






ArcType arcs[MVNum][MVNum]; //邻接矩阵
int vexnum, arcnum; //图的当前点数和边数。
}AMGraph; // Adjacency Matrix Graph
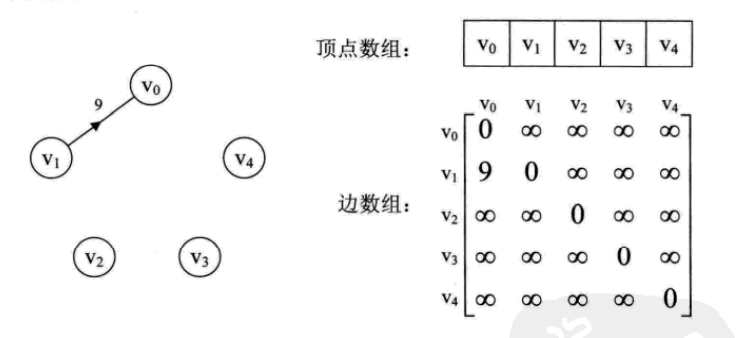
为了解决边数相对顶点较少的图,邻接矩阵这种结构会存在大量的空间浪费
如下:
再回忆我们在树中谈存储结构时,讲到了一种孩子表示法,将结点存入数组,并对结点的孩子进行链式存储,不管有多少孩子,也不会存在空间浪费问题。这个思路同样适用于图的存储。我们把这种数组与链表相结合的存储方法称为邻接表
(Adjacency List)。
邻接表的处理办法:
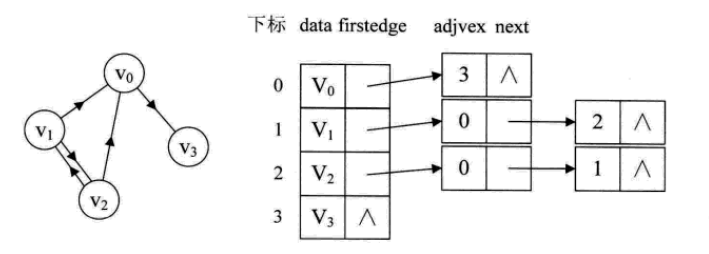
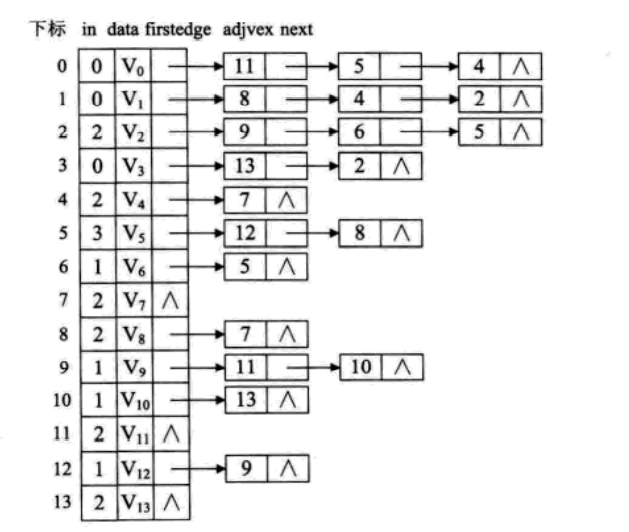
1.图中顶点用一个一维数组存储,当然,顶点也可以用单链表来存储,不过数组可以较容易地读取顶点信息,更加方便。另外,对于顶点数组中,每个数据元素还需要存储指向第一个邻接点的指针,以便于查找该顶点的边信息。
2.图中每个顶点Vi的所有邻接点构一个线性表,由于邻接点的个数不定,所以用单链表存储,无向图称为顶点Vi的边表,有向图则称为顶点Vi作为弧尾的出表。

上图中的V1顶点与V0、V2互为邻接点,则在V1的边表中,adjvex分别为V0的0和V2的2
下面解释什么是边表
顶点表的各个节点由data和firstedge两个域表示,data是数据域,存储顶点的信息,firstedge是指针域,**指向边表(因为它是无向图,所以叫边表)**的第一个结点,即此顶点的第一个邻接点。边表结点由adjvex和next两个域组成。adjvex 是邻接点域,存储某顶点的邻接点在顶点表中的下标,next 则存储指向边表中下一个结点的指针。
在有向图中,邻接表的结构是类似的
我们可以建立一个有向图的逆邻接表,即对每个顶点Vi都建立一个链接为v为弧头的表
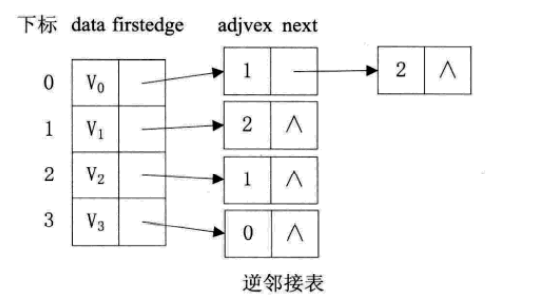
此时我们很容易就可以算出某个顶点的入度或出度是多少,判断两顶点是否存在弧也很容易实现。
对于带权值的网图,可以在边表结点定义中再增加一个weight的数据域,存储权值信息即可
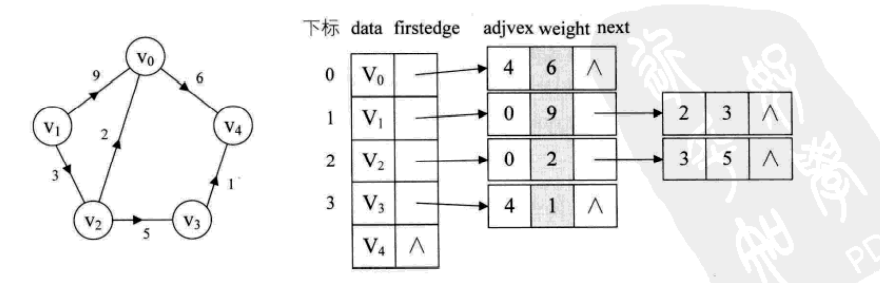
那么对于有向图来说,邻接表是有缺陷的。关心了出度问题,想了解入度就必须要遍历整个图才能知道,反之,逆邻接表解决了入度却不了解出度的情况。有没有可能把邻接表与逆邻接表结合起来呢?答案是肯定的,就是把它们整合在一起。这就是我们现在要讲的有向图的一种存储方法:十字链表(Orthogonal List)。
重新定义结点表结点结构
data firstin firstout
其中firstin表示入边表头指针,指向该顶点的入边表中第一个结点, firstout 表示出边表头指针,指向该顶点的出边表中的第一个结点。
重新定义边表结点结构

其中**tailvex 是指弧起点在顶点表的下标,headvex 是指弧终点在顶点表中的下标,headlink是指入边表指针域,指向终点相同的下一条边,tallink 是指边表指针域,指向起点相同的下一条边。**如果是网,还可以再增加一个 weight域来存储权值。
实例如下:
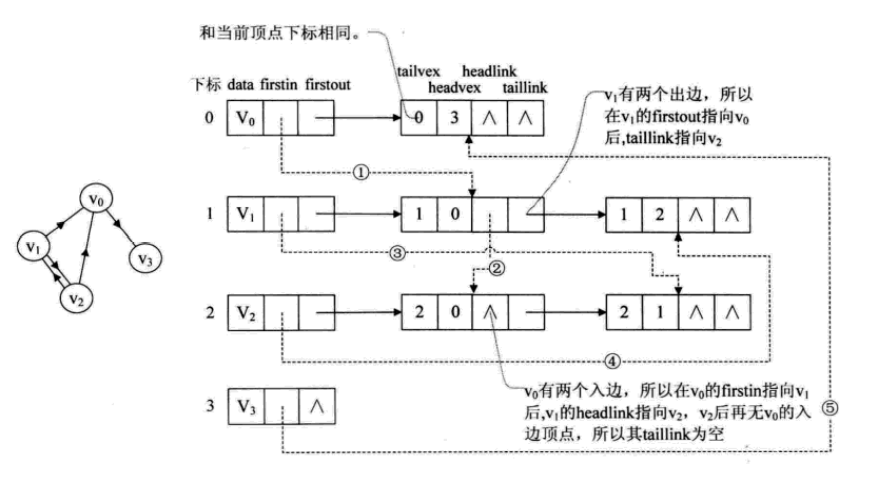
以顶点V0来说,firstout指向的是出边表中的第一个结点V3所以tailvex和headvex是03(就是数组下标),那为什么headlink和taillink为空了呢,因为没用终点和V0一样的结点了(指向V3的),那为什么taillink也为空呢,因为没有和V0一样起点的结点(从V0出发)了呀!
