






导读
目前RAG是很多AI落地场景的解决方案, 但所谓没有评估就没有优化。本文介绍几种常用的RAG评估框架。阅读本文你将学到:
-
如何使用大模型评估大模型
-
如何使用这些框架
-
框架文档和代码

LlamaIndex 是用于大型语言模型(LLM)应用的开发框架。
它被开发人员广泛使用,用于创建检索增强生成(RAG)应用程序。
在 RAG 应用程序的开发过程中,评估相关数据对于更好地调整和优化应用程序至关重要。
随着 RAG 技术的进步,出现了更有效的评估工具,以促进对 RAG 应用程序的准确和高效评估。
在本文中,我们将介绍一些可以与 LlamaIndex 集成的 RAG 评估工具,并对它们进行比较。
RAG 评估工具是什么?
RAG 评估工具是用于测试和评估基于检索的文本生成系统的方法或框架。
它们评估准确性、内容质量和相关性等指标。
有助于开发人员了解并优化 RAG 应用程序以实现真实世界的使用。与手动评估相比,RAG 评估工具更客观、准确和高效,通过自动化实现大规模评估。
一些应用甚至将这些工具集成到 CI/CD 过程中,以实现自动化评估和优化。
实体术语
RAG 应用通常使用特定术语进行评估。这些术语在不同的评估工具之间可能会有所不同。以下是常见的实体定义:
-
问题:指用户的查询。在一些工具中,它也被称为 输入 或 查询。
-
上下文:指检索到的文档上下文。一些工具称之为 检索上下文。
-
答案:指生成的答案。可能会使用不同的术语,如 实际输出 或 响应。
-
标准答案:指手动标记的正确答案。用于评估生成答案的准确性。
我们将在接下来的工具描述中一贯使用这些术语,以保持清晰并便于比较。
准备工作
测试文档
我们使用漫威电影“复仇者联盟”作为测试文档。这些数据主要来自维基百科关于复仇者联盟的条目,包含了四部复仇者联盟电影的情节信息。
数据集
基于测试文档,我们创建了一个包含“问题”和“真相”的数据集。以下是定义的数据集:
`questions = [ `` "洛基在征服地球的尝试中使用了什么神秘的物体?", `` "复仇者联盟的哪两名成员创造了奥创?", `` "灭霸如何实现了他在宇宙中消灭一半生命的计划?", `` "复仇者联盟用什么方法扭转了灭霸的行动?", ``"复仇者联盟的哪位成员牺牲了自己来打败灭霸?",` `]` ` `` `` ``ground_truth = [ `` "六角宝", `` "托尼·斯塔克(钢铁侠)和布鲁斯·班纳(绿巨人浩克)。", `` "通过使用六颗无限宝石", `` "通过时间旅行收集宝石。", ``"托尼·斯塔克(钢铁侠)",` `]`
检索引擎
