






一、知识蒸馏技术简介
知识蒸馏(Knowledge Distillation)作为一种有效的模型压缩和加速技术,应运而生。它通过将一个复杂的大模型(称为教师模型,Teacher Model)的知识转移到一个较小的模型(称为学生模型,Student Model)中,使得学生模型在保持较小规模的同时,能够尽可能地接近教师模型的性能。
简单来说,知识蒸馏就像是一场 “学习传承” 的过程。教师模型就如同一位知识渊博、经验丰富的老师,经过大量数据的训练,掌握了复杂的数据模式和特征知识。而学生模型则是一位努力学习的学生,它的结构相对简单,计算成本较低,但渴望从教师模型那里获取知识,提升自己的能力。在这个过程中,教师模型将自己学到的知识以一种特殊的方式传授给学生模型,让学生模型能够在资源受限的情况下,也能表现出良好的性能。
“知识蒸馏技术的演进可分为三个阶段:
- 传统蒸馏(2015-2018):以Hinton提出的Softmax温度调控为标志,通过软标签迁移实现模型压缩。
- 特征与关系蒸馏(2019-2021):引入中间层特征匹配(FitNets)、关系建模(RKD)等方法,提升知识传递效率。
- 多模态与动态蒸馏(2022至今):跨模态蒸馏(MKD)、自监督蒸馏(SSD)等新范式推动技术向智能化、自动化方向发展。”
二、知识蒸馏的基本概念
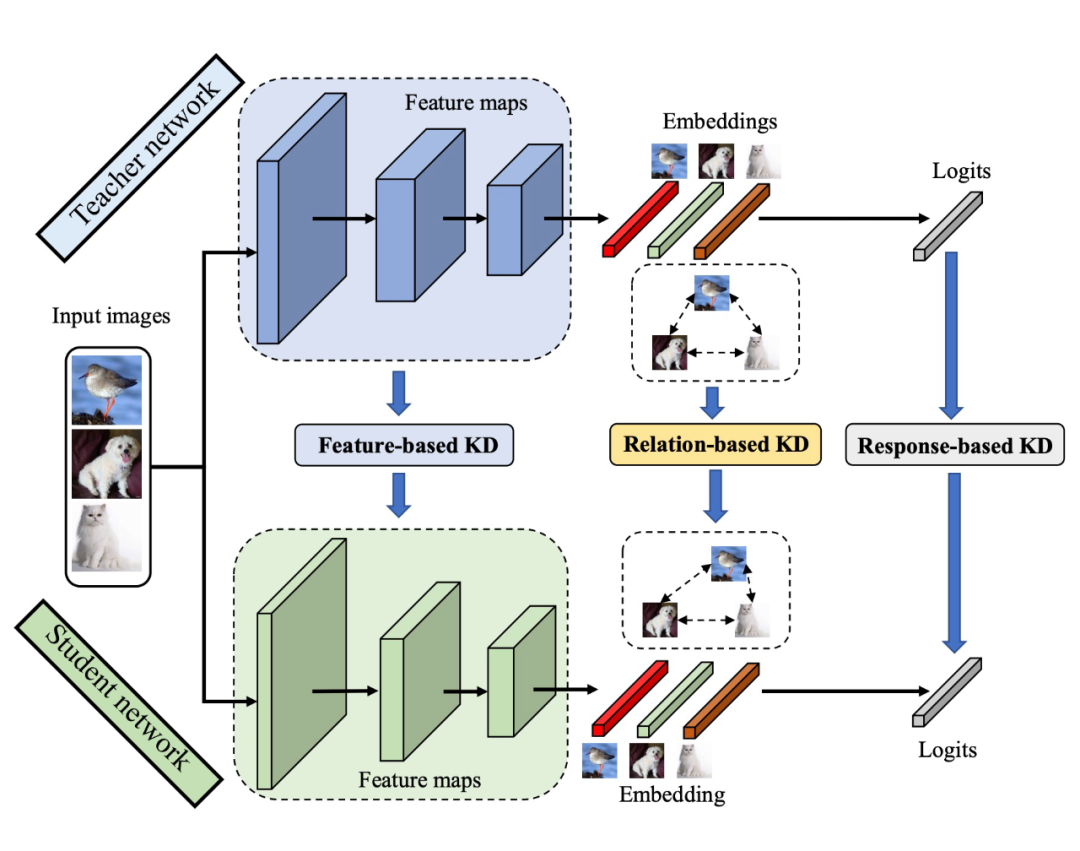
知识蒸馏是一种模型压缩和知识迁移技术,旨在将教师模型的知识转移到学生模型,使学生模型在较小的计算成本下,达到与教师模型相近的性能。其核心思想是利用教师模型的输出(如软标签、中间层特征、注意力权重等)作为额外监督信号,指导学生模型学习。
(二)软标签与硬标签
在知识蒸馏中,标签分为硬标签和软标签。硬标签是传统的类别标签,如在图像分类任务中,一张猫的图片硬标签为“猫”类别对应的独热编码(one - hot encoding)。软标签则是教师模型输出的类别概率分布,如教师模型认为一张图片是猫的概率为0.8,是狗的概率为0.15,是其他动物的概率为0.05,这组概率值就是软标签。软标签包含更多信息,如类别之间的相对关系和不确定性,有助于学生模型更好地学习特征表示和决策边界。
(三)教师-学生模型结构
知识蒸馏采用教师 - 学生模型结构,教师模型通常是训练好的大型复杂模型,具有强大的表达能力和较高的性能;学生模型是参数量较小、结构简单的模型。在蒸馏过程中,将相同输入同时输入教师模型和学生模型,教师模型为学生模型提供知识指导,通过最小化学生模型输出与教师模型输出之间的差异(如使用交叉熵损失、均方误差损失等),优化学生模型参数,使学生模型学习教师模型的知识。
三、知识蒸馏的原理剖析
(一)软目标的正则化作用
- 标签平滑正则化:传统训练中,模型过于依赖硬标签,易导致过拟合。软目标通过标签平滑训练提供正则化,避免模型过分相信训练样本真实标签。例如,在图像分类任务中,若真实标签为“猫”,硬标签表示为[1, 0, 0, …, 0],软目标可将其平滑为[0.9, 0.05, 0.05, …, 0],使模型在学习时考虑更多类别信息,防止过拟合。
- 置信度惩罚正则化:软目标能让学生模型获得更好的泛化能力,主要依赖教师模型对正确预测的信心。当教师模型对某样本预测具有高置信度时,学生模型学习该软目标,可强化正确预测;当教师模型置信度低时,学生模型学习该软目标,可提高对不确定样本的处理能力,增强泛化能力。