图中也有些例子,可以多理解理解
同志们一定好好看看和理解这个图!!!
十字链表的好处就是因为把邻接表和逆邻接表整合在了一起,这样很容易找到以Vi为尾的弧,也容易找到以vi为头的弧,从而更容易求得顶点的出度和入度
缺点就是结构复杂了一点,在有向图的应用中,十字链表是非常好的数据结构模型
十字链表对有向图的存储结构进行了优化
在无向表的应用中,关注的重点是顶点,邻接表是好的选择
如果关注的是边的操作,就需要更简单的方式
对边表结点结构重新定义

其中ivex和jvex是与某条边依附的两个顶点在顶点表中下标。
ilink 指向依附顶点ivex的下一条边
jlink 指向依附顶点jvex的下一条边
下图告诉我们它有4个顶点和5条边,显然,我们就应该先将4个顶点和5条边的边表结点画出来。由于是无向图,所以ivex是0、jvex是1还是反过来都是无所谓的,不过为了绘图方便,都将ivex值设置得与一旁的顶点下标相同。
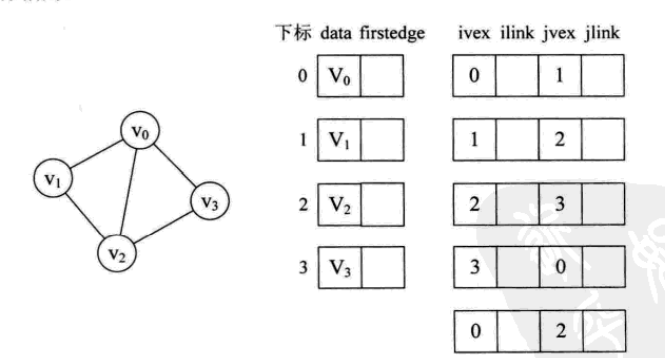
好,我们来分析这个图
firstedge是指针域,指向边表的第一个结点,ivex和jvex是依附于边的顶点坐标的下标(注意是顶点坐标的下标),比如图中的0和1,那么它们就代表顶点V0和顶点V1中间的那条边
那么ilink和jlink是什么呢?
ilink指的是ivex依附顶点的下一条边
jlink指的是jvex依附顶点下一条边
实例如图所示:
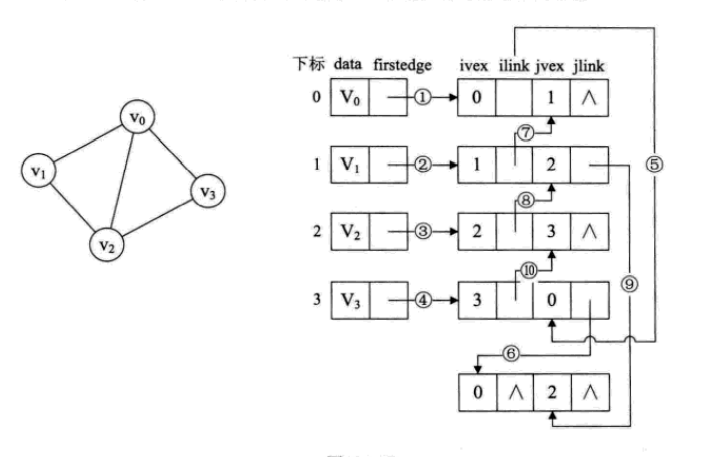
看上面的连线,firstedge指向一条边,顶点下标和ivex的值相同,继续,顶点V0有三个边跟它有关v0v1,v0v2,v0v3
所以连线5,6满足指向下一条依附于顶点的v0的边的目标,ilink指向的结点的jvex一定要和它本身的ivex值相同。连线7就是指v1,v0这条边,它是相当于顶点v1指向v1,v2边后的下一条。v2有三条依附,所以在连线3后就有了8跟9.连线10的就是顶点v3在连线4后下一条边。
图上共5条边所以有10条连线,符合预期
邻接多重表与邻接表的差别,仅仅是在于同一条边在邻接表中用两个结点表示,而在邻接多重表中只有一个结点。 这样对边的操作就方便多了,若要删除左图的(V0,V2) 这条边,只需要将右图的⑥⑨的链接指向改为^即
可。各种基本操作的实现也和邻接表是相似的
边集数组是由两个一维数组构成。一个是存储顶点的信息;另一个是存储边的信息,这个边数组每个数据元素由一条边的起点下标(begin)、终点下标(end) 和权(weight)组成
实例如下:
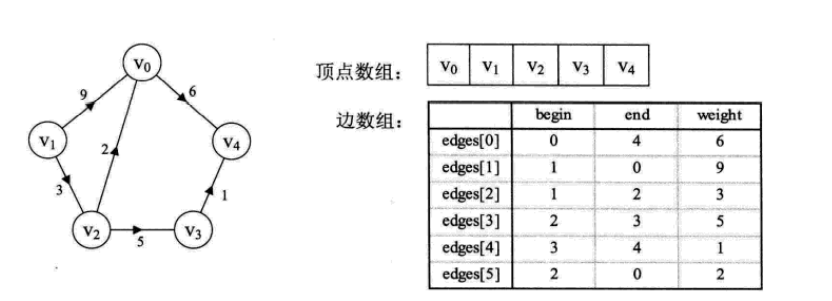
这个结构很好理解,看图就能看懂
======================================================================
图的遍历是和树的遍历类似,我们希望从图中某一顶点出 发访遍图中其余顶点,且使每一个顶点仅被访问一次,这一过程就叫做图的遍(Traversing Graph)。
深度优先遍历(Deep_First_Search),称为简称DFS。
主要思路是从图中一个未访问的顶点 V 开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成,它的特点是不撞南墙不回头,先走完一条路,再换一条路继续走。
实例如下,序号代表的是遍历的顺序
从根节点 1 开始遍历,它相邻的节点有 2,3,4,先遍历节点 2,再遍历 2 的子节点 5,然后再遍历 5 的子节点 9
此时就从 9 回退到上一个节点 5,看下节点 5 是否还有除 9 以外的节点,没有继续回退到 2,2 也没有除 5 以外的节点,回退到 1,1 有除 2 以外的节点 3,所以从节点 3 开始进行深度优先遍历