接下来,我们将使用LlamaIndex创建一个标准的RAG检索引擎。评估工具将使用此引擎生成Answer和Context:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader` ` `` `` ``documents = SimpleDirectoryReader("./data").load_data()` `vector_index = VectorStoreIndex.from_documents(documents)` `query_engine = vector_index.as_query_engine(similarity_top_k=2)
-
我们从data目录加载文档。
-
使用VectorStoreIndex创建文档向量索引。
-
将文档向量索引转换为查询引擎,并将相似度阈值设置为2。
TruLens
TruLens 是一个旨在评估和改进LLM应用程序的软件工具。
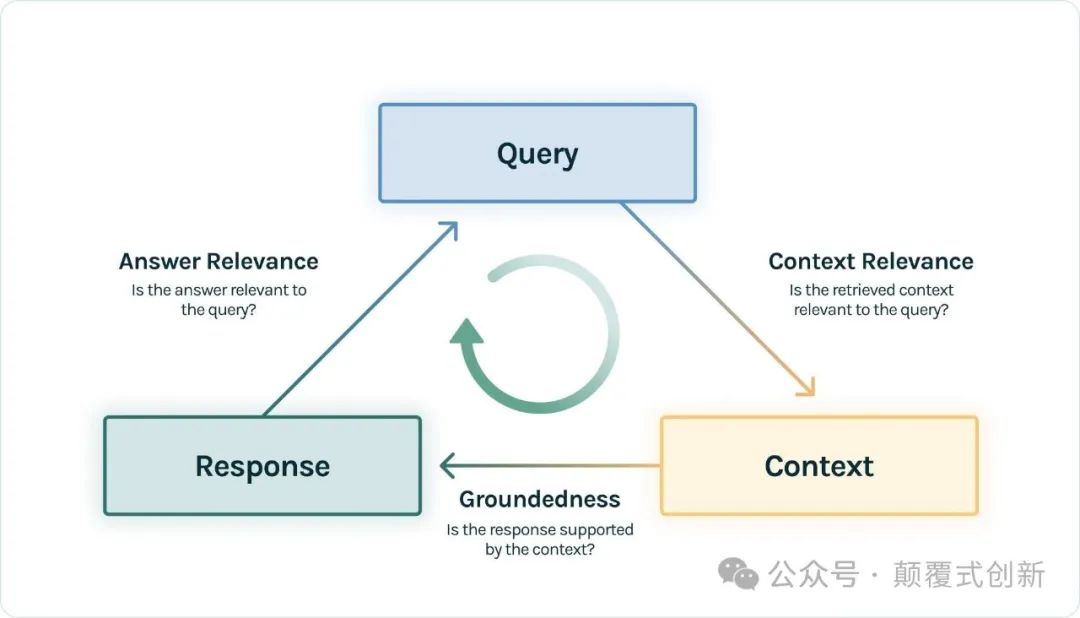
评估指标
TruLens 主要使用以下指标来评估 RAG 应用程序:
-
答案相关性:评估答案对问题的回应情况,确保其有帮助和相关性。
-
上下文相关性:评估上下文对问题的相关性,为LLM答案提供基础。
-
基于事实:检查答案是否与上下文中呈现的事实相一致。
-
基准真相:将答案与手动标记的基准真相进行比较,以确保准确性。
使用示例
以下是一个代码片段,演示如何使用 TruLens 进行 RAG 评估:
`import numpy as np` `from trulens_eval import Tru, Feedback, TruLlama` `from trulens_eval.feedback.provider.openai import OpenAI` `from trulens_eval.feedback import Groundedness, GroundTruthAgreement` ` `` `` ``openai = OpenAI()` `golden_set = [{"query": q, "response": r} for q, r inzip(questions, ground_truth)]` `ground_truth = Feedback( ``GroundTruthAgreement(golden_set).agreement_measure, name="Ground Truth"` `).on_input_output()` `grounded = Groundedness(groundedness_provider=openai)` `groundedness = ( `` Feedback(grounded.groundedness_measure_with_cot_reasons, name="Groundedness") `` .on(TruLlama.select_source_nodes().node.text) `` .on_output() ``.aggregate(grounded.grounded_statements_aggregator)` `)` `qa_relevance = Feedback( ``openai.relevance_with_cot_reasons, name="Answer Relevance"` `).on_input_output()` `qs_relevance = ( `` Feedback(openai.qs_relevance_with_cot_reasons, name="Context Relevance") `` .on_input() `` .on(TruLlama.select_source_nodes().node.text) ``.aggregate(np.mean)` `)` `tru_query_engine_recorder = TruLlama( `` query_engine, `` app_id="Avengers_App", `` feedbacks=[ `` ground_truth, `` groundedness, `` qa_relevance, `` qs_relevance, ``],` `)` `with tru_query_engine_recorder as recording: `` for question in questions: ``query_engine.query(question)` `tru = Tru()` `tru.run_dashboard()`
这段代码片段使用 TruLens 来评估 RAG 应用程序。它定义了诸如 Ground Truth、Groundedness、Answer Relevance 和 Context Relevance 等反馈指标。然后使用 TruLlama 记录查询引擎的结果,并使用 Tru 运行评估以显示结果。
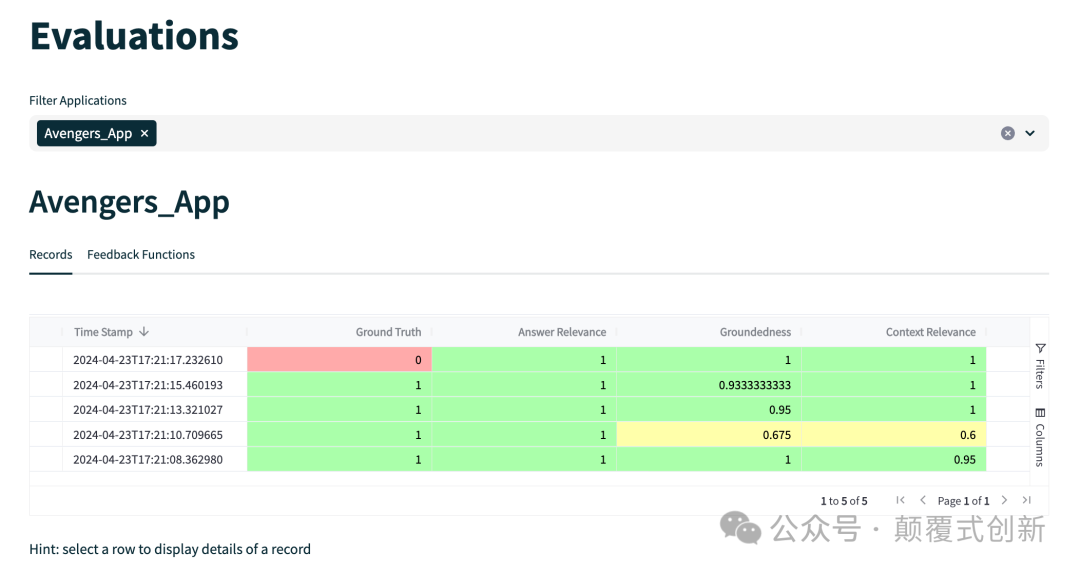
评估结果
TruLens的评估结果可以通过浏览器访问本地服务来查看。评估结果包括总体得分和详细指标。得分背后的原因也是可见的。以下是TruLens评估结果的示例:
Ragas
Ragas 是另一个用于评估RAG应用程序的框架。与TruLens相比,Ragas提供了更详细的指标。
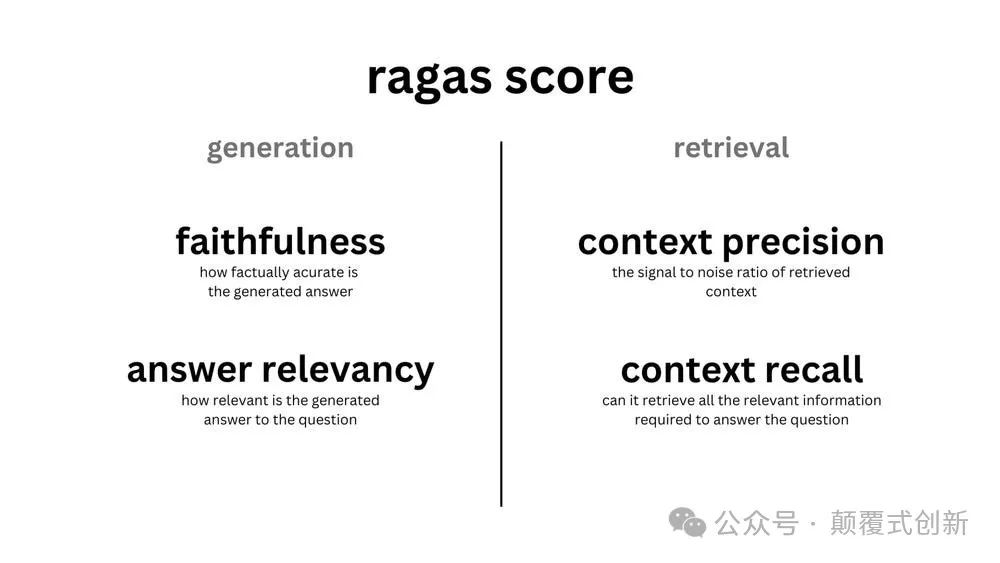
评估指标
Ragas 使用以下指标来评估 RAG 应用程序:
-
忠实度:评估“问题”和“上下文”之间的一致性。
-
答案相关性:评估“答案”和“问题”之间的一致性。
-
上下文精度:检查“基准真相”在“上下文”中是否排名较高。
-
上下文召回:评估“基准真相”和“上下文”之间的一致性。
-
上下文实体召回:评估“基准真相”中的实体与“上下文”之间的一致性。
-
上下文相关性:评估“问题”和“上下文”之间的一致性。
-
答案语义相似性:评估“答案”和“基准真相”之间的语义相似性。
-
答案正确性:评估“答案”相对于“基准真相”的正确性。
-
方面评论:包括对其他方面的评估,如有害性、正确性等。
使用示例
