






前不久DeepSeek-V3-0324公布,今天一篇讲RM奖励模型的论文也透露了,是不是真的R2要来了,能不能卷死Gemini 2.5 Pro和ChatGPT 4o,期待期待。

以下论文完全由Gemini 2.5 Pro友情赞助,应该是目前用过很满意的模型,超过Grok和ChatGPT(暂时)。
目前9.9刀可以用两个月,还送2T云盘。
老大哥赶紧卷死OpenAI,ChatGPT啥时候降价啊。

你好!很高兴和你一起深入了解 DeepSeek AI 的这篇关于奖励模型(Reward Model, RM)的论文。作为 AI 爱好者,你会发现这篇论文触及了当前大语言模型(LLM)训练中的一个核心环节——如何通过强化学习(RL)让模型更好地对齐人类偏好和指令,而奖励模型正是这个过程中的“裁判”。
1. 背景:奖励模型与挑战
-
RLHF 与奖励模型:现在很多强大的 LLM(如 GPT 系列、Claude、Gemini 等)都用到了 RLHF(基于人类反馈的强化学习)或类似技术进行微调。简单说,就是先训练一个奖励模型 (RM) 来模仿人类对 LLM 输出的偏好(比如判断哪个回答更好,或者给回答打分),然后用这个 RM 作为“奖励信号”去指导 LLM 的进一步学习,让 LLM 生成更符合人类期望的内容。【看来目前的技术体系下,纯粹的RL,就是R1-Zero的路子还是不太行,依然得把大模型当成一个记忆力满分,理解力60分的小朋友看待】
-
挑战:通用性与准确性:
-
特定领域 vs. 通用领域:对于一些有明确规则或容易验证的任务(如数学计算、代码生成),设计高质量的 RM 相对容易。但对于通用领域(如开放式问答、创意写作、复杂指令遵循),评价标准复杂多样,没有标准答案,训练准确的 RM 非常困难。