同理从 10 开始往上回溯到 6, 6 没有除 10 以外的子节点,再往上回溯,发现 3 有除 6 以外的子点 7,所以此时会遍历 7
从 7 往上回溯到 3, 1,发现 1 还有节点 4 未遍历,所以此时沿着 4, 8 进行遍历,这样就遍历完成了
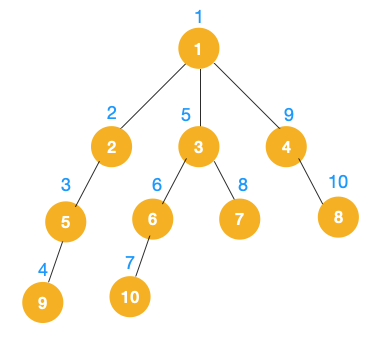
这好像就是树的前序前序遍历啊实际上不管是前序遍历,还是中序遍历,亦或是后序遍历,都属于深度优先遍历。
广度优先遍历(Breadth_ First Search), 又称为广度优先搜索,简称BFS
指的是从图的一个未遍历的节点出发,先遍历这个节点的相邻节点,再依次遍历每个相邻节点的相邻节点
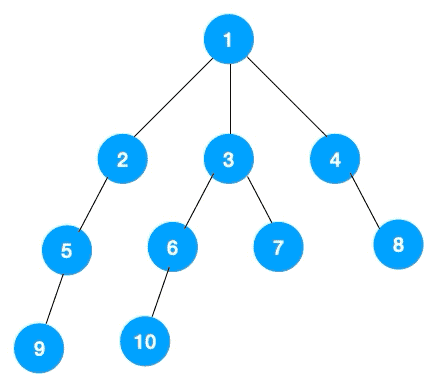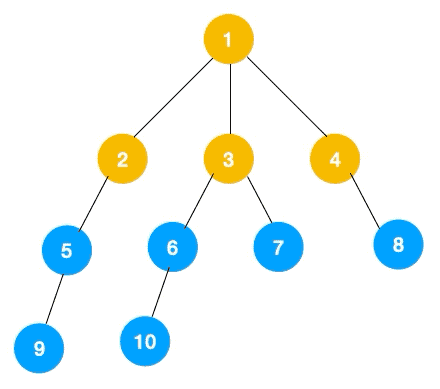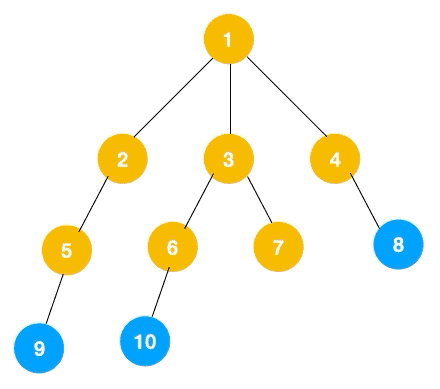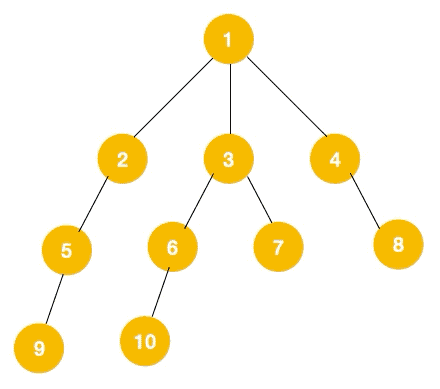
它这个遍历类似图中的层序遍历
DFS 一般是解决连通性问题,而 BFS 一般是解决最短路径问题
C语言实现代码就先不写了,之后会更新Java相关的代码实现,敬请期待
=======================================================================
引用文章:图解:什么是最小生成树? - 知乎 (zhihu.com)
一个连通图的生成树是一个极小的连通子图,它包含图中全部的n个顶点,但只有构成一棵树的n-1条边。
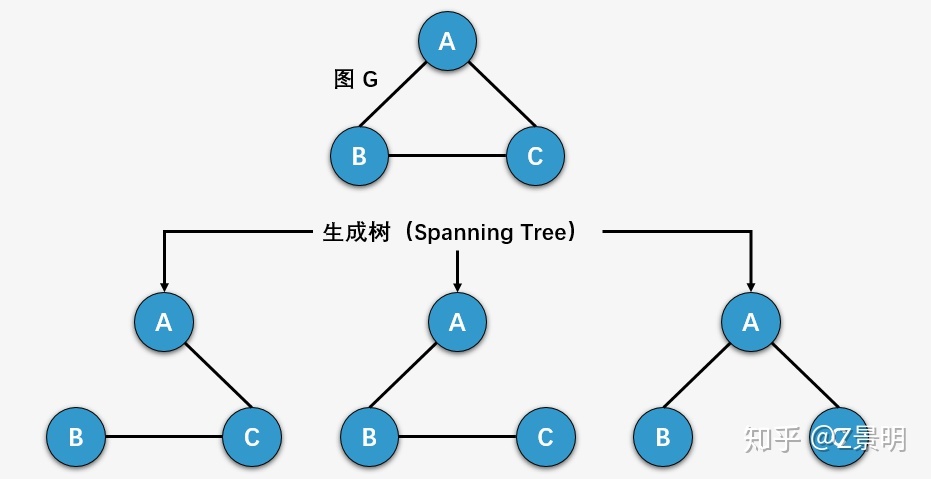
可以看到一个包含3个顶点的完全图可以产生3颗生成树。对于包含n个顶点的无向完全图最多包含 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UhDPoCzY-1637250894565)(https://www.zhihu.com/equation?tex=n%5E%7Bn-2%7D)] 颗生成树。比如上图中包含3个顶点的无向完全图,生成树的个数为: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sOPQgGlo-1637250894567)(https://www.zhihu.com/equation?tex=3%5E%7B3-2%7D%3D3)].
-
一个连通图可以有多个生成树;
-
一个连通图的所有生成树都包含相同的顶点个数和边数;
-
生成树当中不存在环;
-
移除生成树中的任意一条边都会导致图的不连通, 生成树的边最少特性;
-
在生成树中添加一条边会构成环。
-
对于包含n个顶点的连通图,生成树包含n个顶点和n-1条边;
-
对于包含n个顶点的无向完全图最多包含 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WKgCBBcZ-1637250894568)(https://www.zhihu.com/equation?tex=n%5E%7Bn-2%7D)] 颗生成树。
生成树我们知道了,下面我们来看看最小生成树
所谓一个 带权图 的最小生成树,就是原图中边的权值最小的生成树
通过定义我们知道,最小生成树其实是和带权图联系到一起的,如果是非带权图,那他们只存在生成树,我们来看看例子
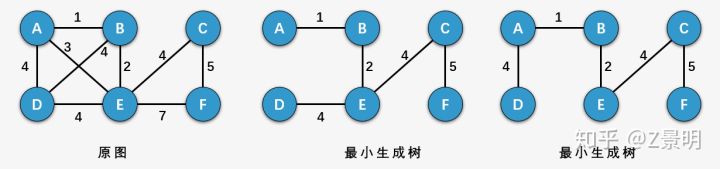
上图中,原来的带权图可以生成左侧的两个最小生成树,这两颗最小生成树的权值之和最小,且包含原图中的所有顶点。
那么如何从图中得到最小生成树呢?