官方 Ragas 文档提供了与 LlamaIndex 集成的示例,但代码已过时。以下是更新后的示例:
from ragas.metrics import ( `` faithfulness, `` answer_relevancy, `` context_relevancy, ``answer_correctness,` `)` `from ragas import evaluate` `from datasets import Dataset` ` `` `` ``metrics = [ `` faithfulness, `` answer_relevancy, `` context_relevancy, ``answer_correctness,` `]` `answers = []` `contexts = []` `for q in questions: `` response = query_engine.query(q) `` answers.append(response.response) ``contexts.append([sn.get_content() for sn in response.source_nodes])` `data = { `` "question": questions, `` "contexts": contexts, `` "answer": answers, ``"ground_truth": ground_truth,` `}` `dataset = Dataset.from_dict(data)` `result = evaluate(dataset, metrics)` `result.to_pandas().to_csv("output/ragas-evaluate.csv", sep=",")
在这个示例中
-
使用 questions 和 ground_truth 作为输入数据。
-
使用类似于 TruLens 中使用的指标。
-
手动构建数据集,添加问题、答案和上下文。
-
将评估结果保存到本地文件。
评估结果
Ragas的评估结果可以在本地文件中查看。结果包含每个评估指标的分数。以下是Ragas评估结果的示例:
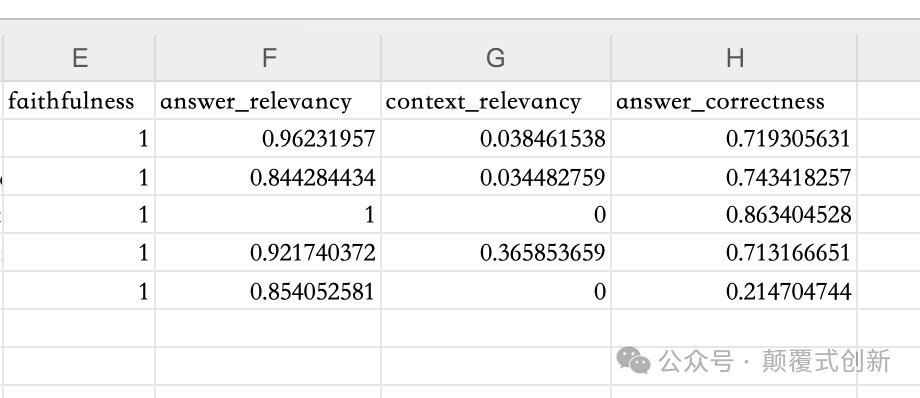
Ragas和TruLens的评估结果显示出相当大的差异,特别是在上下文相关性指标上,得分明显较低。
事实上,在评估上下文时,Ragas建议将上下文精度和上下文召回作为主要指标。然而,为了与TruLens进行比较,我们使用了上下文相关性。
在Ragas的评估结果中,我们只看到分数,没有任何解释分数背后的原因。
DeepEval
DeepEval 是一个开源的LLM评估框架,允许像单元测试一样运行评估任务。
评估指标
DeepEval 使用以下评估指标,其中一些设计用于 RAG 应用程序,另一些用于其他 LLM 使用:
-
忠实度:评估问题和上下文之间的一致性。
-
答案相关性:评估答案和问题之间的一致性。
