节点的直接后继 S->top=s; /将新的结点s赋值给栈顶指针/ S->count++; //将新的结点s赋值给栈顶指针 return OK;}
至于链栈的出栈pop操作,也是很简单的三句操作。假设变量p用来存储要删除的栈顶结点,将栈顶指针下移一位,最后释放p即可
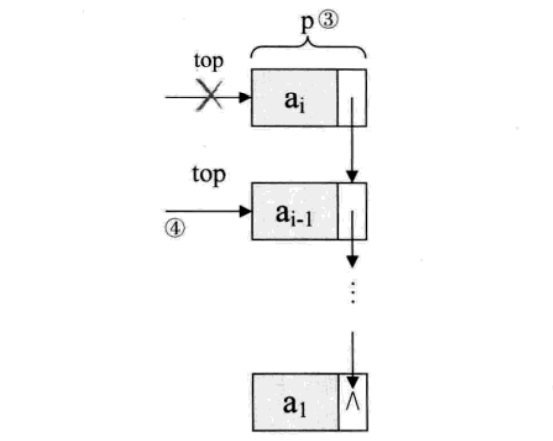
/*若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR */Status Pop ( LinkStack *S, SElemType *e){ LinkStackPtr P; if ( StackEmpty(*S)) return ERROR; *e=S->top->data; p=S->top; /将栈顶结点赋值给p/ s->top=s->top->next; /使得栈顶指针下移一位,指向后一结点/ free § ; /*释放结点p */ S->count–; return OK;}
链栈的进栈push和出栈pop操作都很简单,没有任何循环操作,时间复杂度均为0(1)。对比一下顺序栈与链栈,它们在时间复杂度上是一样的,均为0(1)。 对于空间性能,顺序栈需要事先确定一个 固定的长度,可能会存在内存空间浪费的问题,但它的优势是存取时定位很方便,而链栈则要求每个元素都有指针域,这同时也增加了一些内存开销,但对于栈的长度无限制。所以它们的区别和线性表中讨论的一样,如果栈的使用过程中元素变化不可预料,有时很小,有时非常大,那么最好是用链栈,反之,如果它的变化在可控范围内,建议使用顺序栈会更好一些。
======================================================================
用数组或链表直接实现功能不就行了吗?干吗要引入栈这样的数据结构呢?这个问题问得好。其实这和我们明明有两只脚可以走路,干吗还要乘汽车、火车、飞机一样。理论上,陆地上的任何地方,你都是可以靠双脚走到的,可那需要多少时间和精力呢?我们更关注的是到达而不是如何去的过程。栈的引入简化了程序设计的问题,划分了不同关注层次,使得思考范围缩小,更加聚焦于我们要解决的问题核心。反之,像数组等,因为要分散精力去考虑数组的下标增减等细节问题,反而掩盖了问题的本质。所以现在的许多高级语言,比如Java、 C#等都有对栈结构的封装,你可以不用关注它的实现细节,就可以直接使用Stack的push和pop方法,非常方便。
栈有一个很重要的应用:在程序设计语言中实现了递归。那么什么是递归呢?
当你往镜子前面一站,镜子里面就有一个你的像。但你试过两面镜子一起照吗?如果A、B两面镜子相互面对面放着,你往中间一站,嘿,两面镜子里都有你的千百个“化身”。为什么会有这么奇妙的现象呢?原来,A镜子里有B镜子的像,B镜子里也有A镜子的像,这样反反复复,就会产生一连串的“像中像”。这是一种递归现象!
哈哈哈好有意思啊!
就是那个兔子生兔子的问题啦,原来在b站学习的时候都会有讲这个例子~