最小生成树算法有很多,其中最经典的就是克鲁斯卡尔(Kruskal)算法和 普里姆(Prim)算法,也是我们考试、面试当中经常遇到的两个算法。
贪心算法一般按如下步骤进行:
①建立数学模型来描述问题
②把求解的问题分成若干个子问题
③对每个子问题求解,得到子问题的局部最优解
④把子问题的解局部最优解合成原来解问题的一个解
克鲁斯卡尔算法(Kruskal)是一种使用贪婪方法的最小生成树算法。 该算法初始将图视为森林,图中的每一个顶点视为一棵单独的树。 一棵树只与它的邻接顶点中权值最小且不违反最小生成树属性(不构成环)的树之间建立连边。
第一步:将图中所有的边按照权值进行非降序排列;
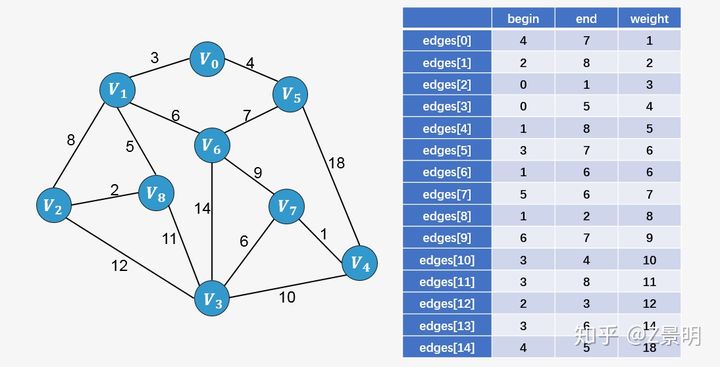
第二步:从图中所有的边中选择可以构成最小生成树的边。
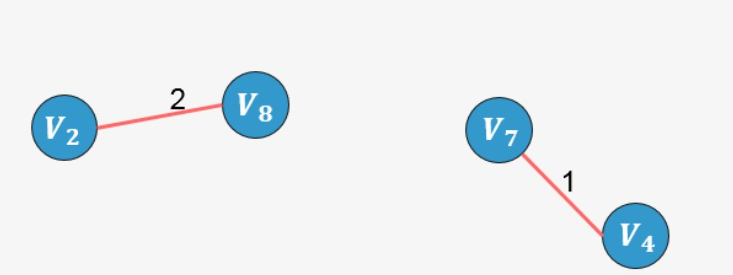
- 选择权值最小的边 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gEIwcwlA-1637250894572)(https://www.zhihu.com/equation?tex=V_4-V_7)]:没有环形成,则添加:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-63KGTZQp-1637250894573)(https://typora-1259403628.cos.ap-nanjing.myqcloud.com/image-20211118093755931.png)]
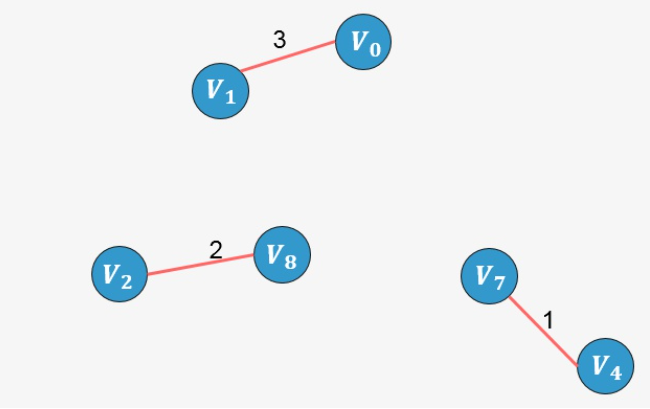
- 选择边 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cPpEBfWk-1637250894575)(https://www.zhihu.com/equation?tex=V_2-V_8)]:没有形成环,则添加:
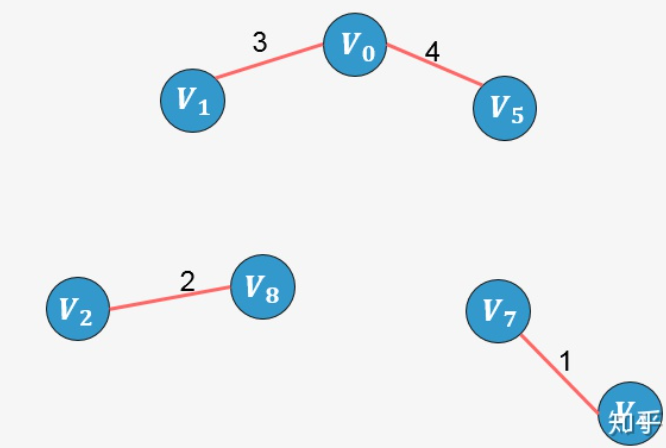
- 选择边 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zGIhEGrW-1637250894577)(https://www.zhihu.com/equation?tex=V_0-V_1)]:没有形成环,则添加:
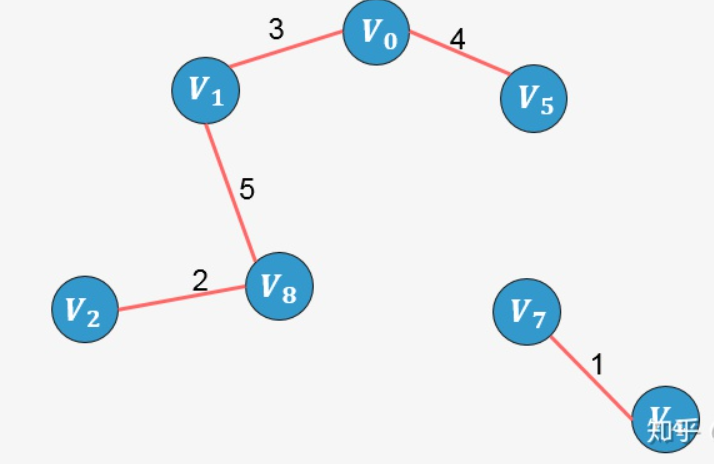
- 选择边 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tiyBvkxO-1637250894580)(https://www.zhihu.com/equation?tex=V_0-V_5)]:没有形成环,则添加:
- 选择边 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LxxZdREq-1637250894583)(https://www.zhihu.com/equation?tex=V_1-V_8)]:没有形成环,则添加:
- 选择边 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-38LRNrIG-1637250894586)(https://www.zhihu.com/equation?tex=V_3-V_7)]:没有形成环,则添加:
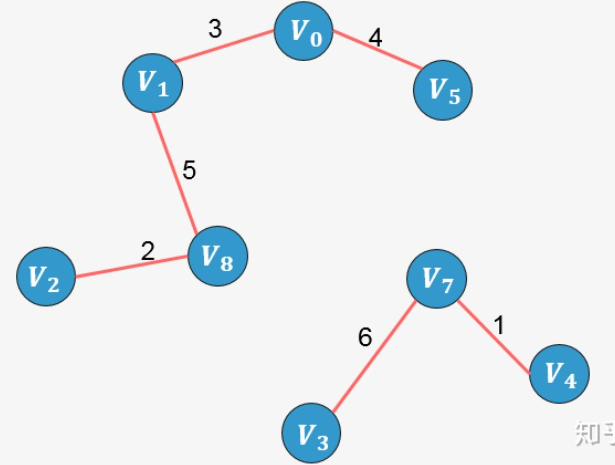
- 选择边 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s4cbra7X-1637250894589)(https://www.zhihu.com/equation?tex=V_1-V_6)]:没有形成环,则添加:
-
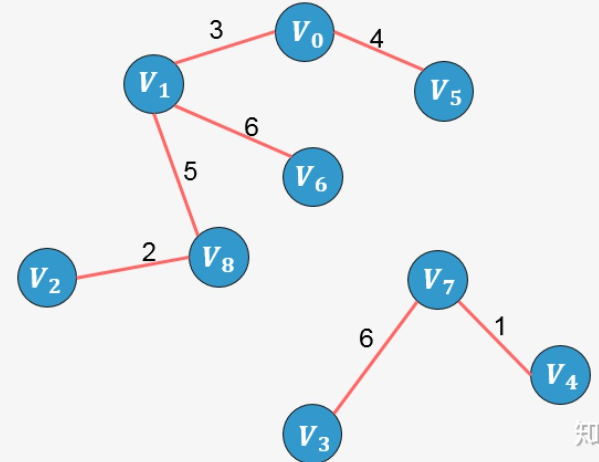
选择边 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KMDOKFGc-1637250894591)(https://www.zhihu.com/equation?tex=V_5-V_6)]:添加这条边将导致形成环,舍弃,不添加;
-
选择边 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kGbNLFJQ-1637250894592)(https://www.zhihu.com/equation?tex=V_1-V_2)]:添加这条边将导致形成环,舍弃,不添加;
-
选择边 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o6lZYa3q-1637250894593)(https://www.zhihu.com/equation?tex=V_6-V_7)]:没有形成环,则添加:

此时已经包含了图中顶点个数9减1条边,算法停止。
下面我们来用代码实现
int Find(int *parent, int f)
{
while( parent[f] > 0 )
{
f = parent[f];
}
return f;
}
// Kruskal算法生成最小生成树
void MiniSpanTree_Kruskal(MGraph G)
{
int i, n, m;
Edge edges[MAGEDGE]; // 定义边集数组
int parent[MAXVEX]; // 定义parent数组用来判断边与边是否形成环路
int eCount = 0;
for( i=0; i < G.numVertexes; i++ )
{
parent[i] = 0;
}
for( i=0; i < G.numEdges; i++ )
{
n = Find(parent, edges[i].begin); // 4 2 0 1 5 3 8 6 6 6 7
m = Find(parent, edges[i].end); // 7 8 1 5 8 7 6 6 6 7 7
if( n != m ) // 如果n==m,则形成环路,不满足!