(二)提供“特权信息”
教师模型训练过程中,能学习到数据中的“暗知识”,如数据分布规律、特征之间的隐含关系等。这些知识以软目标形式传递给学生模型,成为学生模型的“特权信息”。学生模型通过学习这些信息,能更快收敛到较好解,提升性能。例如在自然语言处理任务中,教师模型能学习到单词之间复杂语义关系,其输出软目标可指导学生模型学习这些关系,使学生模型在语义理解任务中表现更好。
(三)引导学生模型优化方向
从模型训练角度,软目标能引导学生模型优化方向。以图像分类任务为例,假设教师模型对某图像预测为类别A概率高,学生模型初始预测可能不同。通过最小化学生模型输出与教师模型软目标之间的差异(如使用KL散度),学生模型在反向传播过程中调整参数,使预测向教师模型软目标靠近,优化方向更明确,相比仅从原始数据学习,具有更高学习速度和更好性能。
四、知识蒸馏的方法分类
(一)基于知识形式的分类
- 输出特征知识蒸馏
- 逻辑单元和软目标知识:输出特征知识常指教师模型最后一层特征,包括逻辑单元和软目标知识。在目标分类任务中,知识蒸馏学习教师模型输出软目标知识,如在CIFAR - 10图像分类数据集上训练学生模型时,教师模型输出各类别的概率分布(软目标),学生模型学习该分布,使自身预测与教师模型接近,提高分类性能。
- 边界框回归知识和软目标知识(目标检测):在目标检测任务中,目标检测网络最后输出层包含区域建议网络(RPN)的边界框回归和区域分类网络(RCN)的软目标知识。边界框回归知识用于定位目标物体位置,软目标知识用于分类目标物体类别。例如在YOLO目标检测模型中,教师模型的边界框回归信息和类别概率分布可指导学生模型学习,提高学生模型在目标检测任务中的定位和分类准确性。
- 像素级软目标知识和空间上下文结构知识(目标分割):目标分割需对目标每个像素分类,且教师和学生模型输出特征尺寸可能不匹配,要求学生模型学习教师模型的空间上下文结构知识。如在U - Net目标分割模型中,教师模型输出的像素级软目标(每个像素属于不同类别的概率)和空间上下文信息(如不同区域之间关系)可帮助学生模型更好地进行目标分割,提高分割精度。
- 序列级输出概率分布(序列特征):在序列特征任务中,数据对齐时可使用帧级知识蒸馏,匹配教师和学生间输出离散化软目标;数据未对齐时,序列级知识蒸馏将教师模型得分最高的输出序列分布作为学生模型监督信号。例如在语音识别任务中,教师模型对语音序列的输出概率分布可指导学生模型学习,使学生模型更好地识别语音序列中的内容。
- 中间特征知识蒸馏
- Hint机制:教师软目标主要指导学生深层次网络层训练,在学生网络特征提取层指导较少。中间特征知识从教师中间网络层提取特征,充当学生模型中间层输出的提示(Hint)。最早使用该方法的是FitNets,其促使学生隐含层能预测出与教师隐含层相近输出。例如在一个多层卷积神经网络中,教师模型中间层的特征图包含丰富图像特征信息,学生模型通过学习这些特征图,可提高自身特征提取能力,使模型性能提升。
- 网络层迁移策略:在网络层迁移点上,可隔层、逐层和逐块地将教师中间特征知识转移到学生模型中,或仅迁移教师模型较高隐含层和最后一个卷积层特征知识。例如在ResNet网络结构中,可选择将教师模型部分残差块的中间特征知识迁移到学生模型对应位置,帮助学生模型更好地学习图像特征表示,提升模型性能。
- 关系特征知识蒸馏