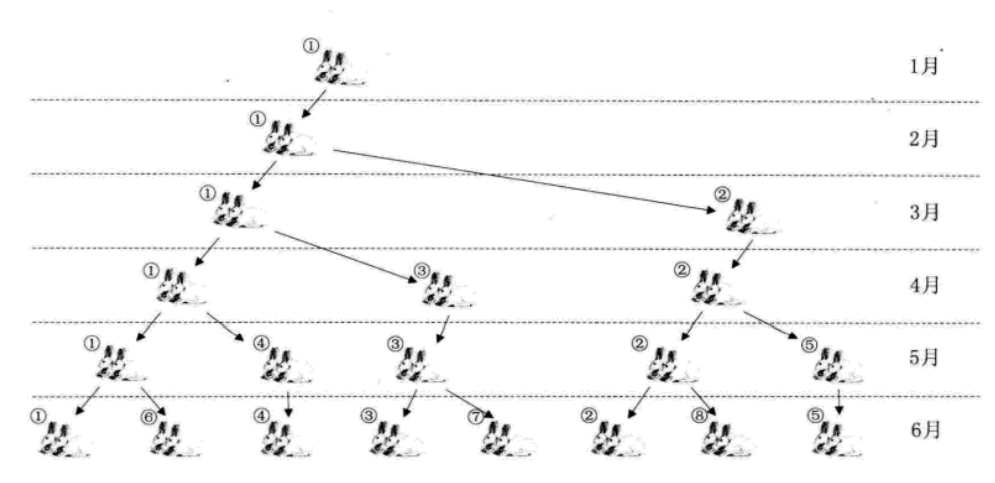
斐波那契数列的特点就是:前面相邻两项之和,构成了后一项
用迭代实现
int main( ){ int i; int a[40]; a[0]=0; a[1]=1; printf ("%d “,a[0]) ; printf (”&=%d “,a[1]) ; for (i=2;i< 40;i++ ) { a[i]= a[i-1] + a[i-2]; printf (”%d ",a[i] ) ; } return 0;}
用递归实现
int Fbi ( int i){ if(!i<2) return i== 0?0 :1; return Fbi (i-1)+ Fbi (i-2) ;/这里Fbi就是函数自己,它在调用自己/ }int main ( ){ int i; for (int i= 0;i < 40;i++ ) printf ("&d ",Fbi(i)) ; return 0;
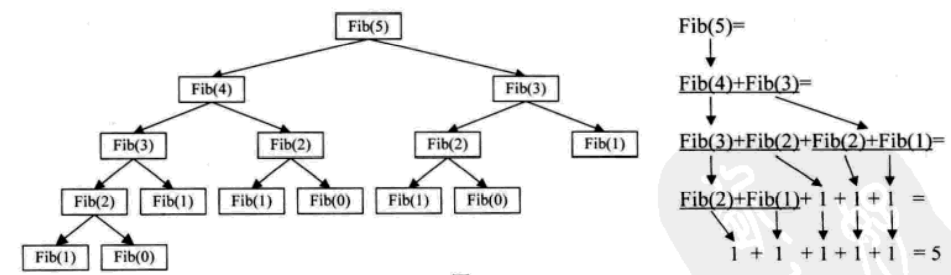
在高级语言中,调用自己和其他函数并没有本质的不同。我们把一个直接调用自己或通过一系列的调用语句间接地调用自己的函数,称做递归函数。
当然,写递归程序最怕的就是陷入永不结束的无穷递归中,所以,每个递归定义必须至少有一个条件,满足时递归不再进行,即不再引用自身而是返回值退出。比如刚才的例子,总有一次递归会使得i<2的,这样就可以执行return i的语句而不用继续递归了。
对比了两种实现斐波那契的代码。迭代和递归的区别是:迭代使用的是循环结构,递归使用的是选择结构。递归能使程序的结构更清晰、更简洁、更容易让人理解,从而减少读懂代码的时间。但是大量的递归调用会建立函数的副本,会耗费大量的时间和内存。迭代则不需要反复调用函数和占用额外的内存。因此我们应该视不同情况选择不同的代码实现方式。
========================================================================
生活中的实例
电脑有的时候会处于疑似死机的状态,鼠标点什么都没用,刚准备重启的时候它又突然好起来了,然后将我们点击的所有操作都按顺序执行了一遍。这其实是因为操作系统中的多个程序因需要通过一个通道输入,而按先后次序排队等待造成的
还有平时我们打客服电话的时候,需要排队等待
操作系统和客服系统中,都是应用了一种数据结构来实现刚才提到的先进先出的
排队功能,这就是队列。
队列(queue)是允许在一端进行插入操作,而在另一端进行删除操作的线性表
队列是一种先进先出(First In First Out)的线性表,简称FIFO
回顾我们上面学的栈是后进先出哦

队列在程序设计中用得非常频繁。前面我们已经举了两个例子,再比如用键盘进行各种字母或数字的输入,到显示器上如记事本软件上的输出,其实就是队列的典型
============================================================================
同样是线性表,队列也有类似线性表的各种操作,不同的就是插入数据只能在队
尾进行,删除数据只能在队头进行。
ADT队列( Queue )Data 同线性表。元素具有相同的类型,相邻元素具有前驱和后继关系。Operation InitQueue (*Q) :初始化操作,建立一个空队列Q。 DestroyQueue (*Q) :若队列Q存在,则销毁它。 ClearQueue (*Q) :将队列Q清空。 QueueEmpty (Q) :若队列Q为空,返回true,否则返回false。 GetHead (Q,*e) :若队列Q存在且非空,用e返回队列e的队头元素。 EnQueue (*Q,e) :若队列Q存在,插入新元素e到队列Q中并成为队尾元素。 DeQueue (*Q,*e):删除队列Q中队头元素,并用e返回其值。 QueueLength(Q) :返回队列Q的元素个数endADT
========================================================================
线性表有顺序存储和链式存储,栈是线性表,所以有这两种存储方式。同样,队列作为一种特殊的线性表,也同样存在这两种存储方式。我们先来看队列的顺序存储结构。
==============================================================================
我们假设一个队列有n个元素,则顺序存储的队列需建立一个大于n的数组,并把队列的所有元素存储在数组的前n个单元,数组下标为0的一端即是队头。所谓的入队列操作,其实就是在队尾追加一个元素,不需要移动任何元素,因此时间复杂度为O(1)