{
parent[n] = m; // 将此边的结尾顶点放入下标为起点的parent数组中,表示此顶点已经在生成树集合中
printf("(%d, %d) %d ", edges[i].begin, edges[i].end, edges[i].weight);
++eCount;
if( eCount == (G.numVertexes-1)){
break;
}
}
}
}
时间复杂度分析
O(ElogE)或者O(ElogV),其中E代表图中的边的数目,V代表图中的顶点数目。对图中的边按照非降序排列需要O(ElogE)的时间。排序后遍历所有的边并判断添加边是否构成环,判断添加一条边是否构成环最坏情况下需要O(logV),关于这个复杂度等到景禹给你们谈并查集的时候再分析;因此,总的时间复杂度为O(ElogE + ElogV),其中E的值最大为V(V-1)/2,因此O(logV) 等于 O(logE)。因此,总的时间复杂度为O(ElogE) 或者O(ElogV)。
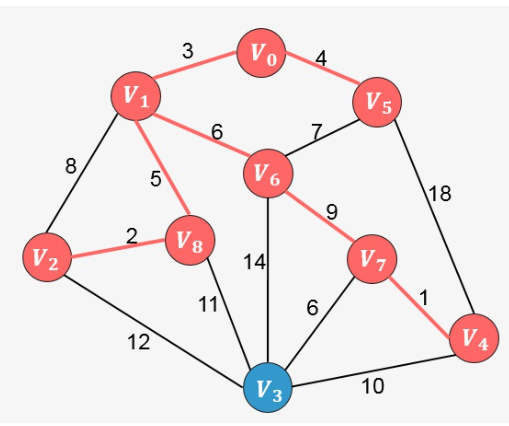
普里姆算法在找最小生成树时,将顶点分为两类,一类是在查找的过程中已经包含在生成树中的顶点(假设为 A 类),剩下的为另一类(假设为 B 类)。
对于给定的连通网,起始状态全部顶点都归为 B 类。在找最小生成树时,选定任意一个顶点作为起始点,并将之从 B 类移至 A 类;然后找出 B 类中到 A 类中的顶点之间权值最小的顶点,将之从 B 类移至 A 类,如此重复,直到 B 类中没有顶点为止。所走过的顶点和边就是该连通图的最小生成树。
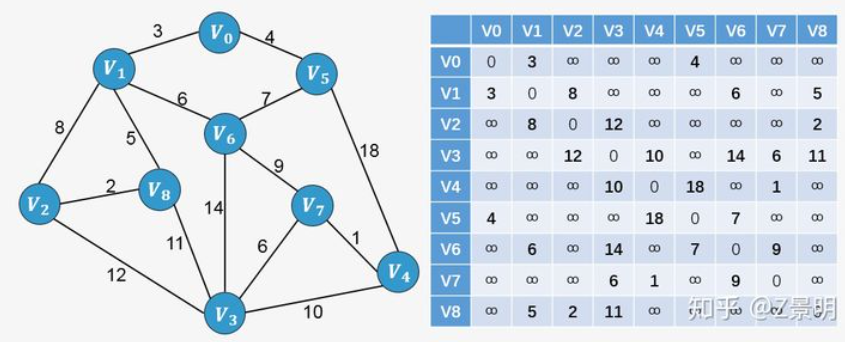
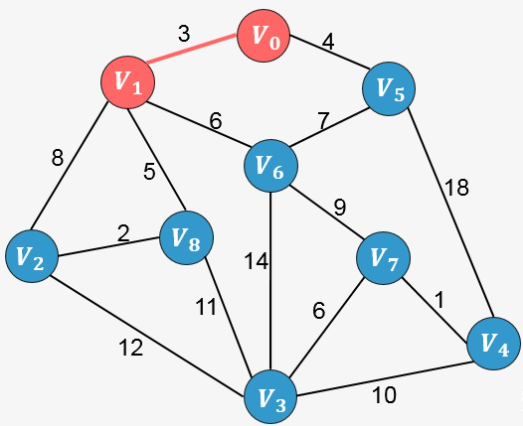
假如从顶点 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RGoQ502l-1637250894597)(https://www.zhihu.com/equation?tex=V_0)] 出发,顶点 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LJwwdbMe-1637250894598)(https://www.zhihu.com/equation?tex=V_1)] 、[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-inYCsUdQ-1637250894600)(https://www.zhihu.com/equation?tex=V_5)] 的权值分别为3、4,所以对于顶点 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-msplLJXk-1637250894601)(https://www.zhihu.com/equation?tex=V_0)] 来说,到顶点 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-G4vGHtfc-1637250894602)(https://www.zhihu.com/equation?tex=V_1)] 的权值最小,将顶点 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iQSwkPMO-1637250894603)(https://www.zhihu.com/equation?tex=V_1)] 加入到生成树中:
继续分析与顶点 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FpmDfn6m-1637250894605)(https://www.zhihu.com/equation?tex=V_0)] 和 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6503hs0Q-1637250894606)(https://www.zhihu.com/equation?tex=V_1)] 相邻的所有顶点(包括 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7DmsxCmU-1637250894607)(https://www.zhihu.com/equation?tex=V_2)] 