-
推理时扩展性:我们希望 RM 不仅在训练时通过增大模型规模来提升性能(训练时扩展),也能在推理时(即实际使用 RM 打分时)通过投入更多计算资源(如多次采样、更复杂的处理)来获得更准确的奖励信号(推理时扩展)。现有的很多 RM 方法在这方面表现不佳。
-
2. 论文方法:Pointwise GRM + SPCT + 推理扩展
面对这些挑战,DeepSeek 团队提出了他们的解决方案,主要包含三个部分:
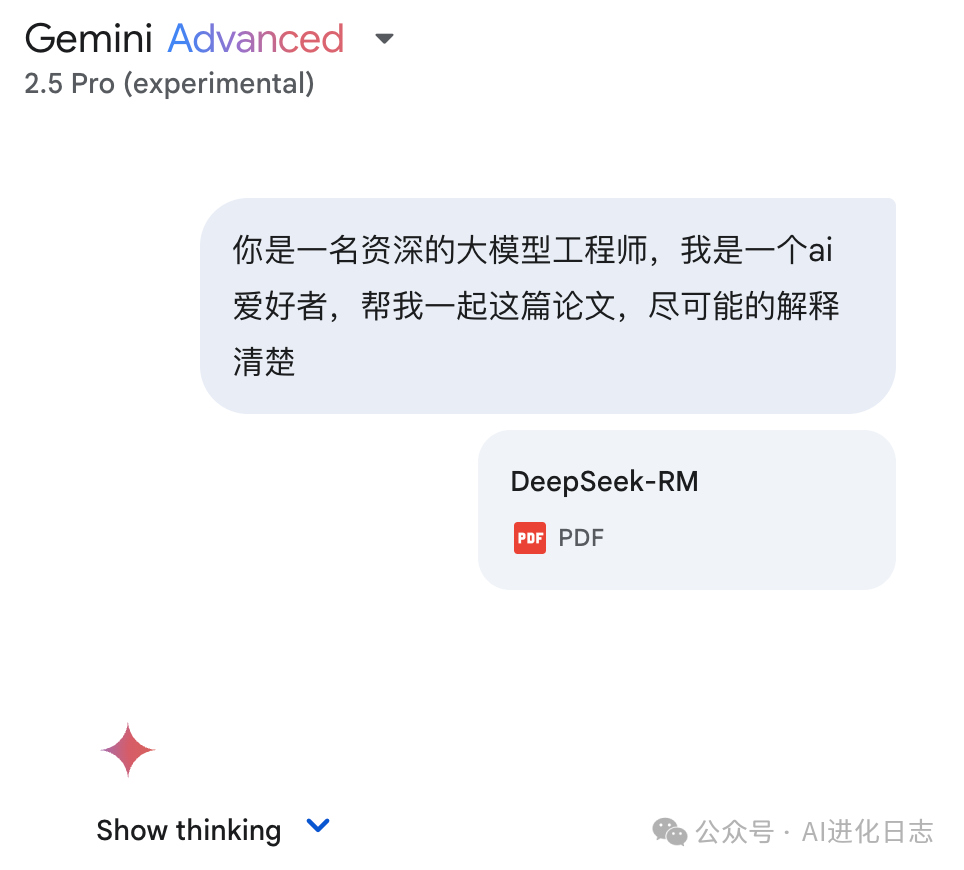
a) 奖励模型架构:Pointwise Generative Reward Modeling (GRM)
-
为什么选 GRM?
-
Generative (生成式):与传统的只输出一个分数 (Scalar RM) 或分数加简单文本 (Semi-Scalar RM) 不同,GRM 会生成一段详细的文本评论 (Critique)来解释为什么给出这个分数。这使得奖励信号更丰富、更可解释。
-
Pointwise (逐点式):它为每一个候选回答都独立生成评论和分数,而不是像 Pairwise (成对式) 方法那样只比较两个回答的优劣。
-
-
优势:
-
灵活性 (Input Flexible):可以方便地处理单个回答、一对回答或多个回答的评分任务,输入形式统一。
-
可扩展性潜力 (Inference-Time Scalable):因为是生成式的,可以通过多次采样生成不同的评论(可能基于不同的侧重点或“原则”),为推理时扩展提供了可能。相比之下,Scalar RM 多次运行通常只得到同一个分数。 (见论文图 2)
-
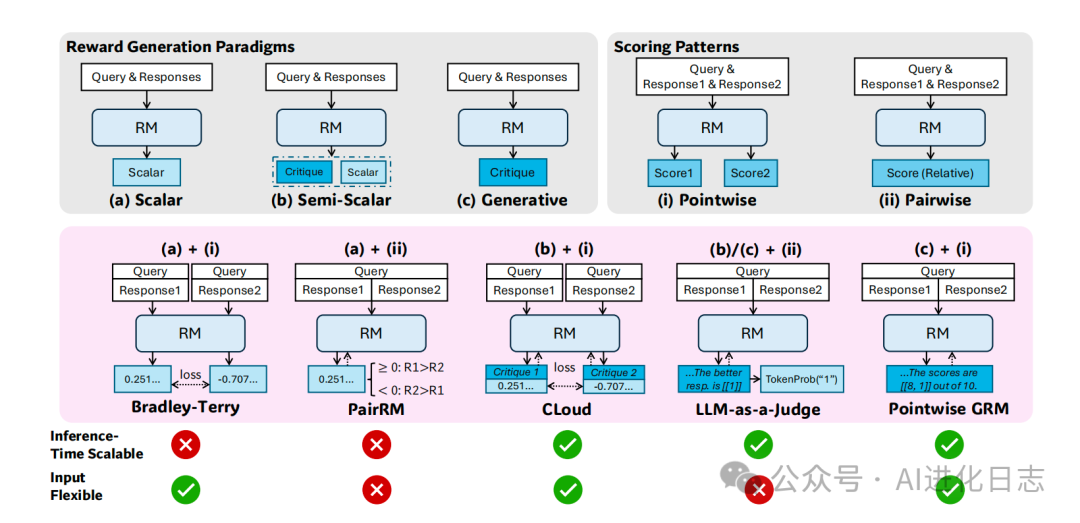