-
上下文精确性:检查真相在上下文中的排名是否较高。
-
上下文召回:评估真相和上下文之间的一致性。
-
上下文相关性:评估问题和上下文之间的一致性。
-
幻觉:衡量幻觉程度。
-
偏见:评估偏见水平。
-
毒性:衡量毒性的存在,包括人身攻击、讽刺或威胁。
-
Ragas:允许使用 Ragas 进行评估和生成解释。
-
知识保留:评估信息的持久性。
-
摘要:评估摘要的有效性。
-
G-Eval:G-Eval 是使用大型语言模型(LLM)和思维链(CoT)执行评估任务的框架。它可以根据任何自定义标准评估 LLM 输出。有关更多信息,请查阅此论文。
用法示例
DeepEval 可以运行像单元测试这样的评估任务。这里有一个简单的例子:
`import pytest` `from deepeval.metrics import ( `` AnswerRelevancyMetric, `` FaithfulnessMetric, ``ContextualRelevancyMetric,` `)` `from deepeval.test_case import LLMTestCase` `from deepeval import assert_test` `from deepeval.dataset import EvaluationDataset` ` `` `` ``def generate_dataset(): `` test_cases = [] `` for i inrange(len(questions)): `` response = query_engine.query(questions[i]) `` test_case = LLMTestCase( `` input=questions[i], `` actual_output=response.response, `` retrieval_context=[node.get_content() for node in response.source_nodes], `` expected_output=ground_truth[i], `` ) `` test_cases.append(test_case) ``return EvaluationDataset(test_cases=test_cases)` ` `` `` ``dataset = generate_dataset()` ` `` `` ``@pytest.mark.parametrize( `` "test_case", ``dataset,` `)` `def test_rag(test_case: LLMTestCase): `` answer_relevancy_metric = AnswerRelevancyMetric(model="gpt-3.5-turbo") `` faithfulness_metric = FaithfulnessMetric(model="gpt-3.5-turbo") `` context_relevancy_metric = ContextualRelevancyMetric(model="gpt-3.5-turbo") `` assert_test( `` test_case, `` [answer_relevancy_metric, faithfulness_metric, context_relevancy_metric], ``)`
在这个例子中:
构建一个包含问题、生成的答案、上下文和真相的测试数据集。
使用像 Faithfulness、Answer Relevance 和 Context Relevance 这样的度量标准。
DeepEval 默认使用 gpt-4,但为了成本效益,您可以指定其他模型,比如 gpt-3.5-turbo。
评估度量标准的阈值默认设置为 0.5,表示低于此值的分数表示测试失败。
运行测试文件 deepeval test run test_deepeval.py 来执行评估任务。DeepEval 会在终端输出评估结果。如果测试通过,您将看到 PASSED;如果没有,将看到 FAILED。
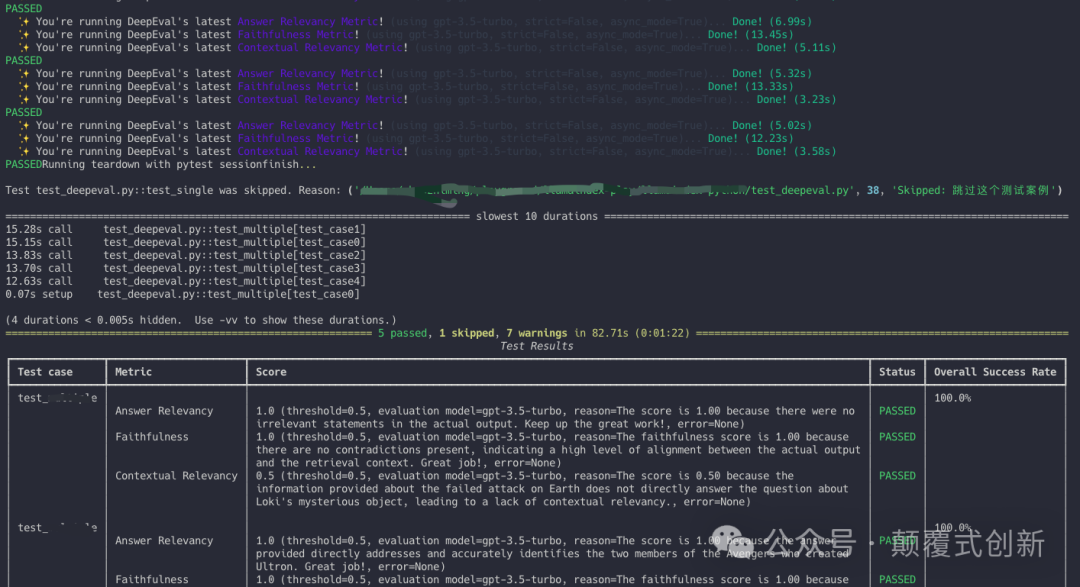
评估结果
虽然终端结果可能不方便查看,但DeepEval提供了访问评估结果的替代方式。您可以通过设置环境变量 export DEEPEVAL_RESULTS_FOLDER=“./output” 将它们保存到本地JSON文件中。
这将结果保存在指定的文件夹中。
查看结果的另一种方式是通过Confident平台。使用您的API密钥登录,使用 deepeval login --confident-api-key your_api_key,然后运行测试。
结果会自动上传到Confident平台,使其更容易查看。以下是Confident上的评估结果的屏幕截图:
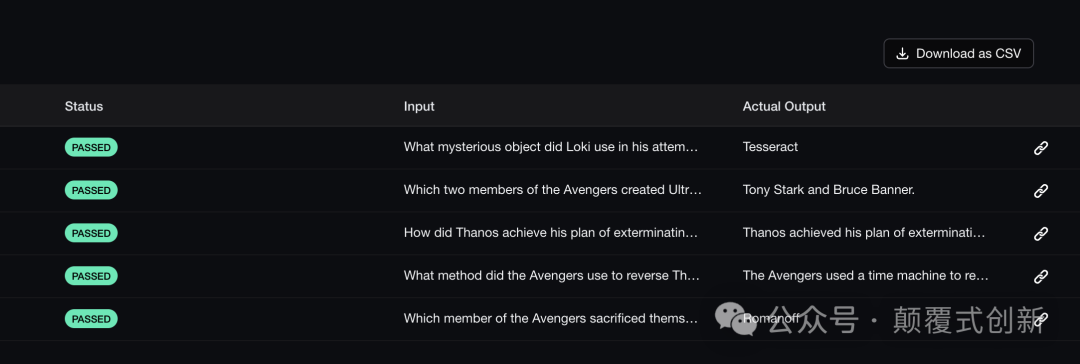
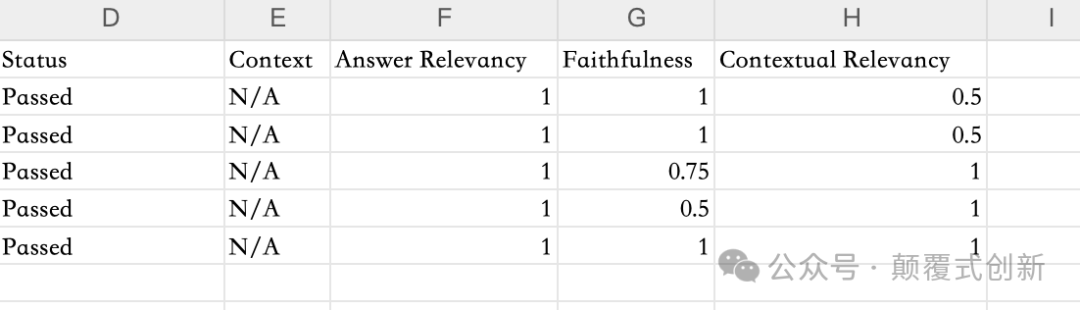
Confident还允许您将结果导出为CSV文件以供本地查看:
UpTrain
UpTrain 是一个用于评估和改进LLM应用程序的开源平台。它在这里讨论的工具中拥有最广泛的评估指标集。

评估指标
UpTrain的评估指标适用于RAG应用程序和其他LLM应用程序。以下是一些指标:
-
响应匹配:评估答案和真相之间的一致性。
-
响应完整性:衡量答案是否涵盖了问题的所有方面。
-
响应简洁性:检查答案是否包含无关内容。
-
响应相关性:评估答案和问题之间的相关性。
-
响应有效性:评估答案是否有效,避免类似于“我不知道”的回答。
-
响应一致性:评估答案,问题和上下文之间的一致性。
-
上下文相关性:衡量上下文和问题之间的相关性。
-
上下文利用:评估答案是否利用上下文来涵盖所有要点。
-
事实准确性:检查答案是否在事实上准确,并是否源自上下文。