、[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EZBQiZTR-1637250894608)(https://www.zhihu.com/equation?tex=V_5)]、[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iQC1fW6A-1637250894610)(https://www.zhihu.com/equation?tex=V_6)]、[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5QTKQPdD-1637250894611)(https://www.zhihu.com/equation?tex=V_8)] ),其中权值最小的为 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PSO9tGdK-1637250894613)(https://www.zhihu.com/equation?tex=V_5)] , 将 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TQYK3Mjr-1637250894614)(https://www.zhihu.com/equation?tex=V_5)] 添加到生成树当中:
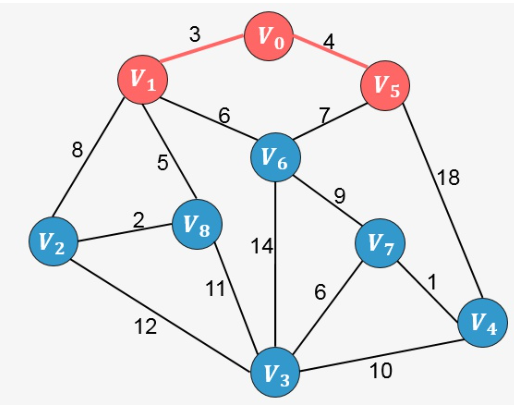
继续分析与顶点 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zMQL1ZqY-1637250894616)(https://www.zhihu.com/equation?tex=V_0)] 和 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IN6ee59T-1637250894617)(https://www.zhihu.com/equation?tex=V_1)] 、[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sH5PJBKb-1637250894618)(https://www.zhihu.com/equation?tex=V_5)] 相邻的所有顶点中权值最小的顶点,发现为 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-33jPLsix-1637250894619)(https://www.zhihu.com/equation?tex=V_8)] ,则添加到生成树当中。
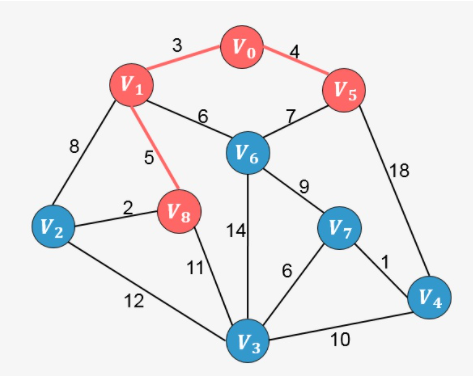
继续分析与生成树中已添加顶点相邻的顶点中权值最小的顶点,发现为 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FJmrMXkF-1637250894621)(https://www.zhihu.com/equation?tex=V_2)] ,则添加到生成树中:
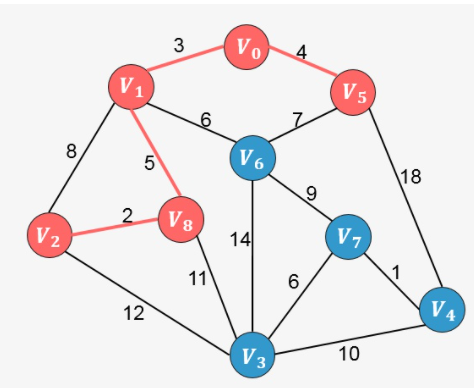
重复上面的过程,直到生成树中包含图中的所有顶点,我们直接看接下来的添加过程:
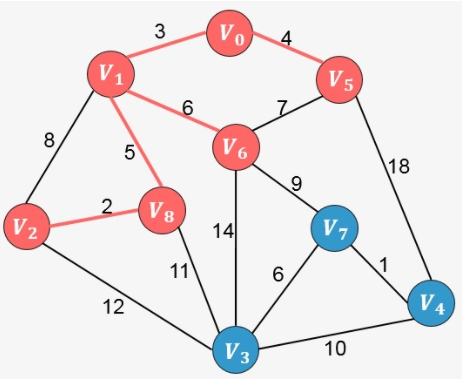
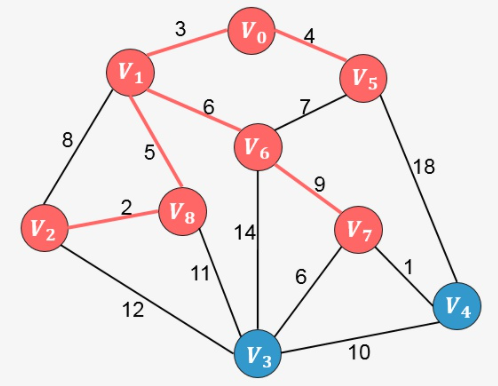

此时算法结束,我们找出了图中的最小生成树。
讲的真好!!!
搬运的视频,可以关注下这个,讲数据结构讲的真的好!
Prim算法执行过程。
Prim算法代码实现
// Prim算法生成最小生成树
void MiniSpanTree_Prim(MGraph G)
{
int min, i, j, k;
int adjvex[MAXVEX]; // 保存相关顶点下标
int lowcost[MAXVEX]; // 保存相关顶点间边的权值
lowcost[0] = 0; // V0作为最小生成树的根开始遍历,权值为0(0,3,,,,4,,,)
adjvex[0] = 0; // V0第一个加入
// 初始化操作
for( i=1; i < G.numVertexes; i++ )
{
lowcost[i] = G.arc[0][i]; // 将邻接矩阵第0行所有权值先加入数组
adjvex[i] = 0; // 初始化全部先为V0的下标
}
// 真正构造最小生成树的过程
for( i=1; i < G.numVertexes; i++ )
{
min = INFINITY; // 初始化最小权值为65535等不可能数值
j = 1;
k = 0;
// 遍历全部顶点
while( j < G.numVertexes )
{
// 找出lowcost数组已存储的最小权值
if( lowcost[j]!=0 && lowcost[j] < min )
{
min = lowcost[j];