b) 核心训练方法:Self-Principled Critique Tuning (SPCT)
这是论文最核心的创新。目标是让 GRM 学会自己生成评价原则 (Principles)并基于这些原则给出准确的评论 (Critiques),从而实现高质量且可扩展的奖励判断。
-
核心思想:把“评价原则”也视为模型生成的一部分,而不是预先设定好的。模型需要根据当前的问题 (Query)和回答 (Responses),自适应地生成最相关的评价原则和权重,然后再依据这些原则进行打分和评论。
-
训练过程 (见论文图 3):
-
冷启动 (Rejective Fine-Tuning, RFT):先用一些已有的 RM 数据(包含单/双/多回答的偏好数据)和通用指令数据进行初步微调。这里会用到一个技巧:让一个预训练好的 GRM 对数据进行多次采样生成评论和分数,然后拒绝 (Reject)掉那些预测结果与真实偏好不符的、或者模型每次都能轻易预测对的(太简单)的样本,用筛选后的数据进行训练。这一步主要是让模型学会基本的原则生成和评论格式。
-
在线强化学习 (Rule-Based Online RL):使用类似 GRPO (一种 RL 算法) 的方法进行在线优化。模型根据输入生成原则和评论,提取预测分数,然后根据预设规则(比如,预测的分数是否正确反映了真实偏好)计算一个简单的奖励信号(+1 或 -1),用这个信号来进一步优化模型。这一步能显著提升模型生成高质量、自洽的原则和评论的能力,并培养其推理时可扩展的行为。
-
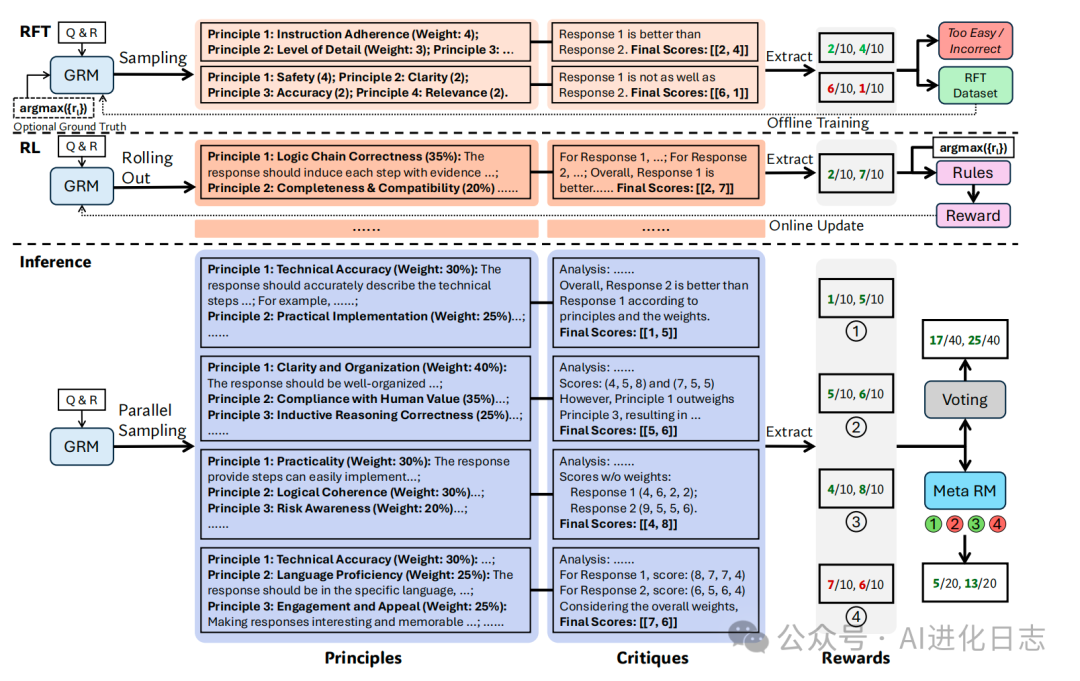
c) 推理时扩展策略
训练好的 DeepSeek-GRM 如何在推理时利用更多计算资源提升性能?