- 基于FSP矩阵:关系特征指教师模型不同层和不同数据样本之间关系知识。Yim等人提出“Flow of Solution Procedure”(FSP)矩阵,通过模仿教师生成的FSP矩阵指导学生模型训练。FSP矩阵反映教师模型层间关系,学生模型学习该矩阵,可学习到教师模型层间关系知识。例如在一个简单前馈神经网络中,FSP矩阵可表示不同层神经元之间连接权重关系,学生模型通过学习FSP矩阵,优化自身层间连接权重,提高模型性能。
- 探索不同架构网络层的内部关系特征:除FSP矩阵外,还有其他方法探索不同架构网络层内部关系特征,如捕获网络层映射相似性的雅可比矩阵、使用径向基函数计算层间相关性等。这些方法不受师生网络结构限制,可用于不同结构网络间知识蒸馏。例如在一个教师模型为卷积神经网络,学生模型为全连接神经网络的情况下,可通过计算雅可比矩阵来衡量两者层间关系,实现知识迁移,提高学生模型性能。
- 结构特征知识蒸馏
- 结构信息复制:结构特征知识蒸馏通过直接将教师模型结构信息复制到学生模型中,或通过规则、算法将教师模型结构信息转化为学生模型结构信息。例如在设计学生模型时,可参考教师模型网络层数、每层神经元数量、连接方式等结构信息,构建相似结构,使学生模型能更好地学习教师模型知识。
- 提高泛化能力和可解释性:传递结构化知识可提高学生模型泛化能力和可解释性。在图像分类任务中,教师模型学习到不同类别图像之间关系,将这些关系传递给学生模型,可帮助学生模型更好理解不同类别之间区别和联系,提高泛化能力。同时,结构化知识可使学生模型结构更清晰,便于理解模型决策过程,提高可解释性。
(二)基于学习方式的分类
- 离线蒸馏
- 独立训练教师模型:离线蒸馏中,教师模型和学生模型分别独立训练。先在大量数据上训练教师模型,使其达到较高性能。例如在ImageNet图像分类数据集上训练一个大型卷积神经网络作为教师模型,通过多轮训练,使其在验证集上达到较高准确率。
- 学生模型学习教师模型知识:教师模型训练完成后,固定其参数,将其输出(软目标等)作为监督信号,训练学生模型。学生模型通过最小化与教师模型输出差异,学习教师模型知识。例如在训练学生模型时,将教师模型对ImageNet数据集中图像的预测软目标作为学生模型训练目标,使用KL散度等损失函数,调整学生模型参数,使其输出接近教师模型软目标。
- 在线蒸馏
- 同时训练教师与学生模型:在线蒸馏中,教师模型和学生模型同时训练。在训练过程中,教师模型不断更新,其输出实时指导学生模型训练。例如在一个基于循环神经网络的语言模型训练中,教师模型和学生模型同时在文本数据上进行训练,教师模型每更新一次参数,其新的输出结果就用于指导学生模型训练,使学生模型能及时学习到教师模型最新知识。
- 动态知识传递:相比离线蒸馏,在线蒸馏中知识传递更动态,教师模型能根据最新数据学习情况,及时为学生模型提供更准确知识指导,提高学生模型训练效果。例如在视频分类任务中,随着视频数据不断输入,教师模型和学生模型同时学习,教师模型对新视频数据的理解和特征提取方式可实时传递给学生模型,使学生模型能更好地适应视频数据变化,提高分类准确性。
- 自蒸馏
- 同一模型不同阶段知识迁移:自蒸馏是将同一模型不同阶段知识进行迁移。例如在模型训练早期,模型对数据理解较浅,随着训练进行,模型学习到更多知识。可将训练后期模型输出作为软目标,指导训练早期模型学习,提高模型整体性能。例如在一个Transformer模型训练过程中,将训练到第100轮的模型输出作为软目标,指导训练到第50轮的模型继续训练,使模型更快收敛到更好解。