与栈不同的是,队列元素的出列是在队头,即下标为0的位置,那也就意味着,
队列中的所有元素都得向前移动,以保证队列的队头,也就是下标为0的位置不为
空,此时时间复杂度为0(n)

在现实中也是如此,一群人在排队买票,前面的人买好了离开,后面的人就要全部向前一步,补上空位,似乎这也没什么不好。
那能不能出队列的时候,后面的元素不存储再数值的前n个单元这一条件,出队列的性能就会大大增加。也就是说,对头不需要一定在下标为0的位置

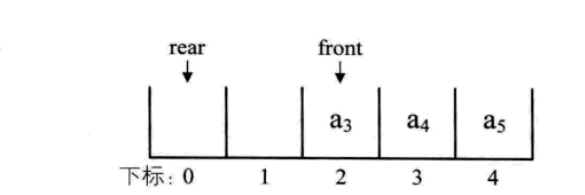
为了避免当只有一个元素时,队头和队尾重合使处理变得麻烦,所以引入两个指针,front 指针指向队头元素,rear 指针指向队尾元素的下一-个位置,这样当front等于rear时,此队列不是还剩-一个元素,而是空队列。
假设是长度为5的数组,初始状态,front 与rear指针均指向下标为0的位置。然后入队a1、a2、a3、 a4, front 指针依然指向下标为0位置,而rear指针指向下标为4的位置

出队a1、a2, 则front指针指向下标为2的位置,rear 不变,再入队as,此时front指针不变,rear 指针移动到数组之外。嗯?数组之外,那将是哪里?

问题还不止于此。假设这个队列的总个数不超过5个,但目前如果接着入队的话,因数组末尾元素已经占用,再向后加,就会产生数组越界的错误,可实际上,我们的队列在下标为0和1的地方还是空闲的。我们把这种现象叫做**“ 假溢出”。**
现实当中,你上了公交车,发现前排有两个空座位,而后排所有座位都已经坐满,你会怎么做?立马下车,并对自己说,后面没座了,我等下一辆?没有这么笨的人,前面有座位,当然也是可以坐的,除非坐满了,才会考虑下一辆。
所以解决假溢出的办法就是后面满了,就再从头开始,也就是头尾相接的循环。我们把队列的这种头尾相接的顺序存储结构称为循环队列。
上面的例子继续,rear可以改为指向下标为0的位置,这样就不会造成指针指向不明的问题了
接着入队a6,将它放置于下标为0处,rear指针指向下标为1处,若再入队a7,则rear指针就与front指针重合,同时指向下标为2的位
置

此时问题又出来了,我们刚才说,空队列时,front 等于rear, 现在当队列满时,也是front等于rear,那么如何判断此时的队列究竟是空还是满呢?
办法一个标志变量flag,当front == rear,且flag = 0时为队列空,当front== rear,且fag= 1时为队列满。
办法二是当队列空时,条件就是front = rear,当队列满时,我们修改其条件,保留一个元素空间。也就是说,队列满时,数组中还有一个空闲单元。我们就认为此队列已经满了,也就是说,我们不允许如下右图的情况出现

队列满的条件是(rear + 1) % QueueSize == front(取模的目的就是为了整合rear与front大小为一个问题)
我们可以根据图,求出队列中的元素
当rear>front时,队列中的元素个数为rear - front
当rear<front时,队列中的元素个数为两段,一段为QueueSize - front,另一段为0 + rear
这两段加起来为rear - front + QueueSize
.通用的计算队列长度的公式为:
(rear - front + QueueSize) % QueueSize
循环队列的顺序结构代码如下:
typedef int QE1 emType; /* QElemType类型根据实际情况而定,这里假设为int //循环队列的顺序存储结构/typedef struct{ QE1 emType data [MAXSIZE]; int front;/ 头指针*/ int rear;/尾指针,若队列不空,指向队列尾元素的下一个位置/} SqQueue;
初始化代码
/初始化一个空队列Q/Status InitQueue ( SqQueue *Q ){ Q->front=0; Q->rear=0; return OK;}
循环队列求队列长度代码如下:
/返回Q的元素个数,也就是队列的当前长度/int QueueLength ( SqQueue Q){ return (Q.rear-Q.front+MAXSIZE)%MAXSIZE;}
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
的顺序存储结构*/typedef struct{ QE1 emType data [MAXSIZE]; int front;/* 头指针*/ int rear;/尾指针,若队列不空,指向队列尾元素的下一个位置/} SqQueue;
初始化代码
/初始化一个空队列Q/Status InitQueue ( SqQueue *Q ){ Q->front=0; Q->rear=0; return OK;}
循环队列求队列长度代码如下:
/返回Q的元素个数,也就是队列的当前长度/int QueueLength ( SqQueue Q){ return (Q.rear-Q.front+MAXSIZE)%MAXSIZE;}
[外链图片转存中…(img-7pSBt5wg-1715274122660)]
[外链图片转存中…(img-Op1DZSXU-1715274122660)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 993
993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