-
并行采样 (Parallel Sampling):对于同一组输入(Query 和 Responses),多次(k 次)运行 DeepSeek-GRM 模型(可以加一点随机性,如 temperature > 0)。由于 SPCT 训练出的模型能生成不同的原则和评论,每次采样可能得到不同的分数。
-
投票 (Voting):将 k 次采样得到的分数进行聚合。最简单的方式是直接求和(或平均)。由于单次打分范围有限(如 1-10),投票实际上扩展了最终分数的范围和粒度,使得评分更精细。
-
Meta RM 引导投票 (Meta RM Guided Voting):更进一步,他们还训练了一个额外的、小型的 Meta RM。这个 Meta RM 的任务是评价 DeepSeek-GRM 单次生成的原则和评论的质量(判断这次打分是否“靠谱”)。在投票时,可以先用 Meta RM 筛选掉质量低的采样结果,只用得分高的前 k_{meta} (k_{meta} \le k) 个结果进行投票。这能有效提升投票的准确性和稳定性。
3. 主要成果与发现
-
SPCT 的有效性:实验证明,SPCT 显著提升了 GRM 的质量和推理时可扩展性,优于之前的多种方法(包括 Scalar RM, Pairwise RM, LLM-as-a-Judge 等)。(见论文表 2)
-
DeepSeek-GRM 的性能:基于 Gemma-2-27B 训练的 DeepSeek-GRM-27B 在多个 RM 基准测试(如 Reward Bench, PPE, RMB)上表现出色,性能接近甚至超过了一些更强的闭源模型(如 GPT-4o)和参数量远大于它的模型(如 Nemotron-4-340B-Reward)。
-
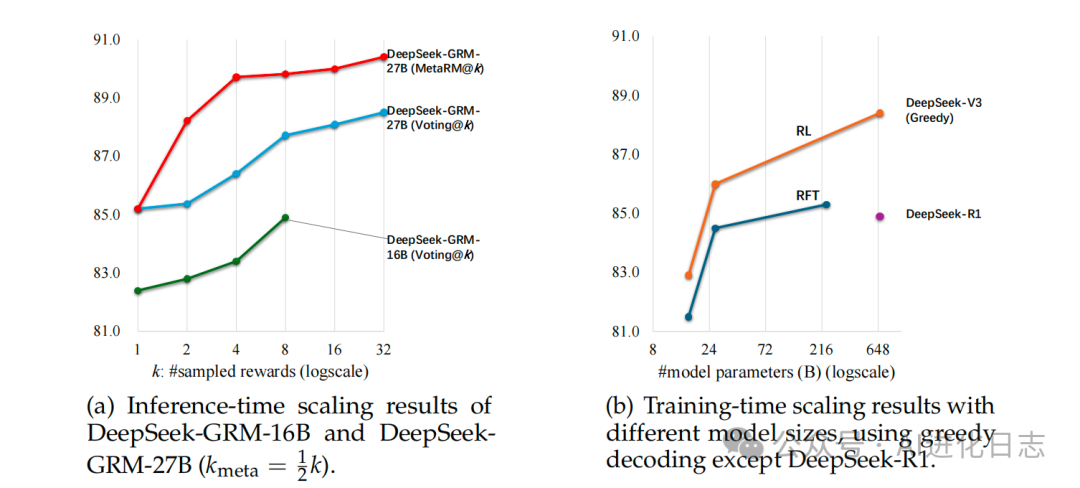
推理时扩展 > 训练时扩展:论文展示了一个非常有趣的发现 (见论文图 4):通过增加推理时的采样次数(如 Voting@32 或 MetaRM@8),27B 的 DeepSeek-GRM 在 Reward Bench 上的性能可以超过通过简单增大模型规模(训练时扩展)得到的 671B 模型 (DeepSeek-V3) 的性能。这表明,对于 RM 任务,有效的推理时扩展策略可能比一味增大模型尺寸更具性价比。
-
Meta RM 的作用:Meta RM 引导的投票确实比简单的投票效果更好,能进一步提升性能。(见论文图 1, 表 3)
-
通用性与偏差:相比 Scalar 和 Semi-Scalar RM,DeepSeek-GRM 在不同领域的表现更均衡,没有出现严重的领域偏差(比如在某些任务上特别好,在另一些上特别差)。
4. 局限性与未来方向
-
效率问题:生成式模型(GRM)比标量模型(Scalar RM)在推理时慢得多,这限制了它在需要快速反馈的在线 RL 训练中的应用。不过,并行采样本身不会显著增加延迟。
-
特定任务性能:在一些需要严格验证的任务上(如数学),GRM 可能仍不如专门优化的 Scalar RM。论文提到引入参考答案或更强的推理能力可能缓解这个问题。