k = j; // 将发现的最小权值的下标存入k,以待使用。
}
j++;
}
//K的取值依次为:1,5,8,2,6,7,4,3
// 打印当前顶点边中权值最小的边
printf(“(%d,%d)”, adjvex[k], k);(0,1)
lowcost[k] = 0; // 将当前顶点的权值设置为0,表示此顶点已经完成任务,进行下一个顶点的遍历(0,0,,,,4,,,)
// 邻接矩阵k行逐个遍历全部顶点(k=1,)
for( j=1; j < G.numVertexes; j++ )
{
if( lowcost[j]!=0 && G.arc[k][j] < lowcost[j] )
{
lowcost[j] = G.arc[k][j];
adjvex[j] = k;
}
}
}
}
时间复杂度分析
上面的代码中,当 i == 1的时候,内层的 while 与 for 循环中 j 的取值范围是从 1 到 n-1,内循环一共计算了 2(n-1) 次,其中n为图中的顶点个数;
当 i == 2 的时候,内层循环还是一共计算 2(n-1) 次;
以此类推…
i 取最大值 n -1,内层循环还是一共计算 2(n-1) 次;
所以,整体的执行次数就是 (n-1) * 2(n-1),Prim算法的复杂度是 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8fWO7UYu-1637250894629)(https://www.zhihu.com/equation?tex=O%28n%5E2%29)] 级别的。
某公司规模不断扩大,在全国各地设立了多个分公司,为了提高公司的工作效率,使各分公司之间的信息可以更快、更准确的进行交流,该公司决定要在各分公司之间架设网络,由于地理位置和距离等其他因素,使各个分公司之间架设网线的费用不同,公司想各分公司之间架设网线的费用降到最低,那么应该怎样来设计各分公司及总公司之间的线路?该公司的所有分公司及总公司的所在位置如下图所示,顶点代表位置及公司名称,边表示可以架设网线的路线,边上的数字代表架设该网线所需要的各种花费的总和。这样就构成了一个带权的连通图,从而问题就转化为求所得到的带权连通图的最小生成树。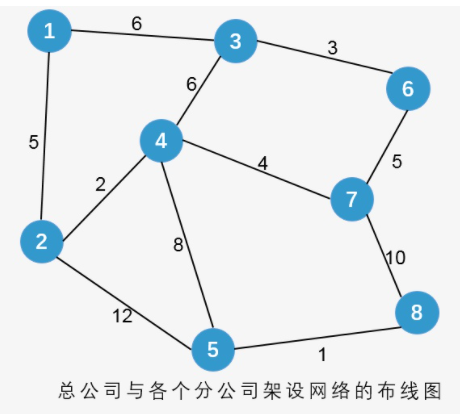
这其实就是给你个连通图,让你找最小生成树嘛,上面学的那两个算法都可以实现,进行微调即可,C语言还不是太熟悉,以后更新Java的再写代码~
对比两个算法,克鲁斯卡尔算法主要是针对边来展开,边数少时效率会非常高,所以对于稀疏图有很大的优势;而普里姆算法对于稠密图,即边数非常多的情况会更好一些
======================================================================
对于网图来说,最短路径,是指两顶点之间经过的边上权值之和最少的路径,并且我们称路径上的第一个顶点是源点,最后一个顶点是终点
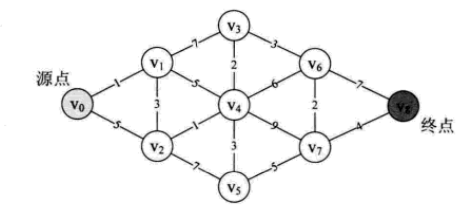
Dijkstra是用来求单源最短路径的
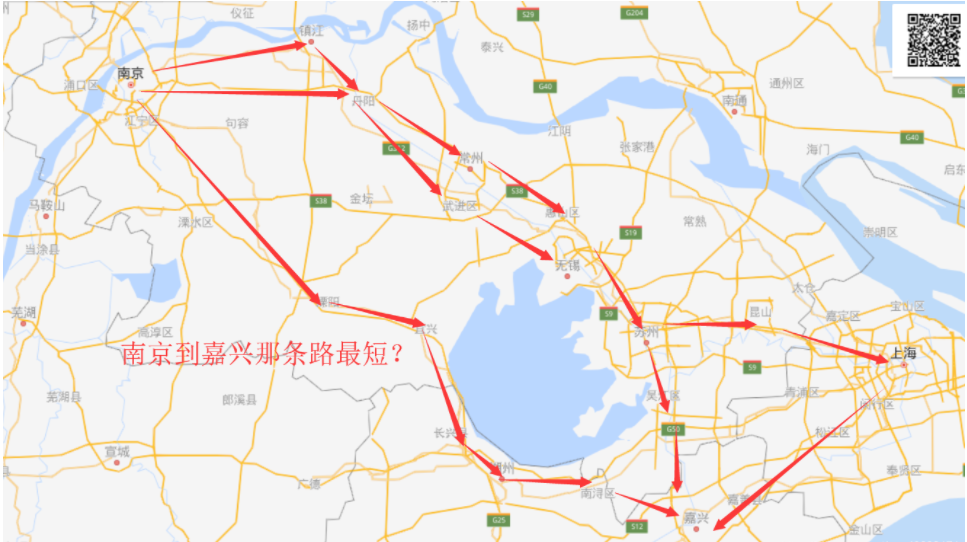
就拿上图来说,假如直到的路径和长度已知,那么可以使用dijkstra算法计算南京到图中所有节点的最短距离。
单源什么意思?
- 从一个顶点出发,Dijkstra算法只能求一个顶点到其他点的最短距离而不能任意两点。
摘自:
最短路径算法-迪杰斯特拉(Dijkstra)算法 - 知乎 (zhihu.com)
迪杰斯特拉(Dijkstra)算法是典型最短路径算法,用于计算一个节点到其他节点的最短路径。它的主要特点是以起始点为中心向外层层扩展(广度优先遍历思想),直到扩展到终点为止。
基本思想
- 通过Dijkstra计算图G中的最短路径时,需要指定一个起点D(即从顶点D开始计算)。
- 此外,引进两个数组S和U。S的作用是记录已求出最短路径的顶点(以及相应的最短路径长度),而U则是记录还未求出最短路径的顶点(以及该顶点到起点D的距离)。
- 初始时,数组S中只有起点D;数组U中是除起点D之外的顶点,并且数组U中记录各顶点到起点D的距离。如果顶点与起点D不相邻,距离为无穷大。
- 然后,从数组U中找出路径最短的顶点K,并将其加入到数组S中;同时,从数组U中移除顶点K。接着,更新数组U中的各顶点到起点D的距离。
- 重复第4步操作,直到遍历完所有顶点。
迪杰斯特拉(Dijkstra)算法图解
我在叠一层,哈哈哈
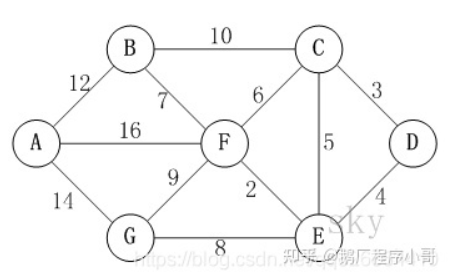
以上图为例,来对迪杰斯特拉进行算法演示(以顶点D为起点)。
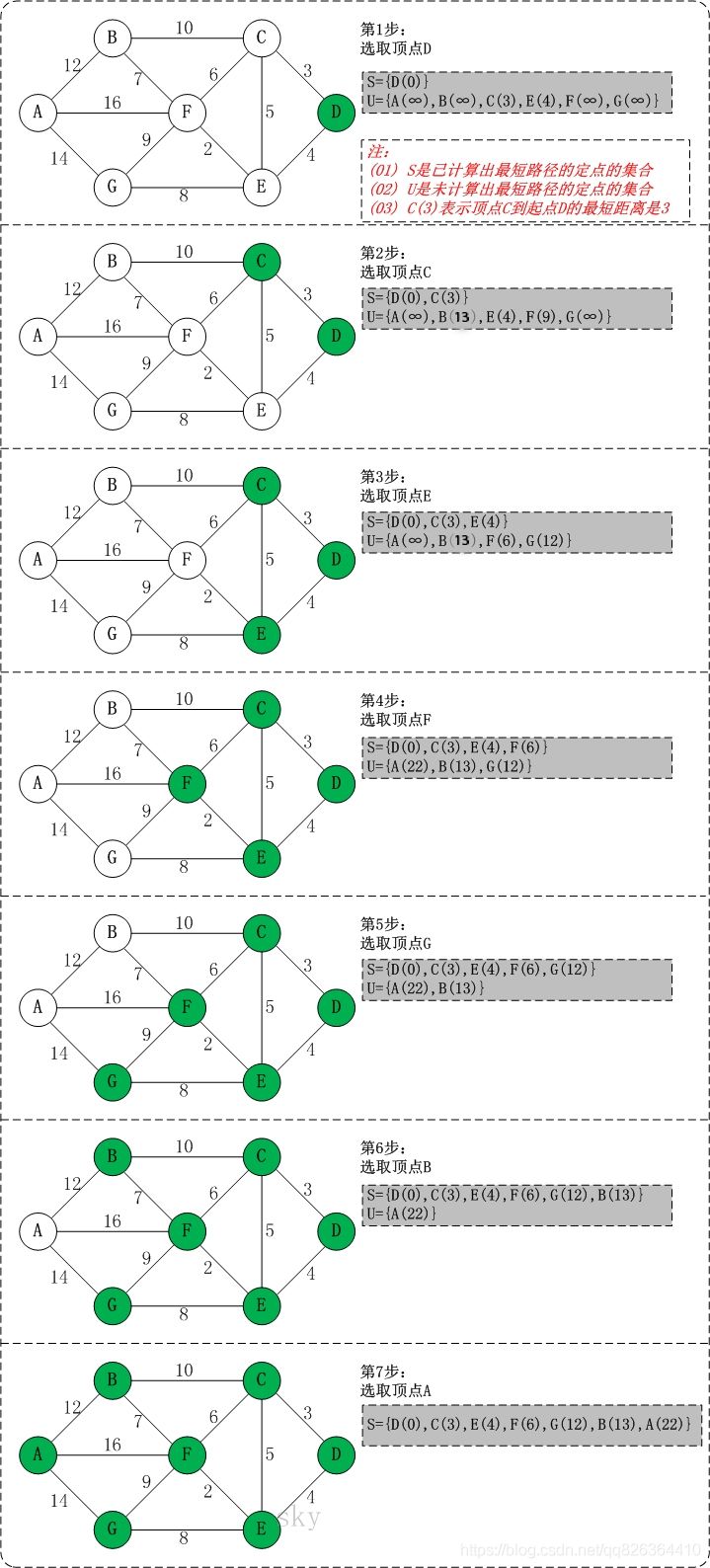
看图很清晰了!