-
上下文简洁性:衡量上下文是否简洁,避免无关信息。
-
上下文重新排序:评估重新排序后的上下文的有效性。
-
越狱检测:评估问题是否包含越狱线索。
-
提示注入:衡量问题是否可能导致泄露系统提示。
-
语言特征:评估答案是否简洁、连贯,并且没有语法错误。
-
语调:检查答案是否符合特定语调。
-
子查询完整性:评估子问题是否涵盖了问题的所有方面。
-
多查询准确性:评估问题的变体是否与原始问题一致。
-
代码幻觉:评估答案中的代码是否与上下文相关。
-
用户满意度:评估用户在对话中的满意度。
使用示例
UpTrain 与 LlamaIndex 集成,允许您使用 EvalLlamaIndex 创建评估对象。以下是一个示例:
`import os` `import json` `from uptrain import EvalLlamaIndex, Evals, ResponseMatching, Settings` ` `` `` ``settings = Settings( ``openai_api_key=os.getenv("OPENAI_API_KEY"),` `)` `data = []` `for i inrange(len(questions)): `` data.append( `` { `` "question": questions[i], `` "ground_truth": ground_truth[i], `` } ``)` `llamaindex_object = EvalLlamaIndex(settings=settings, query_engine=query_engine)` `results = llamaindex_object.evaluate( `` data=data, `` checks=[ `` ResponseMatching(), `` Evals.CONTEXT_RELEVANCE, `` Evals.FACTUAL_ACCURACY, `` Evals.RESPONSE_RELEVANCE, ``],` `)` `withopen("output/uptrain-evaluate.json", "w") as json_file: ``json.dump(results, json_file, indent=2)`
在这个例子中,我们:
-
使用 OpenAI 的 API 密钥进行 UpTrain。
-
初始数据集只需要 Question 和 Ground Truth。Answer 和 Context 是由 EvalLlamaIndex 生成的。
-
包括常见的评估指标。
-
将结果保存在一个 JSON 文件中。
评估结果
评估结果存储在 JSON 文件中。为了更容易比较,将结果转换为 CSV 格式。以下是 UpTrain 的评估结果:

在 UpTrain 的评估结果中,Response Matching 分数有时可能看起来不准确。运行 Response Matching 后,您可能会得到三个分数:score_response_match、score_response_match_recall 和 score_response_match_precision。
即使 Answer 和 Ground Truth 看起来相似,这些分数可能为 0。目前尚不清楚为什么会发生这种情况;如果您知道,请在下方评论。
比较分析
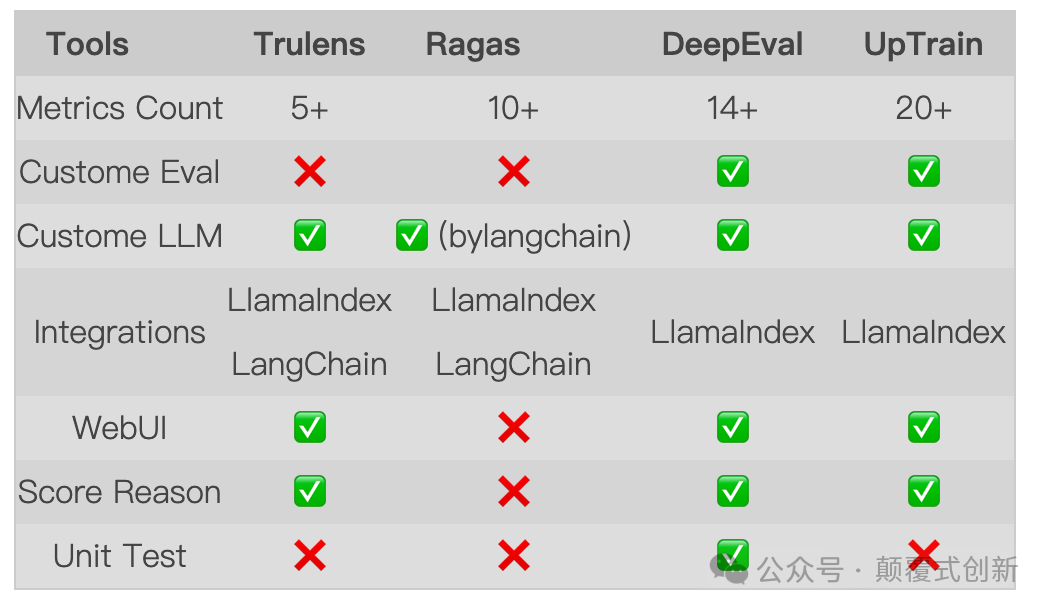
-
评估指标:TruLens 的指标较少,而 DeepEval 和 UpTrain 拥有广泛的指标。Ragas 的指标数量适中,涵盖了 RAG 应用的所有关键方面。
-
自定义评估:DeepEval 和 UpTrain 支持自定义指标,而 TruLens 和 Ragas 不支持。
-
自定义LLMs:大多数工具支持自定义LLMs。Ragas 通过 LangChain 实现此功能。
-
框架集成:大多数工具支持与 LlamaIndex 和 LangChain 的集成,但 DeepEval 和 UpTrain 仅支持与 LlamaIndex 的集成。
-
WebUI:基于Web的界面可以更轻松地查看结果。TruLens、DeepEval 和 UpTrain 支持此功能;Ragas 不支持,尽管您可以使用第三方工具来查看结果。
-
分数解释:除 Ragas 外,所有工具都提供分数解释。DeepEval 可帮助 Ragas 生成这些解释。
-
单元测试:DeepEval 提供类似单元测试的评估任务,这在这些工具中是独特的。
TruLens 和 Ragas 是最早的 RAG 评估工具之一,而 DeepEval 和 UpTrain 则是后来出现的。这些更新的工具可能受到早期工具的启发,从而拥有更全面的指标和改进的功能。然而,TruLens 和 Ragas 仍然具有独特的优势,例如 TruLens 直观的结果和 Ragas 为 RAG 应用量身定制的指标。
结论
本文讨论了与 LlamaIndex 集成的各种 RAG 评估工具,并比较了它们的特性。这些工具帮助开发人员更好地理解和优化 RAG 应用程序。还有其他未在此提及的工具,比如 LlamaIndex 的内置评估工具和 Tonic Validate。如果您不确定选择哪种评估工具,请从一个项目开始使用它。如果不符合您的需求,请尝试另一个。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。
本文转自 https://blog.csdn.net/m0_59164304/article/details/140070905?spm=1001.2014.3001.5501,如有侵权,请联系删除。















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