-
未来方向:
-
结合工具(如计算器、搜索引擎)增强 GRM 的准确性。
-
将原则生成和评论生成分解,提高效率。
-
将 GRM 用于 LLM 的离线评估,提供可解释的弱点分析。
-
探索 GRM 与需要评估的模型进行推理时协同扩展 (co-scaling)。
-
5. 总结
这篇论文提出了 SPCT这一创新的训练方法,成功地训练出了 DeepSeek-GRM这种通用、灵活且具有强大推理时可扩展性的奖励模型。它证明了通过精心设计的学习方法和推理策略,即使是中等规模的模型,也能通过增加推理计算量达到甚至超越巨大模型的性能,为未来构建更高效、更准确的 AI 对齐系统提供了新的思路。特别是“自生成原则”和“Meta RM 引导投票”这两个点,非常有启发性。
希望这个解读对你理解这篇论文有所帮助!如果你对某个具体细节感兴趣,我们可以继续深入讨论。
然后是一个所谓消融研究
"消融研究" (Ablation Study) 在机器学习和人工智能研究中是一个非常常见的实验方法。它的核心思想是:系统性地移除或修改模型/系统中的某个组成部分(或者说“切除”掉某个模块),然后观察移除后对整体性能的影响。
在 DeepSeek-RM 这篇论文中,消融研究代表了:
-
验证各个组件的贡献:论文提出的 SPCT 方法包含多个关键部分,比如:
-
自生成原则 (Principle Generation)
-
冷启动阶段的拒绝采样 (Rejective Sampling in RFT)
-
拒绝采样中的提示采样 (Hinted Sampling) 和非提示采样 (Non-Hinted Sampling)
-
在线强化学习阶段 (Rule-Based RL)
-
通用指令数据 (General Instruction Data) 通过逐一移除或改变这些组件,研究人员可以量化地了解每个部分对最终模型性能(如准确率、可扩展性)到底有多大贡献。
-
-
理解方法的工作机制:通过观察移除某个组件后的性能下降程度,可以判断该组件是否是方法成功的关键。例如,论文的消融研究(见表 4 和附录 D.3)发现:
-
即使没有 RFT 冷启动,在线 RL 阶段仍然能显著提升性能,说明在线 RL 非常重要。
- 原则生成
对于模型的普通推理(Greedy Decoding)和推理时扩展都至关重要,去掉后性能下降明显。
- 通用指令数据
是基础,去掉后性能大幅下降。
-
非提示采样似乎比提示采样更重要,可能是因为提示采样有时会让模型“抄近道”。
-
-
增强结论的可信度:消融研究证明了作者提出的各个设计并非随意添加,而是确实对提升模型效果起到了作用,从而增强了整个研究方法和结论的说服力。
简单来说,消融研究就像是做实验,通过“控制变量”的方式,搞清楚一个复杂系统(比如 SPCT 训练方法)中,到底是哪些部分真正起了关键作用,以及它们的作用有多大。这有助于研究人员和读者理解为什么这个新方法有效,以及哪些设计是必不可少的。

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