- 增强模型泛化能力:自蒸馏有助于增强模型泛化能力,通过让模型学习自身不同阶段知识,可使模型更好地理解数据分布规律,提高对新数据适应能力。例如在自然语言处理中的文本分类任务中,自蒸馏可使模型更好地捕捉文本语义特征,提高在不同文本数据集上分类准确率。
- 无数据蒸馏
- 在无训练数据下进行蒸馏:无数据蒸馏在没有原始训练数据情况下进行。通常利用教师模型生成伪数据,或基于模型结构和参数信息进行蒸馏。例如在图像分类任务中,可根据教师模型对图像特征理解,生成一些伪图像数据,用这些伪数据训练学生模型,实现知识蒸馏。
- 保护数据隐私和降低数据依赖:无数据蒸馏在保护数据隐私(如原始数据包含敏感信息不能公开使用)和降低数据依赖(如难以获取大量训练数据)场景下具有重要应用价值。例如在医疗图像分析中,原始医疗图像数据涉及患者隐私,使用无数据蒸馏技术,可在不使用真实医疗图像数据情况下,将教师模型知识迁移到学生模型,用于医疗图像辅助诊断。
- 多模型蒸馏
- 多个教师模型知识融合:多模型蒸馏使用多个教师模型,将它们的知识融合传递给学生模型。多个教师模型可从不同角度学习数据知识,其知识互补性强。例如在一个复杂图像分类任务中,使用一个基于卷积神经网络的教师模型和一个基于视觉Transformer的教师模型,两个模型对图像特征提取方式不同,将它们输出的软目标等知识融合后传递给学生模型,可使学生模型学习到更全面图像特征知识,提高分类性能。
- 提高学生模型性能和鲁棒性:通过融合多个教师模型知识,学生模型能学习到更丰富知识,提高性能和鲁棒性。例如在面对不同噪声干扰的图像数据时,经过多模型蒸馏训练的学生模型,相比仅使用单个教师模型训练的学生模型,对噪声更具鲁棒性,能更准确地进行图像分类。
- 特权蒸馏
- 利用额外“特权信息”:特权蒸馏中,教师模型能获取额外“特权信息”,如数据的额外特征、专家标注的辅助信息等,而学生模型无法获取这些信息。教师模型利用这些特权信息学习到更丰富知识,再将知识传递给学生模型。例如在图像分类任务中,教师模型除了使用图像本身像素信息外,还可获取到图像拍摄时间、地点等额外信息,利用这些信息学习到更准确图像分类知识,然后将这些知识蒸馏给学生模型。
- 提升学生模型学习能力:通过特权蒸馏,学生模型能学习到教师模型利用特权信息获得的知识,提升自身学习能力和性能。例如在一个需要对不同场景下物体进行分类的任务中,教师模型利用场景相关特权信息学习到更准确分类知识,学生模型通过特权蒸馏学习这些知识后,在不同场景物体分类任务中的准确率得到提高。
四、挑战与未来方向
4.1 技术挑战
- 异构模型适配瓶颈:师生模型结构差异超过40%时,知识传递效率骤降65%。
- 知识量化困境:如何有效提取模型的"暗知识"仍是难题,剑桥团队提出的认知图谱方法可提升关键知识捕获率至78%。
- 多模态融合难题:跨模态蒸馏需解决模态间语义鸿沟,如视觉与语音特征的对齐问题。
4.2 未来趋势
- 自演进蒸馏系统:借鉴元学习理念,构建能自主优化蒸馏策略的智能框架,缩短训练周期60%。
- 量子-经典混合蒸馏:探索量子计算环境下的知识迁移,利用量子纠缠特性提升蒸馏效率。
- 伦理化蒸馏准则:建立知识溯源机制与隐私保护框架,确保蒸馏过程的可解释性与安全性。
- 多模态大模型蒸馏:将GPT-4等多模态大模型的知识迁移至轻量级模型,推动AI普惠化。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