Floyd主要计算多源最短路径。
算法的具体思想为:
邻接矩阵dist储存路径,同时最终状态代表点点的最短路径。如果没有直接相连的两点那么默认为一个很大的值(不要溢出)!而自己的长度为0.
- 从
第1个到第n个点依次加入图中。每个点加入进行试探是否有路径长度被更改。
- 而上述试探具体方法为遍历图中每一个点(i,j双重循环),判断每一个点对距离是否因为加入的点而发生最小距离变化。如果发生改变,那么两点(i,j)距离就更改。
- 重复上述直到最后插点试探完成。
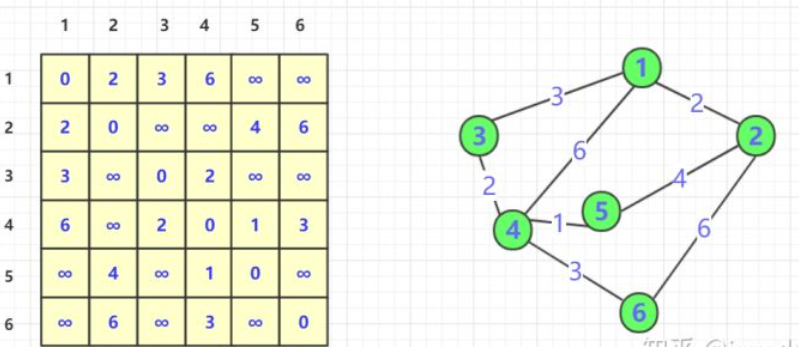
默认的最短长度初始为邻接矩阵初始状态
- 加入第一个节点
1,大家可以发现,由于1的加入,使得本来不连通的2,3点对和2,4点对变得联通,并且加入1后距离为当前最小。(可以很直观加入5之后2,4,更短但是还没加入)。为了更好的描述其实此时的直接联通点多了两条。(2,3)和(2,4).我们在dp中不管这个结果是通过前面那些步骤来的,但是在这个状态,这两点的最短距离就算它!
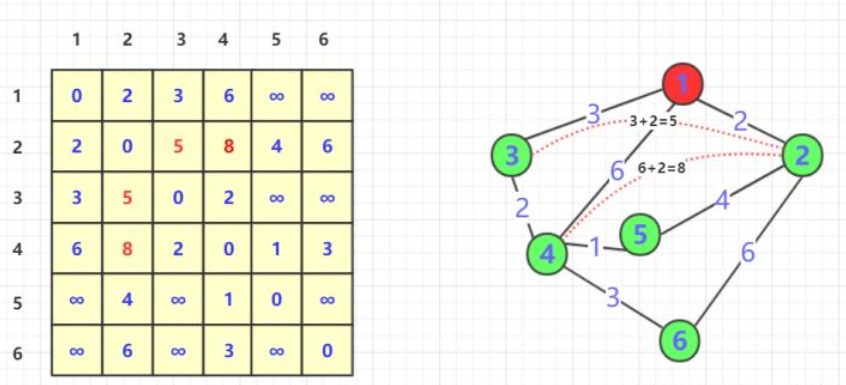
核心代码
public class floyd {
static int max = 66666;// 别Intege.max 两个相加越界为负
public static void main(String[] args) {
int dist[][] = {
{ 0, 2, 3, 6, max, max },
{ 2, 0, max, max,4, 6 },
{ 3, max, 0, 2, max, max },
{ 6, max, 2, 0, 1, 3 },
{ max, 4, max, 1, 0, max },
{ max, 6, max, 3, max, 0 } };// 地图
// 6个
for (int k = 0; k < 6; k++)// 加入滴k个节点
{
for (int i = 0; i < 6; i++)// 松弛I行
{
for (int j = 0; j < 6; j++)// 松弛i列
{
dist[i][j] = Math.min(dist[i][j], dist[i][k] + dist[k][j]);
}
}
}
// 输出
for (int i = 0; i < 6; i++) {
System.out.print(“节点”+(i+1)+" 的最短路径");
for (int j = 0; j < 6; j++) {
System.out.print(dist[i][j]+" ");
}
System.out.println();
}
}
}
======================================================================
在一个表示工程的有向图中,有顶点表示活动,用弧表示活动之间的优先关系,这样的有向图为顶点表示活动的网,我们称为AOV网。
AOV网中的弧表示活动之间存在的某种制约关系。
所谓拓扑排序,其实就是对一个有向图构造拓扑序列的过程。
设G=(V,E)是一个具有n个顶点的有向图,V中的顶点序列V1, V2,Vn,满足若从顶点vi到v)有一条路径,则在顶点序列中顶点Vi 必在顶点vj之前。则我们称这样的顶点序列为一个拓扑序列
对AOV网进行拓扑排序的基本思路是:从AOV网中选择一个入度为0的顶点输出,然后删去此顶点,并删除以此顶点为尾的弧,继续重复此步骤,直到输出全部顶点或者AOV网中不存在入度为0的顶点为止。
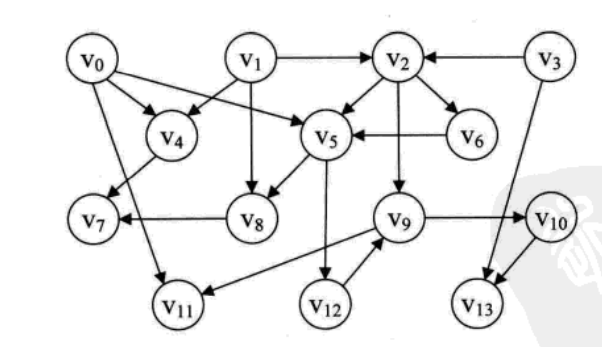
代码不妨了,以后更新Java的
一个AOV网的拓扑序列不是唯一的
检测AOV网中是否存在环方法
对有向图构造其顶点的拓扑有序序列,若网中所有顶点都在它的拓扑有序序列中,则该AOV网必定不存在环。
======================================================================
把工程计划表示为边表示活动的网络,即AOE网,用顶点
表示事件,弧表示活动,弧的权表示活动持续时间。
AOE网中没用入边的顶点称为始点或源点,没有出边的顶点称为终点或汇点
v0,v1,…,v9分别表示事件,<v0,v1>,<v0,v2>,…<v8,v9>表示一个活动,用a0,a1…a12表示,它们的值代表活动持续时间

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
)7.7.2拓扑排序算法
对AOV网进行拓扑排序的基本思路是:从AOV网中选择一个入度为0的顶点输出,然后删去此顶点,并删除以此顶点为尾的弧,继续重复此步骤,直到输出全部顶点或者AOV网中不存在入度为0的顶点为止。
代码不妨了,以后更新Java的
一个AOV网的拓扑序列不是唯一的
检测AOV网中是否存在环方法
对有向图构造其顶点的拓扑有序序列,若网中所有顶点都在它的拓扑有序序列中,则该AOV网必定不存在环。
======================================================================
把工程计划表示为边表示活动的网络,即AOE网,用顶点
表示事件,弧表示活动,弧的权表示活动持续时间。
AOE网中没用入边的顶点称为始点或源点,没有出边的顶点称为终点或汇点
v0,v1,…,v9分别表示事件,<v0,v1>,<v0,v2>,…<v8,v9>表示一个活动,用a0,a1…a12表示,它们的值代表活动持续时间
[外链图片转存中…(img-0vMtSmHe-1714193197573)]
[外链图片转存中…(img-V74Gn2td-1714193197574)]
[外链图片转存中…(img-1SRKnE55-1714193197574)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新














 2108
2108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









